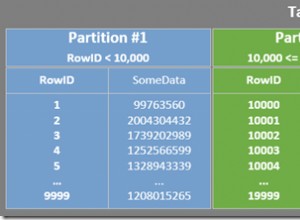
El enfoque es tener una consulta anidada que tenga una línea por duplicado y una consulta externa que devuelva solo el recuento de los resultados de la consulta interna.
SELECT count(*) AS duplicate_count
FROM (
SELECT name FROM tbl
GROUP BY name HAVING COUNT(name) > 1
) AS t