select
p.ID,
e.NAME
from
Paychecks p
inner join Employee e on p.EmployeeID = e.ID
group by
p.ID
order by
max(p.AmountPaid) desc
Una forma diferente de escribir, que parece más lógica, pero puede ser más lenta (tendrías que probarla) es:
select
e.ID,
e.NAME
from
Employee e
inner join Paychecks p on p.EmployeeID = e.ID
group by
e.ID
order by
max(p.AmountPaid) desc
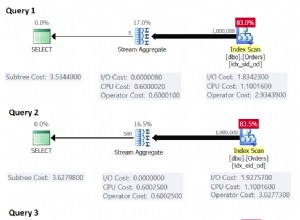
Con decenas de millones de filas, cada consulta crece lentamente a veces, pero con los índices adecuados, esto es lo más rápido posible. Creo que básicamente necesita un índice en Paychecks.EmployeeID y Paychecks.AmountPaid combinados. Y el índice en Employee.ID puede ayudar.
Si la combinación lo está matando al final, puede ejecutar dos consultas. El primero solo usa los cheques de pago para agruparlos por EmployeeID y ordenarlos por el máximo (PaycheckAmount), y el segundo se puede usar para obtener los nombres de cada ID. A veces, las uniones cuestan más rendimiento de lo que le gustaría, y cuando obtuvo 10 millones de cheques de pago para 500 empleados, puede ser más rápido hacerlo en dos pasos, aunque significará que han estado trabajando en la empresa durante aproximadamente 1600 años en promedio. .;-)