Creo que tienes algunos términos mezclados aquí.
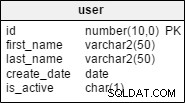
Todos sus datos van a una base de datos (también conocida como esquema). En una base de datos puede tener tablas.
por ejemplo
table employee
id integer
name varchar
address varchar
country varchar
table office
id integer
employee_id integer
address varchar
Dentro de las tablas tienes campos (id, name, address) también conocido como columnas. Y las tablas tienen una o más filas.
Un ejemplo para empleado de mesa:
id name address country
----------------------------------------------------
1 John 1 Regent Street UK
2 James 24 Jump Street China
3 Darth Vader 1 Death Star Bestine, Tatooine
Tanto para lo básico.
Por qué particionar
Ahora suponga que tenemos montones y montones de personas (filas) en nuestra base de datos.
Recuerde que esta es una base de datos galáctica, por lo que tenemos 100 mil millones de registros.
Si queremos buscar tan rápido es bueno si podemos hacer esto en paralelo.
Así que dividimos la tabla (por ejemplo, por país) y luego podemos tener x servidores buscando en 1 país cada uno.
La partición entre servidores se llama sharding .
O podemos particionar, p. datos históricos por año, por lo que no tenemos que pasar por todos los datos solo para obtener los recientes noticias. Solo tenemos que pasar por la partición de este año. Esto se llama partitioning .
¿Cuál es la gran diferencia entre sharding puede simplemente partitioning ?
fragmentación
En sharding anticipas que todas sus datos son relevantes e igualmente probables de ser consultados. (por ejemplo, Google puede esperar que se consulten todos sus datos; archivar parte de sus datos es inútil para ellos).
En este caso, desea que muchas máquinas revisen sus datos en paralelo, donde cada máquina hace parte de la trabajo.
Así que le da a cada máquina una partición diferente (fragmento) de los datos y le da a todas las máquinas la misma consulta. Cuando salgan los resultados, UNION todos juntos y mostrar el resultado.
Particionamiento básico
En el partitioning básico parte de sus datos es hot y parte es not . Un caso típico son los datos históricos, los nuevos datos son hot , los datos antiguos apenas se tocan.
Para este caso de uso, no tiene sentido colocar los datos antiguos en servidores separados. Esas máquinas simplemente esperarán y esperarán y no harán nada porque a nadie le importan los datos antiguos excepto algunos auditores que los revisan una vez al año.
Así que divide esos datos por año y el servidor archivará automáticamente las particiones antiguas para que su las consultas solo analizarán un (quizás 2) años de datos y serán mucho más rápidas.
¿Necesito particionar?
Solo crea particiones cuando tiene muchísimos datos, porque complica su configuración.
A menos que tenga más de un millón de registros, no tiene que considerar la creación de particiones.
Si tiene más de 100 millones de registros, definitivamente debería considerarlo.
Para obtener más información, consulte:http://dev.mysql.com/ doc/refman/5.1/en/particionamiento.html
y:http://blog.mayflower.de/archives/353-Is-MySQL-partitioning-useful-for-very-big-real-life-problems.html
Ver también wiki:http://en.wikipedia.org/wiki /Partición_%28base de datos%29
Estas son solo mis heurísticas personales YMMV.