Los balanceadores de carga son un componente esencial en la alta disponibilidad de la base de datos; especialmente al hacer que los cambios de topología sean transparentes para las aplicaciones e implementar la funcionalidad de división de lectura y escritura. ClusterControl proporciona una variedad de funciones para implementar, monitorear y configurar de manera segura las tecnologías de equilibrio de carga de código abierto líderes en la industria.
El año pasado agregamos soporte para ProxySQL y agregamos múltiples mejoras para HAProxy y Maxscale de MariaDB. Continuamos esta tradición con la última versión de ClusterControl 1.5.
Según los comentarios que recibimos de nuestros usuarios, hemos mejorado la forma en que se administra ProxySQL. También agregamos compatibilidad con HAProxy y Keepalived para que se ejecuten sobre los clústeres de PostgreSQL.
En esta entrada de blog, echaremos un vistazo a estas mejoras...
ProxySQL:mejoras en la gestión de usuarios
Anteriormente, la interfaz de usuario solo le permitía crear un nuevo usuario o agregar uno existente, uno a la vez. Uno de los comentarios que recibimos de nuestros usuarios fue que es bastante difícil administrar una gran cantidad de usuarios. Escuchamos y en ClusterControl 1.5, ahora es posible importar grandes lotes de usuarios. Echemos un vistazo a cómo puedes hacer eso. En primer lugar, debe tener su ProxySQL implementado. Luego, vaya al nodo ProxySQL y, en la pestaña Usuarios, debería ver el botón "Importar usuarios".

Una vez que haga clic en él, se abrirá un nuevo cuadro de diálogo:

Aquí puede ver todos los usuarios que ClusterControl detectó en su clúster. Puede desplazarse por ellos y elegir los que desea importar. También puede seleccionar o anular la selección de todos los usuarios de una vista actual.

Una vez que comience a escribir en el cuadro de búsqueda, ClusterControl filtrará los resultados que no coincidan, reduciendo la lista solo a los usuarios relevantes para su búsqueda.
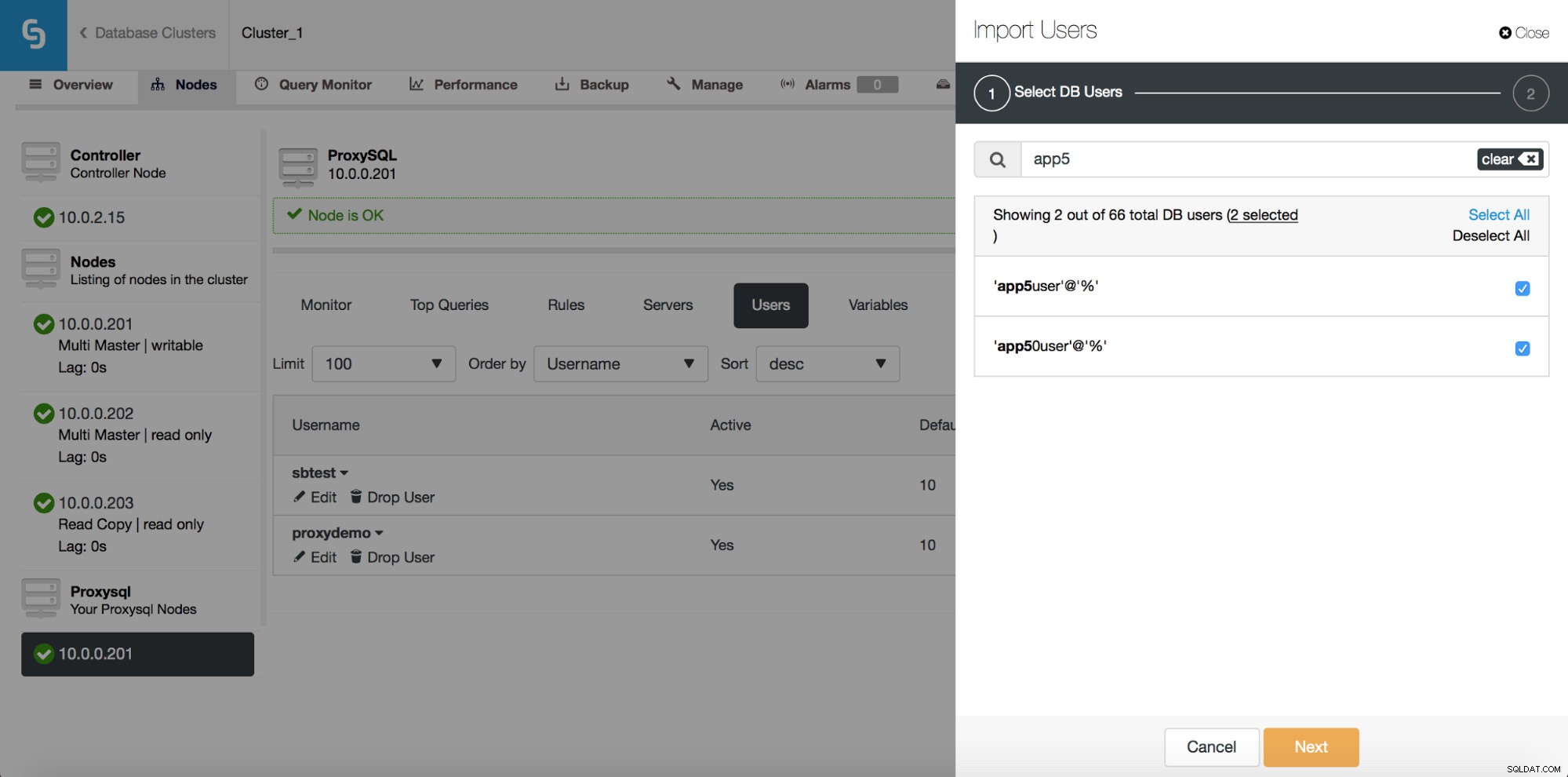
Puede utilizar el botón "Seleccionar todo" para seleccionar todos los usuarios que coincidan con su búsqueda. Por supuesto, después de seleccionar los usuarios que desea importar, puede borrar el cuadro de búsqueda y comenzar otra búsqueda:

Tenga en cuenta "(7 seleccionados)":le dice cuántos usuarios, en total (no solo de esta búsqueda), ha seleccionado para importar. También puede hacer clic en él para ver solo los usuarios que seleccionó para importar.

Una vez que esté satisfecho con su elección, puede hacer clic en "Siguiente" para ir a la siguiente pantalla.

Aquí debe decidir cuál debería ser el grupo de host predeterminado para cada usuario. Puede hacerlo por usuario o globalmente, para el conjunto completo o un subconjunto de usuarios resultantes de una búsqueda.

Una vez que haga clic en el botón "Importar usuarios", los usuarios se importarán y aparecerán en la pestaña Usuarios.
ProxySQL - Gestión del programador
El planificador de ProxySQL es un módulo similar a un cron que permite a ProxySQL iniciar scripts externos en un intervalo regular. El cronograma puede ser bastante granular:hasta una ejecución cada milisegundo. Por lo general, el programador se usa para ejecutar secuencias de comandos de verificación de Galera (como proxysql_galera_checker.sh), pero también se puede usar para ejecutar cualquier otra secuencia de comandos que desee. En el pasado, ClusterControl usaba el programador para implementar el script de comprobación de Galera, pero esto no estaba expuesto en la interfaz de usuario. A partir de ClusterControl 1.5, ahora tiene el control total.

Como puede ver, se programó una secuencia de comandos para ejecutarse cada 2 segundos (2000 milisegundos):esta es la configuración predeterminada para el clúster de Galera.

La captura de pantalla anterior nos muestra opciones para editar entradas existentes. Tenga en cuenta que ProxySQL admite hasta 5 argumentos para los scripts que ejecutará a través del programador.

Si desea que se agregue un nuevo script al programador, puede hacer clic en el botón "Agregar nuevo script" y se le presentará una pantalla como la anterior. También puede obtener una vista previa de cómo se verá el script completo cuando se ejecute. Después de haber llenado todos los campos de "Argumento" y definido el intervalo, puede hacer clic en el botón "Agregar nuevo script".

Como resultado, se agregará una secuencia de comandos al programador y estará visible en la lista de secuencias de comandos programadas.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoPostgreSQL:construcción de la pila de alta disponibilidad
La configuración de la replicación con conmutación por error automática es buena, pero las aplicaciones necesitan una forma sencilla de realizar un seguimiento del maestro grabable. Así que agregamos soporte para HAProxy y Keepalived además de los clústeres de PostgreSQL. Esto permite a nuestros usuarios de PostgreSQL implementar una pila completa de alta disponibilidad mediante ClusterControl.

Desde la subpestaña Load Balancer, ahora puede implementar HAProxy; si está familiarizado con la forma en que ClusterControl implementa la replicación de MySQL, es una configuración muy similar. Instalamos HAProxy en un host dado, dos backends, lee en el puerto 3308 y escribe en el puerto 3307. Utiliza tcp-check, esperando que regrese una cadena en particular. Para producir esa cadena, se ejecutan los siguientes pasos en todos los nodos de la base de datos. En primer lugar, xinet.d está configurado para ejecutar un servicio en el puerto 9201 (para evitar confusiones con la configuración de MySQL, que usa el puerto 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDEl servicio ejecuta el script /usr/local/sbin/postgreschk, que valida el estado de PostgreSQL e indica si un host determinado está disponible y qué tipo de host es (maestro o esclavo). Si todo está bien, devuelve la cadena esperada por HAProxy.
Al igual que con MySQL, los nodos HAProxy en los clústeres de PostgreSQL se ven en la interfaz de usuario y se puede acceder a la página de estado:

Aquí puede ver ambos backends y verificar que solo el maestro está activo para el backend r/w y que se puede acceder a todos los nodos a través del backend de solo lectura. También puede obtener algunas estadísticas sobre el tráfico y las conexiones.
HAProxy ayuda a mejorar la alta disponibilidad, pero puede convertirse en un único punto de falla. Necesitamos hacer un esfuerzo adicional y configurar la redundancia con la ayuda de Keepalived.

En Administrar -> Equilibrador de carga -> Keepalived, elija los hosts HAProxy que le gustaría usar y Keepalived se implementará encima de ellos con una IP virtual adjunta a la interfaz de su elección.
A partir de ahora, toda la conectividad debe ir al VIP, que se adjuntará a uno de los nodos HAProxy. Si ese nodo deja de funcionar, Keepalived desactivará el VIP en ese nodo y lo activará en otro nodo HAProxy.
Eso es todo por las funciones de equilibrio de carga introducidas en ClusterControl 1.5. Pruébalos y cuéntanos cómo te fueron