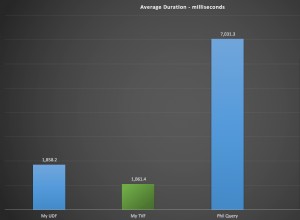
Aquí está la versión SQLAlchemy de su secuencia de comandos MySQL que funciona en cuatro segundos, en comparación con los tres de MySQLdb:
from sqlalchemy import Integer, Column, create_engine, MetaData, Table
import datetime
metadata = MetaData()
foo = Table(
'foo', metadata,
Column('id', Integer, primary_key=True),
Column('a', Integer(), nullable=False),
Column('b', Integer(), nullable=False),
Column('c', Integer(), nullable=False),
)
class Foo(object):
def __init__(self, a, b, c):
self.a = a
self.b = b
self.c = c
engine = create_engine('mysql+mysqldb://scott:[email protected]/test', echo=True)
start = datetime.datetime.now()
with engine.connect() as conn:
foos = [
Foo(row['a'], row['b'], row['c'])
for row in
conn.execute(foo.select().limit(1000000)).fetchall()
]
print "total time: ", datetime.datetime.now() - start
tiempo de ejecución:
total time: 0:00:04.706010
Aquí hay una secuencia de comandos que usa el ORM para cargar filas de objetos por completo; al evitar la creación de una lista fija con todos los objetos de 1M a la vez usando el rendimiento por, esto se ejecuta en 13 segundos con maestro SQLAlchemy (18 segundos con rel 0.9):
import time
from sqlalchemy import Integer, Column, create_engine, Table
from sqlalchemy.orm import Session
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Foo(Base):
__table__ = Table(
'foo', Base.metadata,
Column('id', Integer, primary_key=True),
Column('a', Integer(), nullable=False),
Column('b', Integer(), nullable=False),
Column('c', Integer(), nullable=False),
)
engine = create_engine('mysql+mysqldb://scott:[email protected]/test', echo=True)
sess = Session(engine)
now = time.time()
# avoid using all() so that we don't have the overhead of building
# a large list of full objects in memory
for obj in sess.query(Foo).yield_per(100).limit(1000000):
pass
print("Total time: %d" % (time.time() - now))
Luego podemos dividir la diferencia entre estos dos enfoques y cargar solo columnas individuales con el ORM:
for obj in sess.query(Foo.id, Foo.a, Foo.b, Foo.c).yield_per(100).limit(1000000):
pass
Lo anterior vuelve a ejecutarse en 4 segundos .
La comparación de SQLAlchemy Core es la comparación más adecuada con un cursor MySQLdb sin formato. Si usa el ORM pero consulta columnas individuales, son aproximadamente cuatro segundos en las versiones más recientes.
A nivel de ORM, los problemas de velocidad se deben a que la creación de objetos en Python es lenta, y SQLAlchemy ORM aplica una gran cantidad de contabilidad a estos objetos a medida que los obtiene, lo cual es necesario para cumplir con su contrato de uso, incluida la unidad. de obra, mapa de identidad, carga ansiosa, cobros, etc.
Para acelerar drásticamente la consulta, busque columnas individuales en lugar de objetos completos. Consulte las técnicas en http://docs .sqlalchemy.org/en/latest/faq/performance.html#result-fetching-slowness-orm que describen esto.
Para su comparación con PeeWee, PW es un sistema mucho más simple con muchas menos funciones, incluido que no hace nada con los mapas de identidad. Incluso con PeeWee, un ORM tan simple como sea factible, aún toma 15 segundos , lo cual es evidencia de que cPython es realmente muy lento en comparación con la recuperación de MySQLdb sin procesar que está en C.
En comparación con Java, Java VM es mucho, mucho más rápido que cPython . Hibernate es ridículamente complicado, sin embargo, la VM de Java es extremadamente rápida debido al JIT e incluso toda esa complejidad termina ejecutándose más rápido. Si desea comparar Python con Java, use Pypy.