Usar el clúster de Galera es una excelente manera de crear un entorno de alta disponibilidad para MySQL o MariaDB. Es un entorno de clúster sin nada compartido que se puede escalar incluso más allá de 12 a 15 nodos. Sin embargo, Galera tiene algunas limitaciones. Destaca en entornos de baja latencia y, aunque se puede utilizar en WAN, el rendimiento está limitado por la latencia de la red. El rendimiento de Galera también puede verse afectado si uno de los nodos comienza a comportarse incorrectamente. Por ejemplo, una carga excesiva en uno de los nodos puede ralentizarlo, lo que resulta en un manejo más lento de las escrituras y eso afectará a todos los demás nodos del clúster. Por otro lado, es bastante imposible administrar un negocio sin analizar sus datos. Dicho análisis, por lo general, requiere la ejecución de consultas pesadas, lo cual es bastante diferente de una carga de trabajo de OLTP. En esta publicación de blog, analizaremos una manera fácil de ejecutar consultas analíticas para datos almacenados en Galera Cluster para MySQL o MariaDB, de manera que no afecte el rendimiento del clúster principal.
¿Cómo ejecutar consultas analíticas en Galera Cluster?
Como dijimos, ejecutar consultas de ejecución prolongada directamente en un clúster de Galera es factible, pero tal vez no sea una buena idea. Dependiendo del hardware, esta puede ser una solución aceptable (si usa un hardware fuerte y no ejecutará una carga de trabajo analítica de subprocesos múltiples), pero incluso si la utilización de la CPU no será un problema, el hecho de que uno de los nodos tendrá una carga de trabajo mixta ( OLTP y OLAP) plantearán por sí solos algunos desafíos de rendimiento. Las consultas OLAP expulsarán los datos necesarios para su carga de trabajo OLTP del grupo de búfer, y esto ralentizará sus consultas OLTP. Afortunadamente, existe una manera simple pero eficiente de separar la carga de trabajo analítica de las consultas regulares:un esclavo de replicación asincrónica.
El esclavo de replicación es una solución muy simple:todo lo que necesita es solo otro host que se puede aprovisionar y la replicación asíncrona debe configurarse desde Galera Cluster a ese nodo. Con la replicación asíncrona, el esclavo no afectará al resto del clúster de ninguna manera. No importa si está muy cargado, usa hardware diferente (menos potente), simplemente continuará replicando desde el clúster central. El peor de los casos es que el esclavo de replicación comience a retrasarse, pero luego depende de usted implementar la replicación de subprocesos múltiples o, eventualmente, escalar el esclavo de replicación.
Una vez que el esclavo de replicación esté en funcionamiento, debe ejecutar las consultas más pesadas y descargar el clúster de Galera. Esto se puede hacer de varias maneras, dependiendo de su configuración y entorno. Si usa ProxySQL, puede dirigir consultas fácilmente al esclavo analítico en función del host de origen, el usuario, el esquema o incluso la consulta misma. De lo contrario, dependerá de su aplicación enviar consultas analíticas al host correcto.
Configurar un esclavo de replicación no es muy complejo, pero aún puede ser complicado si no domina MySQL y herramientas como xtrabackup. Todo el proceso consistiría en configurar el repositorio en un nuevo servidor e instalar la base de datos MySQL. Luego, deberá aprovisionar ese host utilizando datos del clúster de Galera. Puede usar xtrabackup para eso, pero otras herramientas como mydumper/myloader o incluso mysqldump también funcionarán (siempre que las ejecute correctamente). Una vez que los datos estén allí, deberá configurar la replicación entre un nodo Galera maestro y el esclavo de replicación. Finalmente, tendría que reconfigurar su capa de proxy para incluir el nuevo esclavo y enrutar el tráfico hacia él o hacer ajustes en cómo su aplicación se conecta a la base de datos para redirigir parte de la carga al esclavo de replicación.
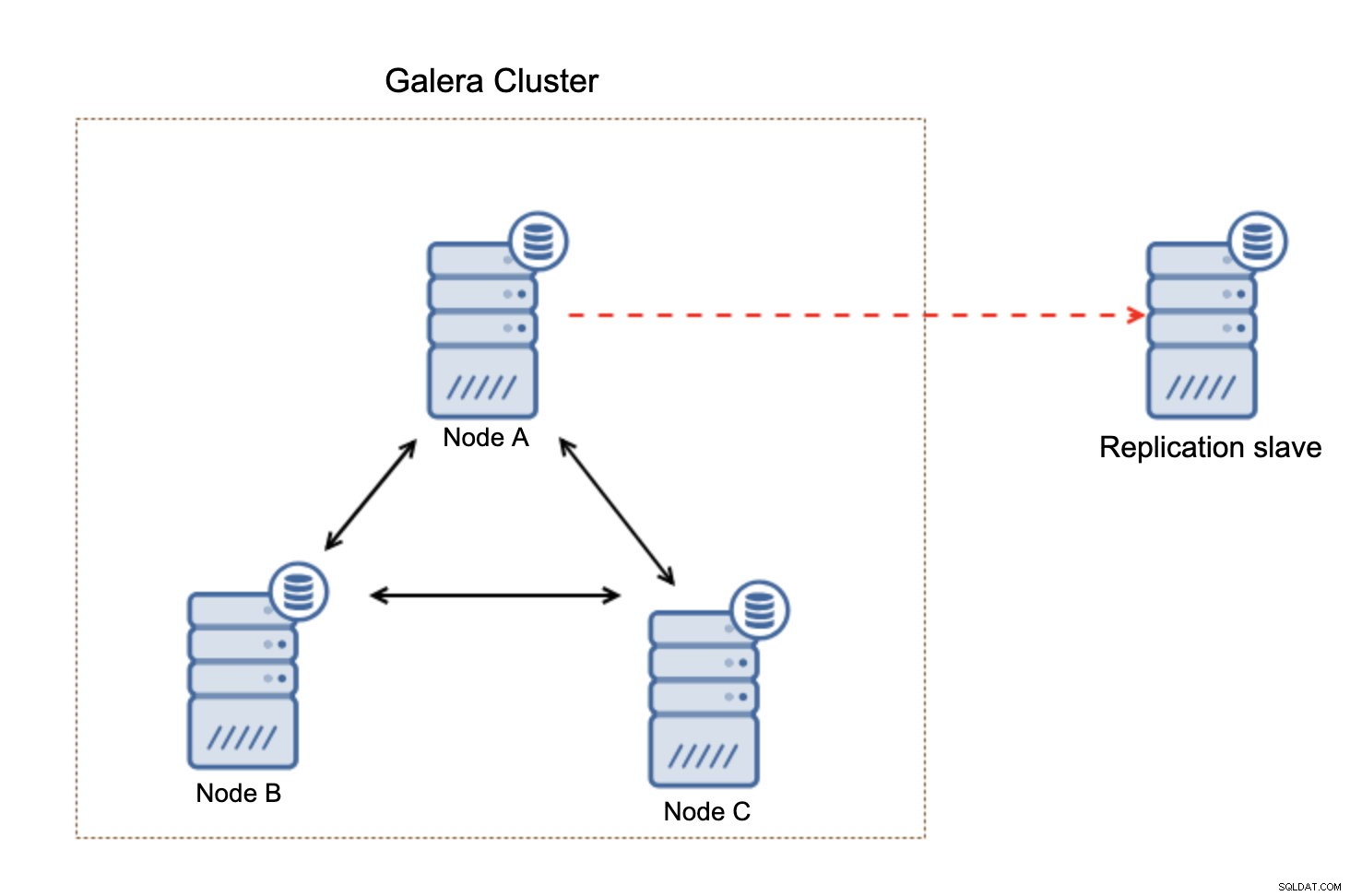
Lo que es importante tener en cuenta es que esta configuración no es resistente. Si el nodo "maestro" de Galera falla, el enlace de replicación se romperá y tomará una acción manual para esclavizar la réplica de otro nodo maestro en el clúster de Galera.
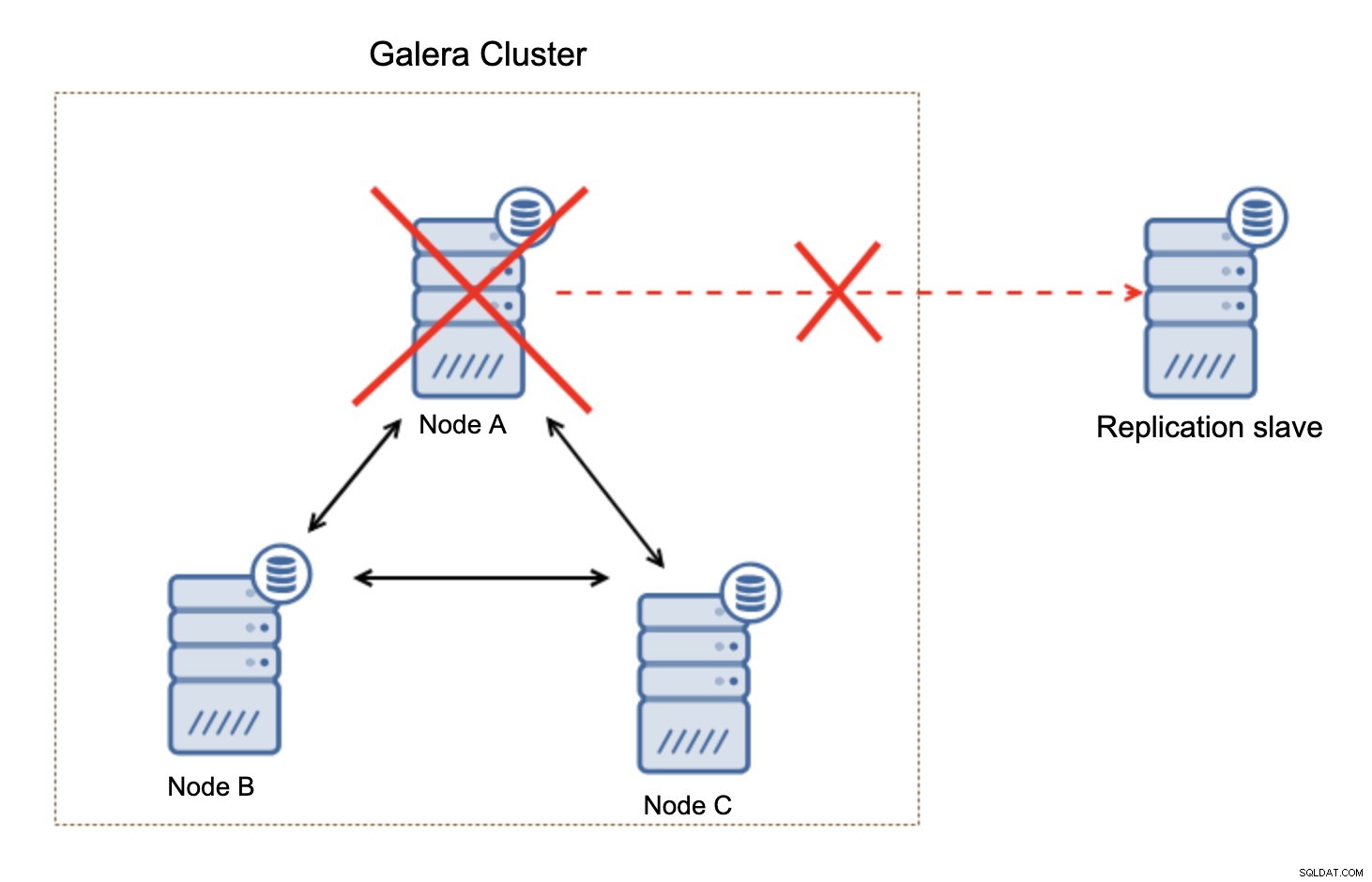
Esto no es un gran problema, especialmente si usa la replicación con GTID (ID de transacción global), pero debe identificar que la replicación está interrumpida y luego realizar la acción manual.
¿Cómo configurar el esclavo asíncrono de Galera Cluster usando ClusterControl?
Afortunadamente, si usa ClusterControl, todo el proceso puede automatizarse y solo requiere unos pocos clics. El estado inicial ya se configuró mediante ClusterControl:un clúster Galera de 3 nodos con 2 nodos ProxySQL y 2 nodos Keepalived para una alta disponibilidad tanto de la base de datos como de la capa de proxy.
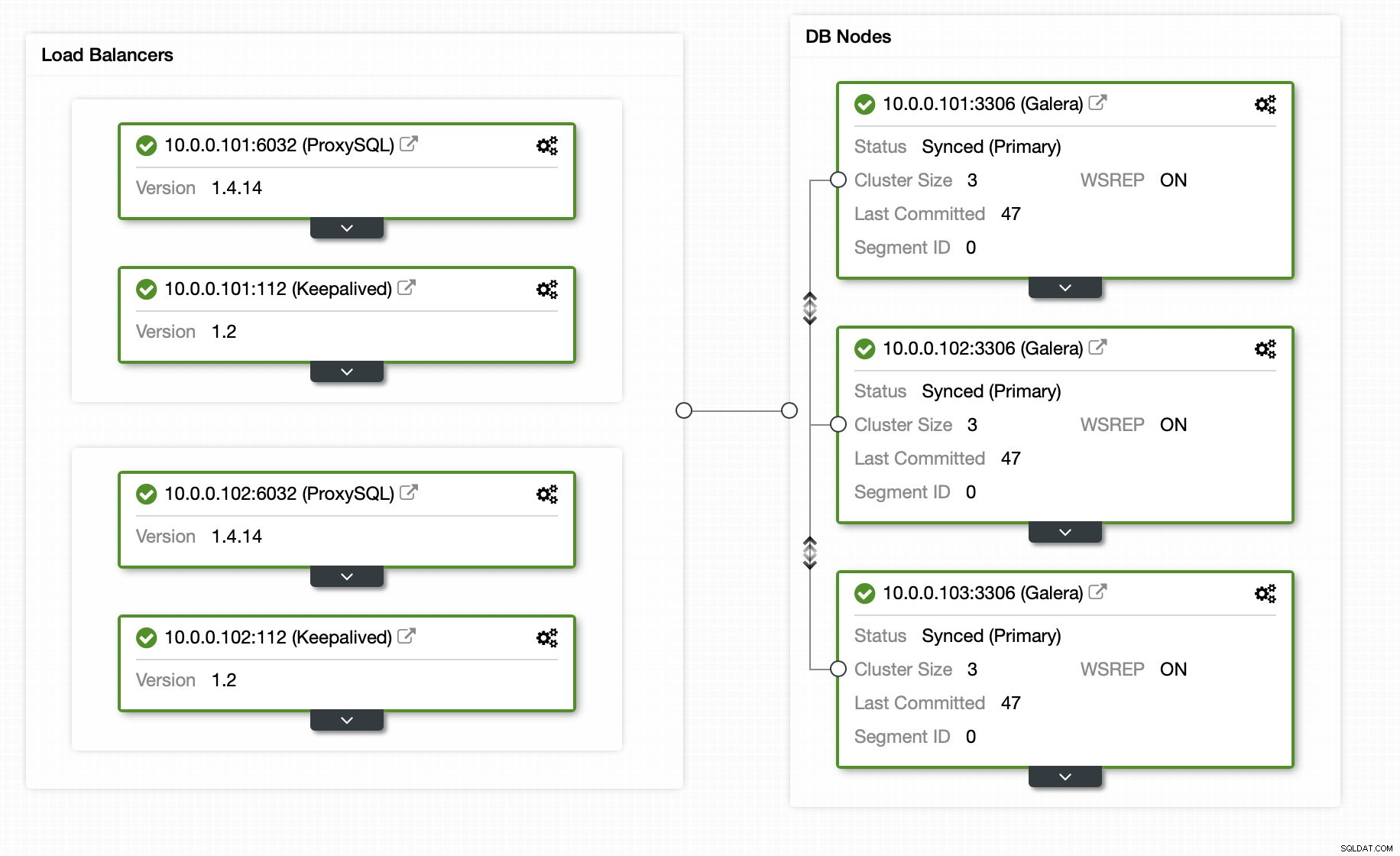
Agregar el esclavo de replicación está a solo un clic de distancia:
La replicación, obviamente, requiere que los registros binarios estén habilitados. Si no tiene binlogs habilitados en sus nodos de Galera, también puede hacerlo desde el ClusterControl. Tenga en cuenta que para habilitar los registros binarios será necesario reiniciar el nodo para aplicar los cambios de configuración.
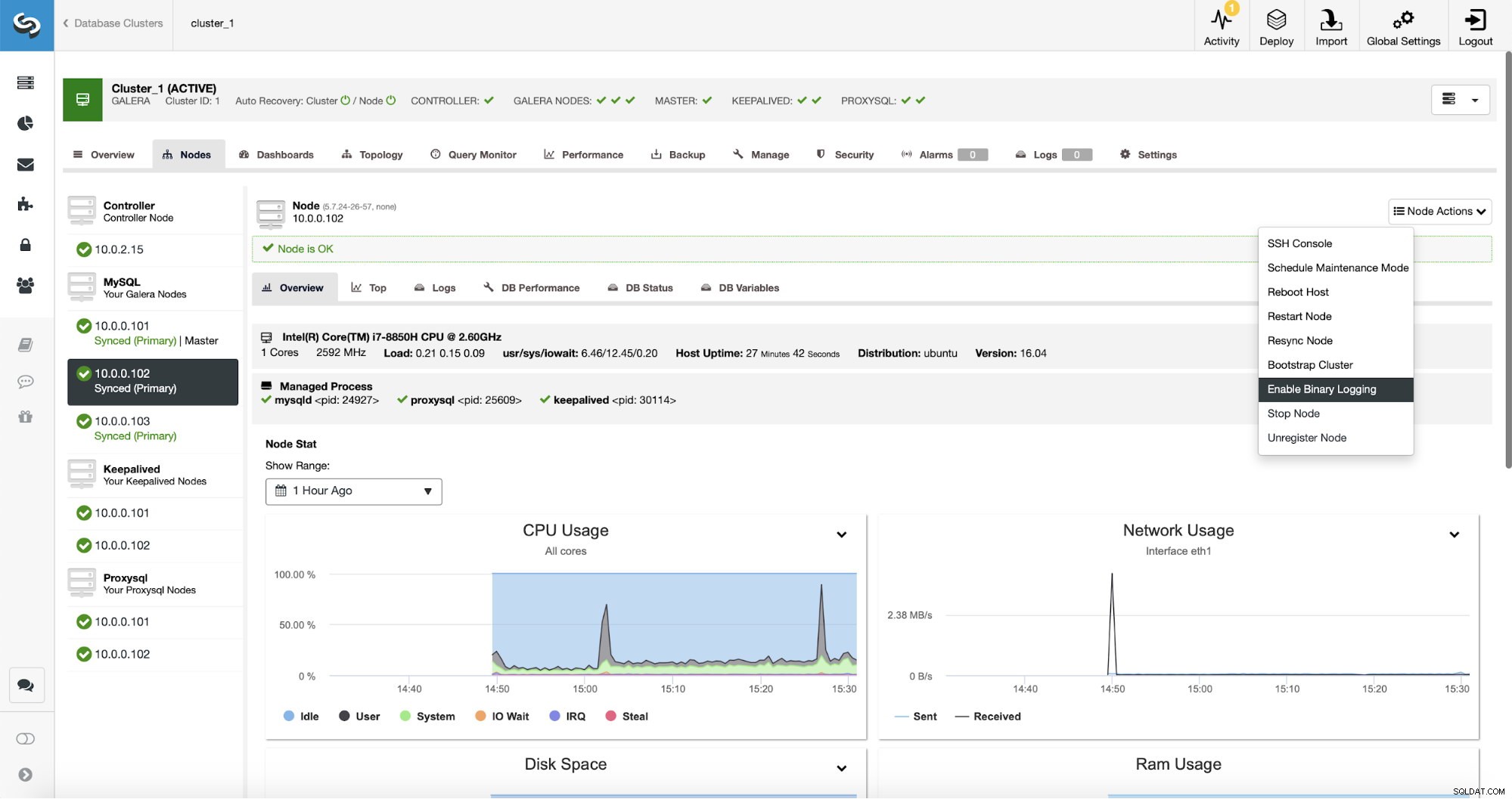
Incluso si un nodo en el clúster tiene registros binarios habilitados (marcados como "Maestro" en la captura de pantalla anterior), aún es bueno habilitar el registro binario en al menos un nodo más. ClusterControl puede conmutar por error automáticamente el esclavo de replicación después de que detecta que el nodo principal de Galera falló, pero para eso, se requiere otro nodo principal con registros binarios habilitados o no tendrá nada a lo que conmutar por error.
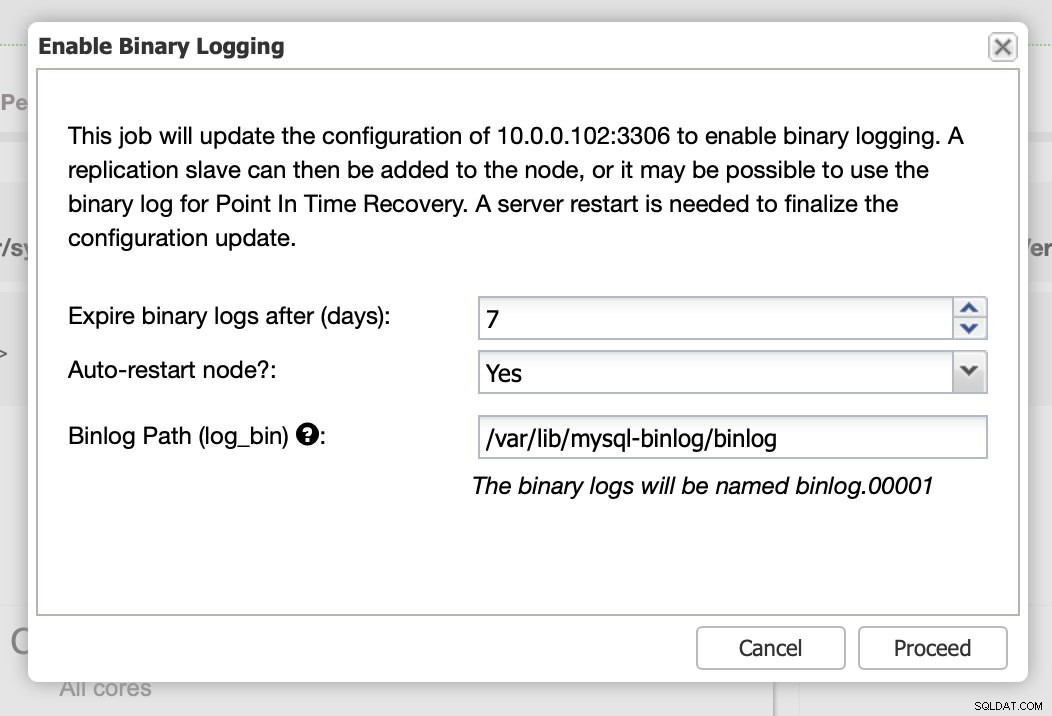
Como dijimos, habilitar los registros binarios requiere reiniciar. Puede realizarlo de inmediato o simplemente realizar los cambios de configuración y realizar el reinicio en otro momento.
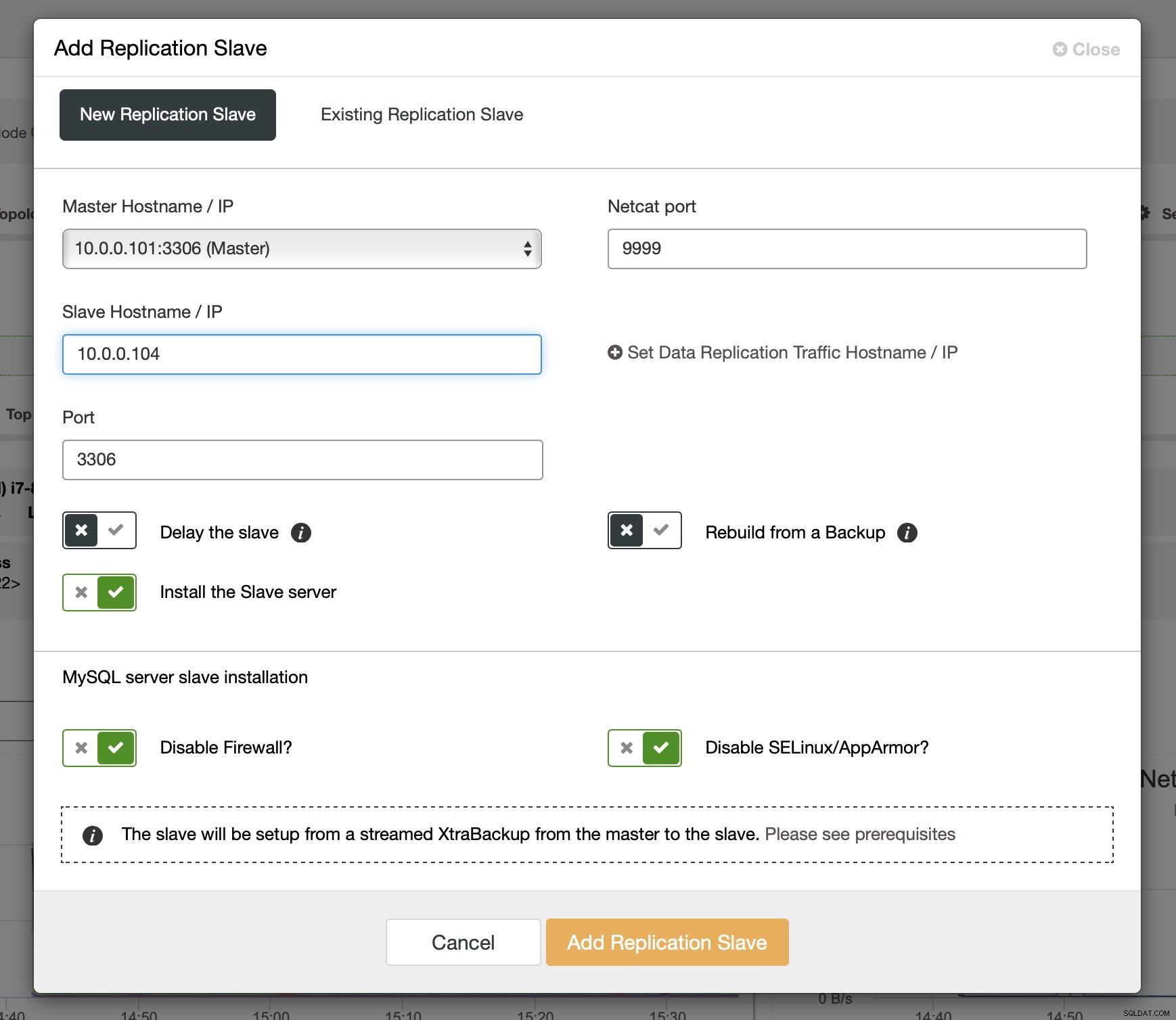
Después de habilitar binlogs en algunos de los nodos de Galera, puede continuar agregando el esclavo de replicación. En el cuadro de diálogo, debe elegir el host maestro, pasar el nombre de host o la dirección IP del esclavo. Si tiene copias de seguridad recientes a mano (que debería hacer), puede usar una para aprovisionar el esclavo. De lo contrario, ClusterControl lo aprovisionará utilizando xtrabackup:todos los datos maestros recientes se transmitirán al esclavo y luego se configurará la replicación.
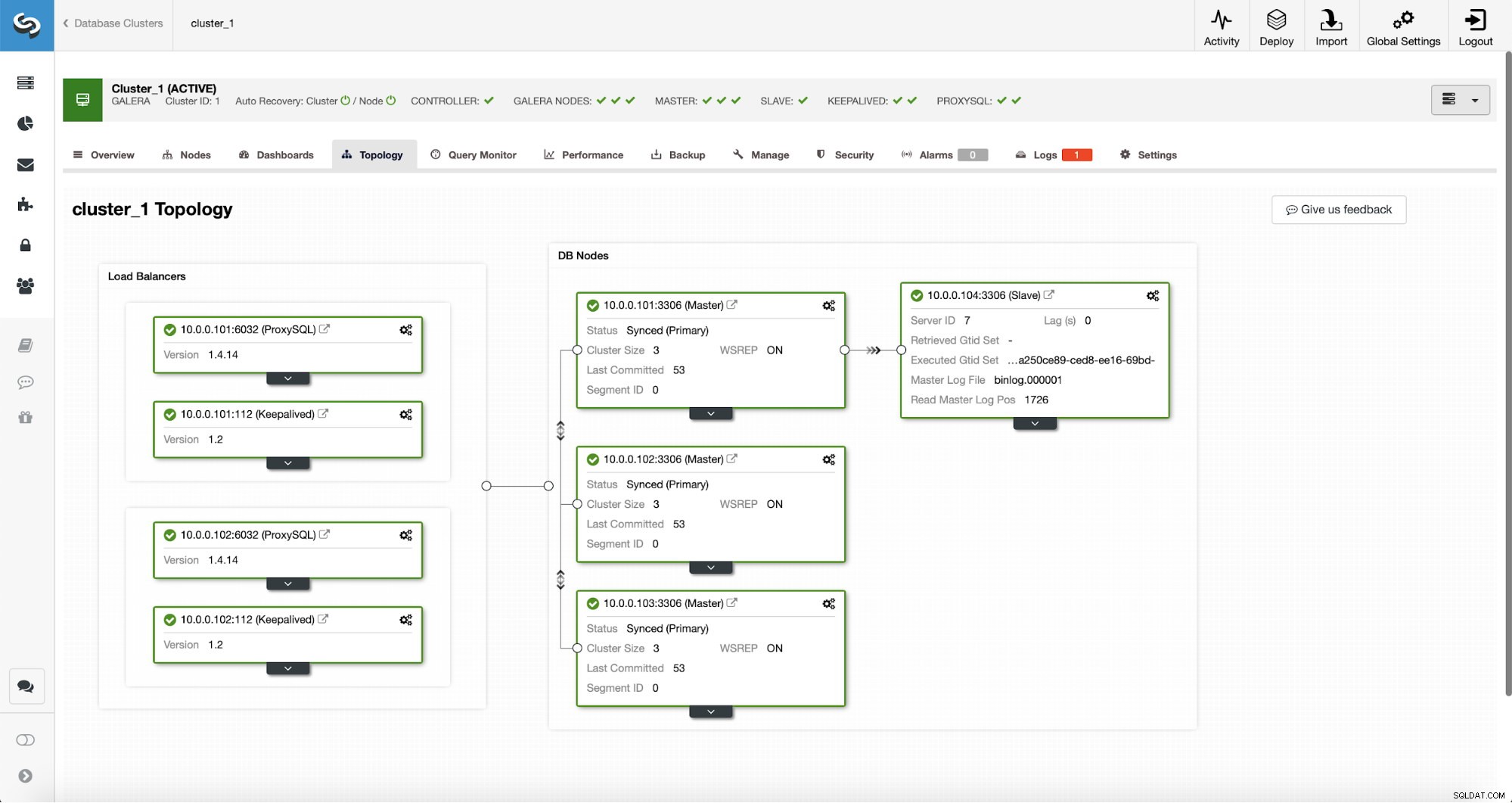
Una vez completado el trabajo, se agregó un esclavo de replicación al clúster. Como se indicó anteriormente, si 10.0.0.101 muere, otro host en el clúster de Galera se elegirá como maestro y ClusterControl automáticamente subordinará 10.0.0.104 a otro nodo.
Como usamos ProxySQL, necesitamos configurarlo. Agregaremos un nuevo servidor a ProxySQL.
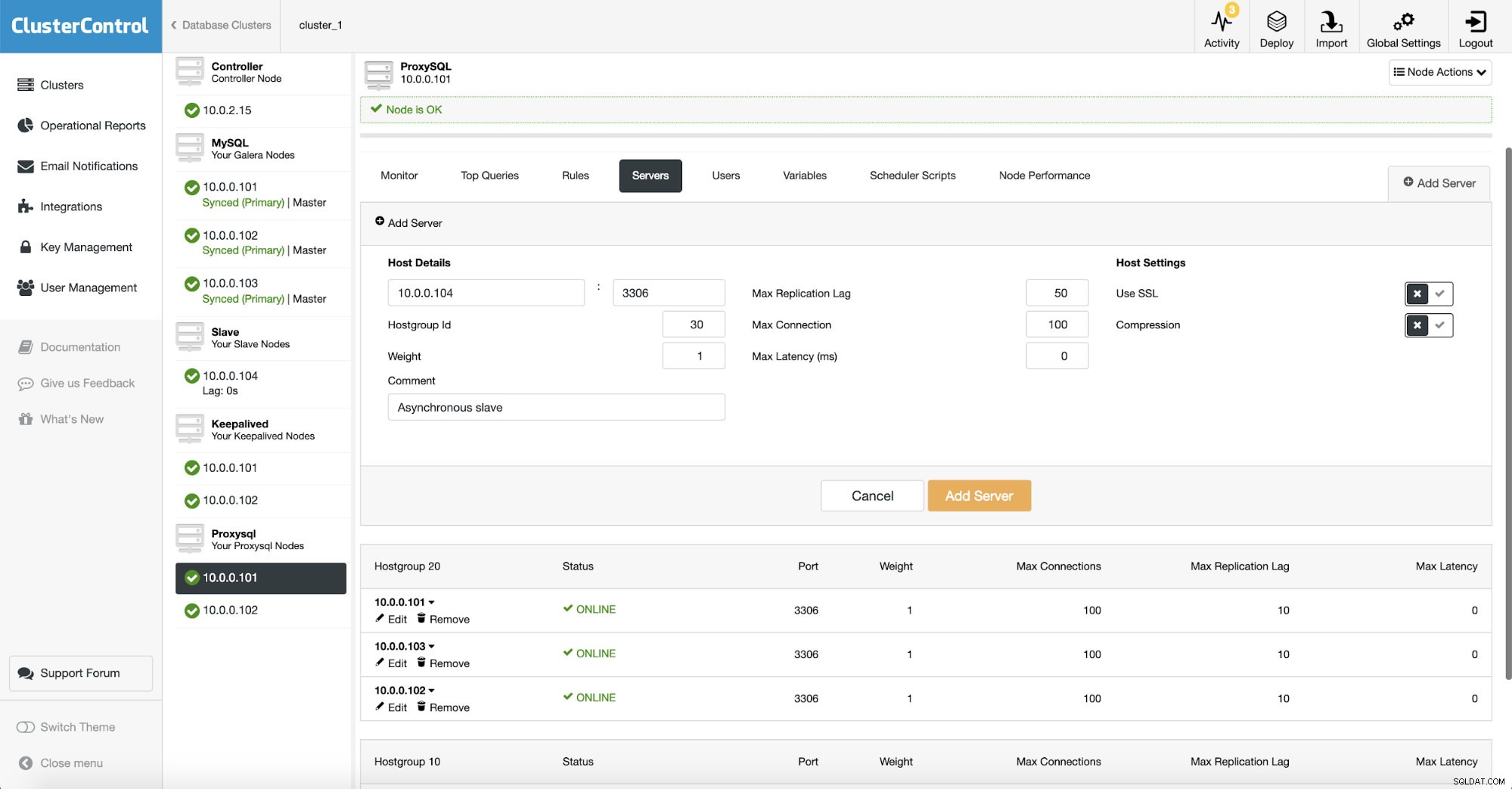
Creamos otro hostgroup (30) donde colocamos nuestro esclavo asíncrono. También aumentamos el "Retraso máximo de replicación" a 50 segundos de los 10 predeterminados. Depende de los requisitos de su negocio qué tan mal se puede retrasar el esclavo de análisis antes de que se convierta en un problema.
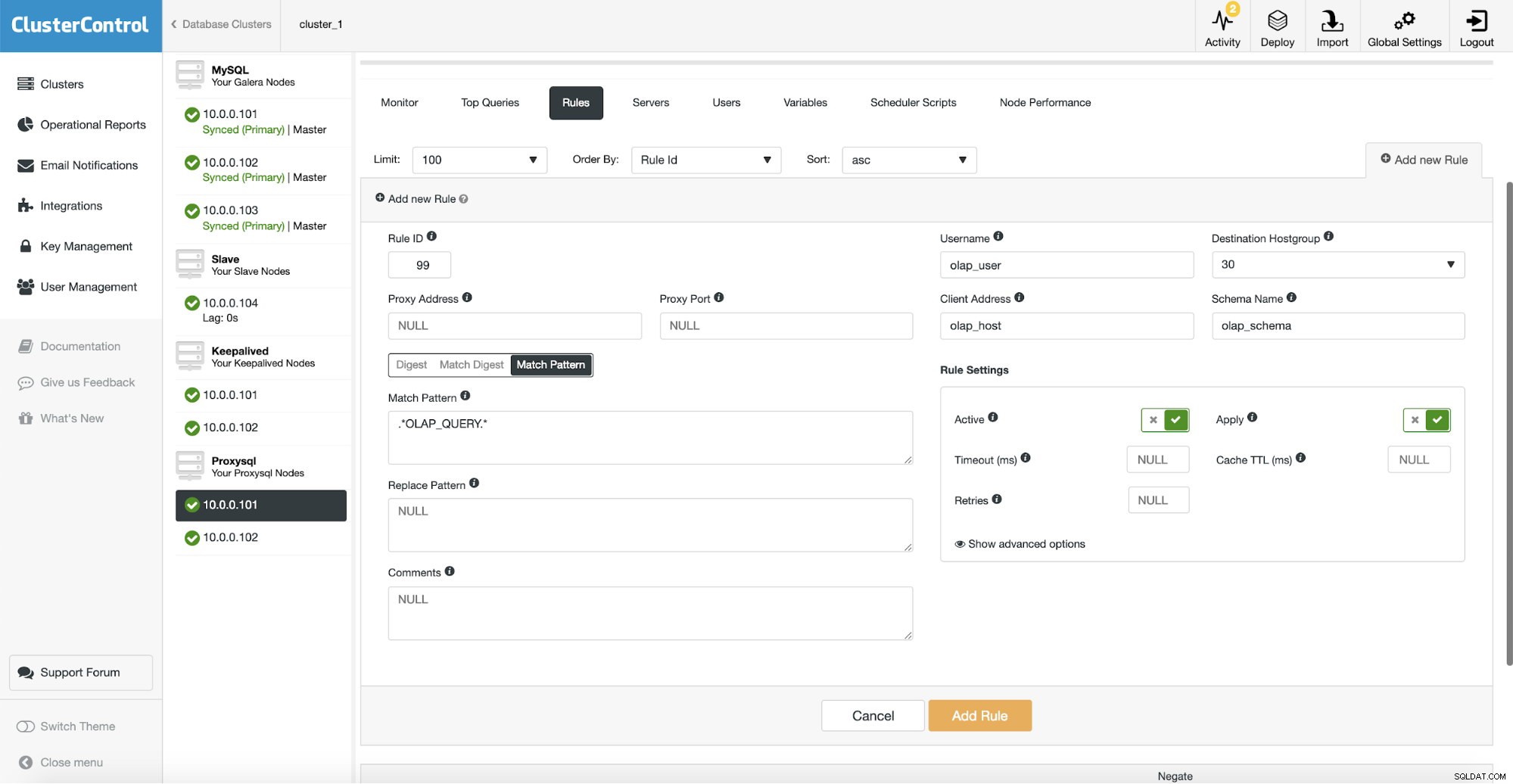
Después de eso, tenemos que configurar una regla de consulta que coincidirá con nuestro tráfico OLAP y lo enrutará al grupo de host OLAP (30). En la captura de pantalla anterior, completamos varios campos; esto no es obligatorio. Por lo general, necesitará usar uno, dos como máximo. La captura de pantalla anterior sirve como ejemplo para que podamos ver fácilmente que puede hacer coincidir las consultas usando el esquema (si tiene un esquema separado con datos analíticos), nombre de host/IP (si las consultas OLAP se ejecutan desde algún host en particular), usuario (si la aplicación usa usuario particular para consultas analíticas. También puede hacer coincidir las consultas directamente pasando una consulta completa o marcándolas con comentarios SQL y dejando que ProxySQL enrute todas las consultas con una cadena "OLAP_QUERY" a nuestro grupo de host analítico.
Como puede ver, gracias a ClusterControl pudimos implementar un esclavo de replicación en Galera Cluster con solo un par de clics. Algunos pueden argumentar que MySQL no es la base de datos más adecuada para la carga de trabajo analítico y tendemos a estar de acuerdo. Puede ampliar fácilmente esta configuración utilizando ClickHouse y configurando una replicación de un esclavo asíncrono a un almacén de datos en columnas de ClickHouse para un rendimiento mucho mejor de las consultas analíticas. Describimos esta configuración en una de las publicaciones anteriores del blog.