Parafraseando:
Parece que lo que le gustaría es algún tipo de sistema en el que pueda haber dos (o más) subprocesos en funcionamiento. Un subproceso estaría ocupado obteniendo sincrónicamente los datos de la base de datos e informando su progreso al resto del programa. El otro hilo se ocuparía de la pantalla.
No está claro si su consulta devolverá 500 000 filas (de hecho, esperemos que no lo haga), aunque es posible que deba escanear las 500 000 filas (y es posible que solo haya encontrado 23 filas que coincidan hasta el momento). Determinar el número de filas a devolver es difícil; determinar el número de filas a escanear es más fácil; determinar el número de filas ya escaneadas es muy difícil.
Entonces, el usuario se desplazó más allá de la fila 23, pero la consulta aún no se completó.
Hay un par de problemas aquí. El DBMS (el caso de la mayoría de las bases de datos, y ciertamente del IDS) permanece atado hasta la conexión actual al procesar la instrucción. Es difícil obtener comentarios sobre el progreso de una consulta. Podría mirar las filas estimadas devueltas cuando se inició la consulta (información en la estructura SQLCA), pero esos valores pueden ser incorrectos. Tendría que decidir qué hacer cuando llegue a la fila 200 de 23, o solo llegue a la fila 23 de 5697. Es mejor que nada, pero no es fiable. Determinar hasta dónde ha progresado una consulta es muy difícil. Y algunas consultas requieren una operación de clasificación real, lo que significa que es muy difícil predecir cuánto tiempo tomará porque no hay datos disponibles hasta que se realiza la clasificación (y una vez que se realiza la clasificación, solo existe el tiempo necesario para comunicarse entre el DBMS y la aplicación para retrasar la entrega de los datos).
Informix 4GL tiene muchas virtudes, pero la compatibilidad con subprocesos no es una de ellas. El lenguaje no se diseñó teniendo en cuenta la seguridad de los subprocesos y no existe una manera sencilla de adaptarlo al producto.
Creo que lo que está buscando sería respaldado más fácilmente por dos hilos. En un programa de subproceso único como un programa I4GL, no hay una manera fácil de salir y buscar filas mientras espera que el usuario escriba más información (como "desplazarse hacia abajo en la siguiente página llena de datos"). /P>
La optimización de las PRIMERAS FILAS es una pista para el DBMS; puede o no dar un beneficio significativo al desempeño percibido. En general, normalmente significa que la consulta se procesa de manera menos óptima desde la perspectiva del DBMS, pero obtener resultados rápidamente para el usuario puede ser más importante que la carga de trabajo en el DBMS.
En algún lugar de abajo, en una respuesta muy votada negativamente, Frank gritó (pero, por favor, no GRITE):
ESTÁ BIEN. La dificultad aquí es organizar el IPC entre los dos procesos del lado del cliente. Si ambos están conectados al DBMS, tienen conexiones separadas y, por lo tanto, las tablas temporales y los cursores de una sesión no están disponibles para la otra.
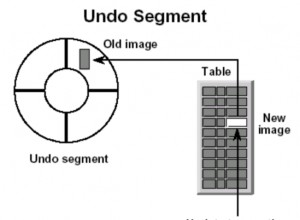
No todas las consultas dan como resultado una tabla temporal, aunque el conjunto de resultados de un cursor de desplazamiento suele tener algo aproximadamente equivalente a una tabla temporal. IDS no necesita colocar un candado en la tabla temporal que respalda un cursor de desplazamiento porque solo IDS puede acceder a la tabla. Si fuera una tabla temporal normal, aún no sería necesario bloquearla porque no se puede acceder a ella excepto por la sesión que la creó.
Quizás un mensaje de estado más preciso sería:
Searching 500,000 rows...found 23 matching rows so far
Probablemente; también puede obtener un conteo rápido y preciso con 'SELECT COUNT(*) FROM TheTable'; esto no escanea nada sino que simplemente accede a los datos de control, probablemente los mismos datos que en la columna nrows de la tabla SMI sysmaster:sysactptnhdr.
Entonces, generar un nuevo proceso no es claramente una receta para el éxito; debe transferir los resultados de la consulta del proceso generado al proceso original. Como dije, una solución de subprocesos múltiples con subprocesos de visualización y acceso a la base de datos separados funcionaría de alguna manera, pero hay problemas al hacer esto usando I4GL porque no reconoce subprocesos. Todavía tendría que decidir cómo el código del lado del cliente almacenará la información para mostrarla.