Mover sus datos a un servicio de nube pública es una gran decisión. Todos los principales proveedores de servicios en la nube ofrecen servicios de bases de datos en la nube, y Amazon RDS para MySQL es probablemente el más popular.
En este blog, veremos de cerca qué es, cómo funciona y compararemos sus ventajas y desventajas.
RDS (Servicio de base de datos relacional) es una oferta de Amazon Web Services. En resumen, es una base de datos como servicio, donde Amazon implementa y opera su base de datos. Se ocupa de tareas como la copia de seguridad y la aplicación de parches al software de la base de datos, así como la alta disponibilidad. Algunas bases de datos son compatibles con RDS, aunque aquí estamos principalmente interesados en MySQL:Amazon es compatible con MySQL y MariaDB. También está Aurora, que es el clon de MySQL de Amazon, mejorado, especialmente en el área de replicación y alta disponibilidad.
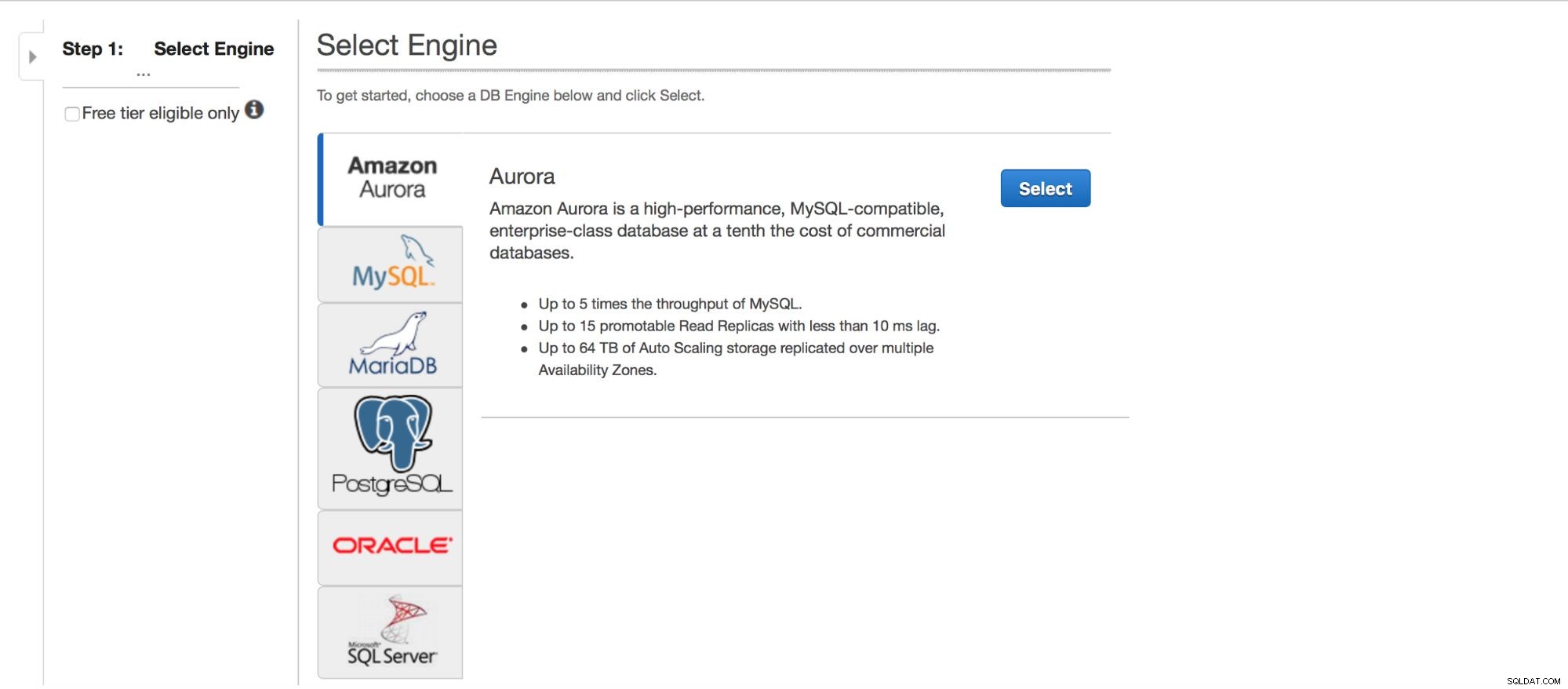
Implementación de MySQL a través de RDS
Echemos un vistazo a la implementación de MySQL a través de RDS. Elegimos MySQL y luego se nos presentan un par de patrones de implementación para elegir.
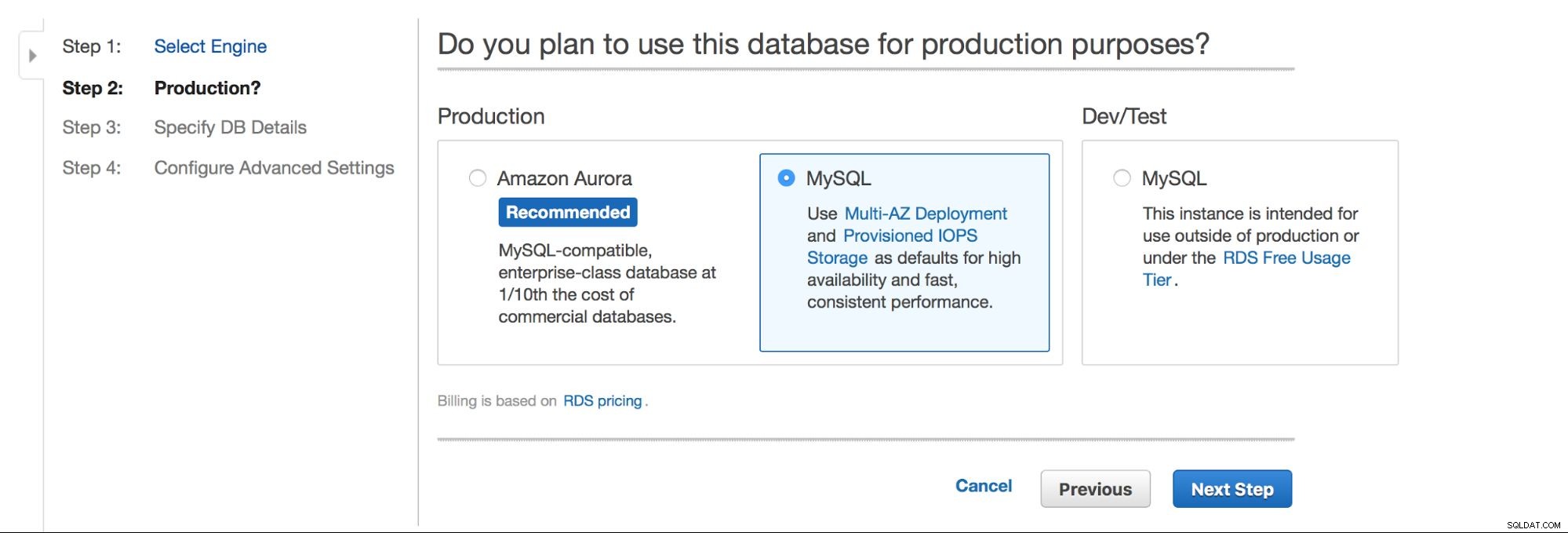
La elección principal es:¿queremos tener alta disponibilidad o no? Aurora también es promocionada.
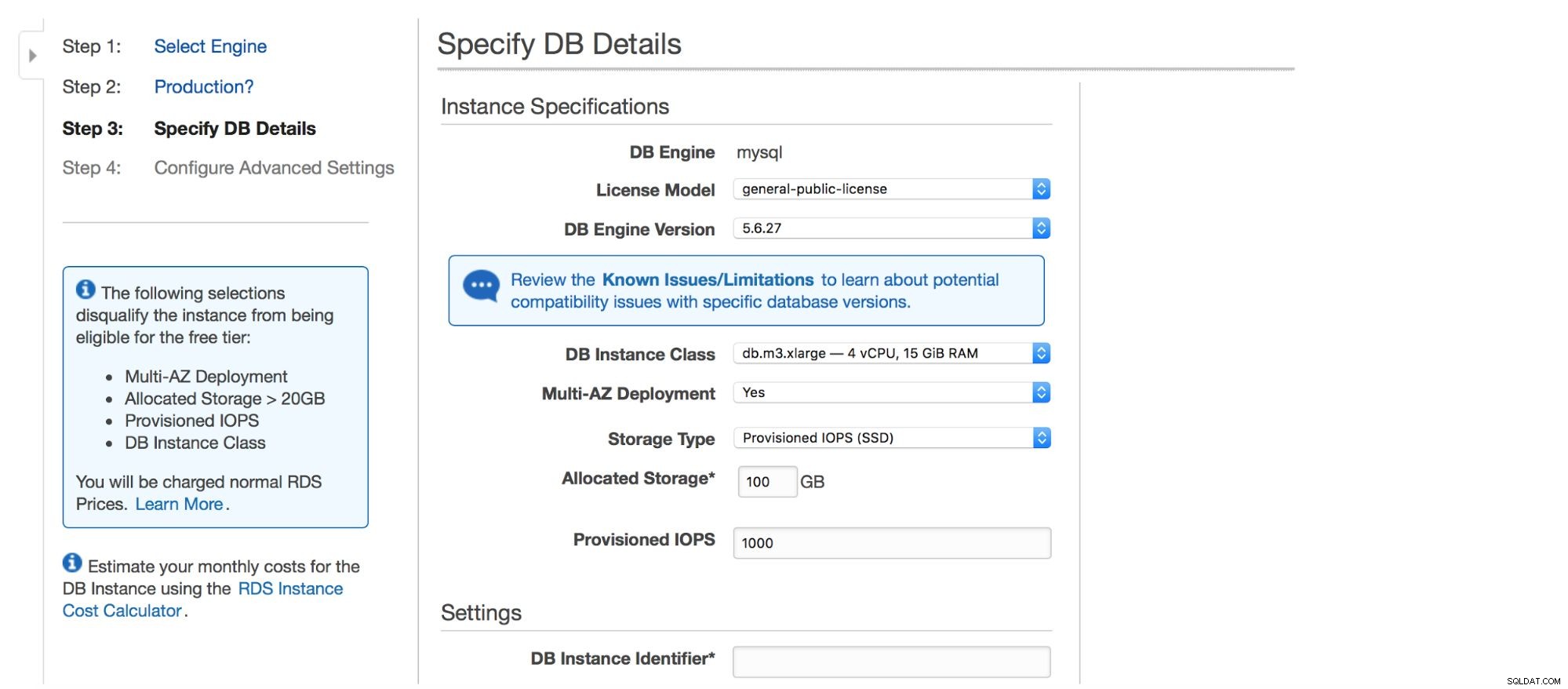
El siguiente cuadro de diálogo nos da algunas opciones para personalizar. Puede elegir una de las muchas versiones de MySQL:hay disponibles varias versiones 5.5, 5.6 y 5.7. Instancia de base de datos:puede elegir entre los tamaños de instancia típicos disponibles en una región determinada.
La siguiente opción es una opción bastante importante:¿desea usar la implementación multi-AZ o no? Todo esto tiene que ver con la alta disponibilidad. Si no desea utilizar la implementación multi-AZ, se instalará una sola instancia. En caso de falla, se activará uno nuevo y se le volverá a montar su volumen de datos. Este proceso lleva algún tiempo, durante el cual su base de datos no estará disponible. Por supuesto, puede minimizar este impacto utilizando esclavos y promoviendo uno de ellos, pero no es un proceso automatizado. Si desea tener una alta disponibilidad automatizada, debe usar la implementación multi-AZ. Lo que sucederá es que se crearán dos instancias de base de datos. Uno es visible para usted. Una segunda instancia, en una zona de disponibilidad separada, no es visible para el usuario. Actuará como una instantánea, lista para hacerse cargo del tráfico una vez que el nodo activo falle. Todavía no es una solución perfecta, ya que el tráfico debe cambiarse de la instancia fallida a la sombra. En nuestras pruebas, tomó ~45 segundos realizar una conmutación por error pero, obviamente, puede depender del tamaño de la instancia, el rendimiento de E/S, etc. Pero es mucho mejor que la conmutación por error no automatizada donde solo están involucrados los esclavos.
Finalmente, tenemos la configuración de almacenamiento:tipo, tamaño, PIOPS (cuando corresponda) y la configuración de la base de datos:identificador, usuario y contraseña.
En el siguiente paso, algunas opciones más esperan la entrada del usuario.
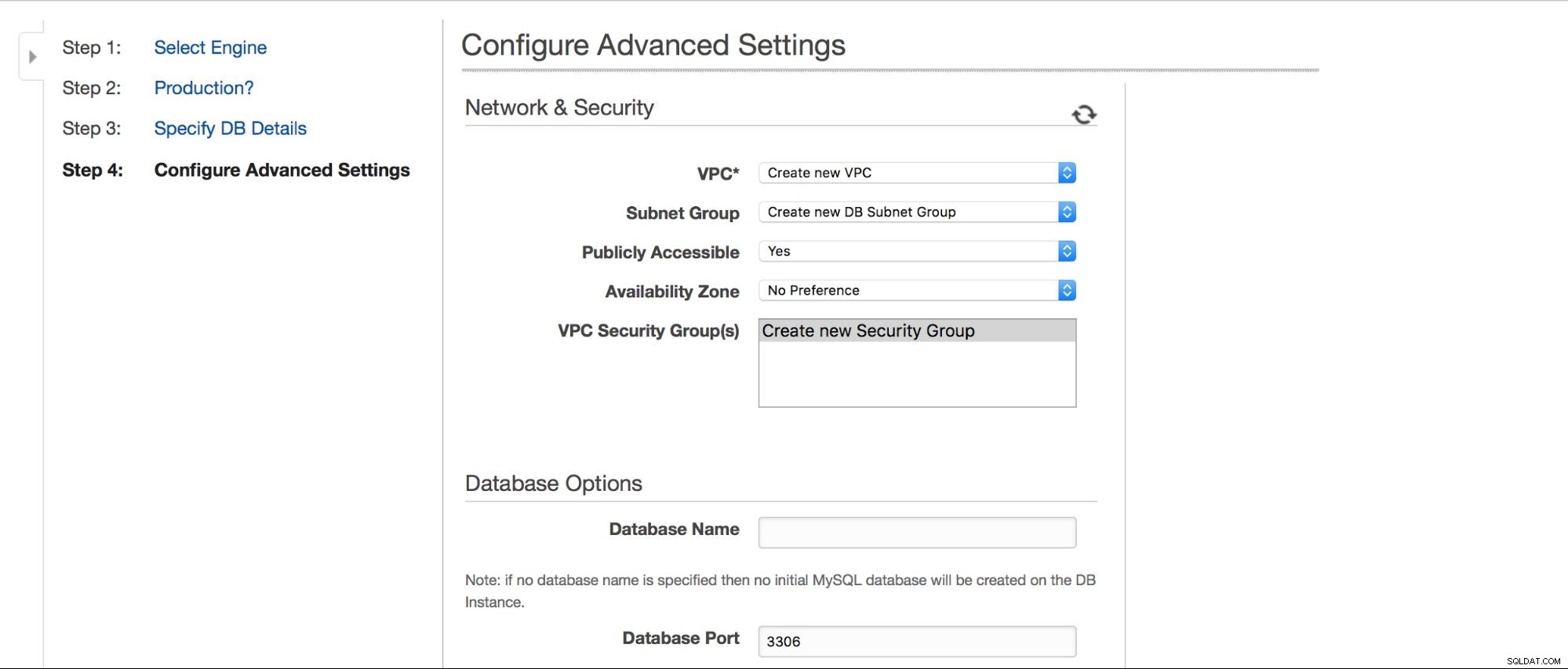
Podemos elegir dónde se debe crear la instancia:VPC, subred, si debe estar disponible públicamente o no (como si se asignara una IP pública a la instancia de RDS), zona de disponibilidad y grupo de seguridad de VPC. Luego, tenemos las opciones de la base de datos:el primer esquema que se creará, el puerto, los grupos de parámetros y opciones, si las etiquetas de metadatos deben incluirse en las instantáneas o no, la configuración de cifrado.
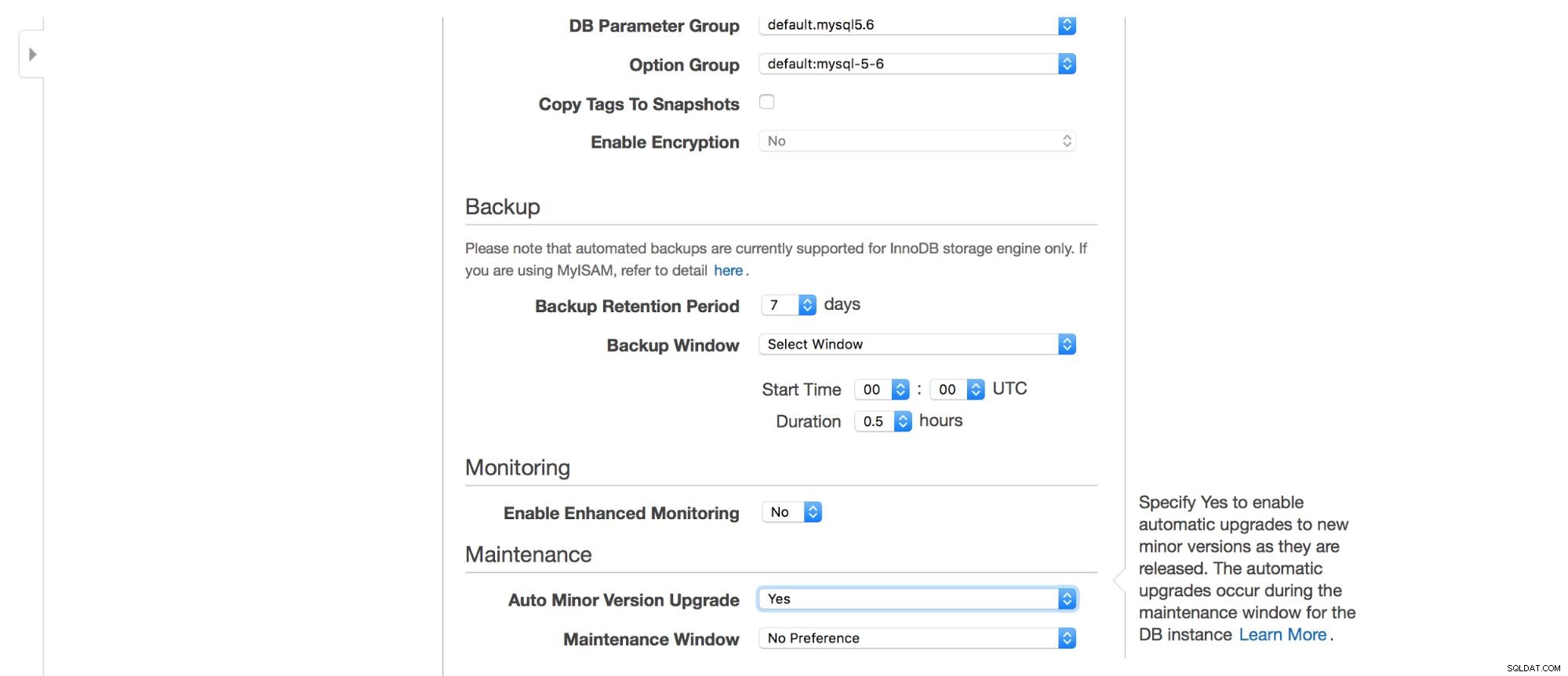
A continuación, opciones de copia de seguridad:¿cuánto tiempo desea conservar sus copias de seguridad? ¿Cuándo te gustaría que se las llevaran? Una configuración similar está relacionada con los mantenimientos; a veces, los administradores de Amazon tienen que realizar un mantenimiento en su instancia de RDS; sucederá dentro de una ventana predefinida que puede configurar aquí. Tenga en cuenta que no hay opción para no elegir al menos 30 minutos para la ventana de mantenimiento, por eso es realmente importante tener una instancia multi-AZ en producción. El mantenimiento puede provocar el reinicio del nodo o la falta de disponibilidad durante algún tiempo. Sin multi-AZ, debe aceptar ese tiempo de inactividad. Con la implementación multi-AZ, ocurre la conmutación por error.
Finalmente, tenemos configuraciones relacionadas con el monitoreo adicional:¿queremos tenerlo habilitado o no?
Administrar RDS
En este capítulo, veremos más de cerca cómo administrar MySQL RDS. No revisaremos todas las opciones disponibles, pero nos gustaría resaltar algunas de las funciones que Amazon puso a disposición.
Instantáneas
MySQL RDS usa volúmenes de EBS como almacenamiento, por lo que puede usar instantáneas de EBS para diferentes propósitos. Copias de seguridad, esclavos, todo basado en instantáneas. Puede crear instantáneas manualmente o se pueden tomar automáticamente, cuando surja tal necesidad. Es importante tener en cuenta que las instantáneas de EBS, en general (no solo en las instancias de RDS), agregan algunos gastos generales a las operaciones de E/S. Si desea tomar una instantánea, espere que su rendimiento de E/S disminuya. A menos que use la implementación multi-AZ, eso es. En tal caso, la instancia "sombra" se utilizará como fuente de instantáneas y no se verá ningún impacto en la instancia de producción.
Guía de DevOps para la gestión de bases de datos de VariousninesConozca lo que necesita saber para automatizar y gestionar sus bases de datos de código abiertoDescargar gratisCopias de seguridad
Las copias de seguridad se basan en instantáneas. Como se mencionó anteriormente, puede definir su programa de respaldo y retención cuando crea una nueva instancia. Por supuesto, puede editar esas configuraciones después, a través de la opción "modificar instancia".
En cualquier momento puede restaurar una instantánea:debe ir a la sección de instantáneas, elegir la instantánea que desea restaurar y se le presentará un cuadro de diálogo similar al que vio cuando creó una nueva instancia. Esto no es una sorpresa, ya que solo puede restaurar una instantánea en una nueva instancia; no hay forma de restaurarla en una de las instancias de RDS existentes. Puede ser una sorpresa, pero incluso en un entorno de nube, puede tener sentido reutilizar el hardware (y las instancias que ya tiene). En un entorno compartido, el rendimiento de una sola instancia virtual puede diferir; es posible que prefiera ceñirse al perfil de rendimiento con el que ya está familiarizado. Desafortunadamente, no es posible en RDS.
Otra opción en RDS es la recuperación de un punto en el tiempo:una característica muy importante, un requisito para cualquier persona que necesite cuidar bien sus datos. Aquí las cosas son más complejas y menos brillantes. Para empezar, es importante tener en cuenta que MySQL RDS oculta los registros binarios del usuario. Puede cambiar un par de configuraciones y enumerar binlogs creados, pero no tiene acceso directo a ellos; para realizar cualquier operación, incluido usarlos para la recuperación, solo puede usar la interfaz de usuario o la CLI. Esto limita sus opciones a lo que Amazon le permite hacer, y le permite restaurar su copia de seguridad hasta el último "tiempo restaurable" que se calcula en un intervalo de 5 minutos. Por lo tanto, si sus datos se eliminaron a las 9:33 a.m., puede restaurarlos solo hasta el estado a las 9:30 a.m. La recuperación de un momento dado funciona de la misma manera que la restauración de instantáneas:se crea una nueva instancia.
Escala horizontal, replicación
MySQL RDS permite escalar horizontalmente mediante la adición de nuevos esclavos. Cuando se crea un esclavo, se toma una instantánea del maestro y se usa para crear un nuevo host. Esta parte funciona bastante bien. Desafortunadamente, no puede crear una topología de replicación más compleja como una que involucre maestros intermedios. No puede crear una configuración maestra - maestra, lo que deja cualquier HA en manos de Amazon (y las implementaciones multi-AZ). Por lo que podemos decir, no hay forma de habilitar GTID (no es que pueda beneficiarse de él, ya que no tiene ningún control sobre la replicación, no hay CHANGE MASTER en RDS), solo posiciones binlog regulares y anticuadas.
La falta de GTID hace que no sea factible usar la replicación multiproceso; si bien es posible establecer una cantidad de trabajadores que usan grupos de parámetros RDS, sin GTID esto no se puede usar. El problema principal es que no hay forma de ubicar una sola posición de registro binario en caso de un bloqueo:algunos trabajadores podrían haber estado atrasados, otros podrían estar más avanzados. Si usa el último evento aplicado, perderá los datos que aún no han aplicado esos trabajadores "rezagados". Si va a utilizar el evento más antiguo, lo más probable es que termine con errores de "clave duplicada" causados por eventos aplicados por aquellos trabajadores que están más avanzados. Por supuesto, hay una manera de resolver este problema, pero no es trivial y requiere mucho tiempo; definitivamente no es algo que pueda automatizar fácilmente.
Los usuarios creados en MySQL RDS no tienen privilegios SUPER, por lo que las operaciones, que son simples en MySQL independiente, no son triviales en RDS. Amazon decidió utilizar procedimientos almacenados para permitir al usuario realizar algunas de esas operaciones. Por lo que podemos decir, se cubren una serie de problemas potenciales, aunque no siempre ha sido el caso:recordamos cuando no podía rotar al siguiente registro binario en el maestro. Una falla maestra + corrupción de binlog podría hacer que todos los esclavos se rompan; ahora hay un procedimiento para eso:rds_next_master_log .
Un esclavo puede ser promovido manualmente a maestro. Esto le permitiría crear algún tipo de HA sobre el mecanismo multi-AZ (o pasarlo por alto), pero no tiene sentido por el hecho de que no puede volver a esclavizar ninguno de los esclavos existentes al nuevo maestro. Recuerde, usted no tiene ningún control sobre la replicación. Esto hace que todo el ejercicio sea inútil, a menos que su maestro pueda acomodar todo su tráfico. Después de promocionar un nuevo maestro, no puede realizar la conmutación por error porque no tiene esclavos para manejar su carga. La creación de nuevos esclavos llevará tiempo, ya que primero se deben crear instantáneas de EBS y esto puede llevar horas. Luego, debe calentar la infraestructura antes de poder cargarla.
Falta de SÚPER Privilegio
Como dijimos anteriormente, RDS no otorga a los usuarios privilegios SUPER y esto se vuelve molesto para alguien que está acostumbrado a tenerlo en MySQL. Dé por sentado que, en las primeras semanas, aprenderá con qué frecuencia se requiere hacer cosas que hace con bastante frecuencia, como eliminar consultas u operar el esquema de rendimiento. En RDS, deberá ceñirse a una lista predefinida de procedimientos almacenados y utilizarlos en lugar de hacer las cosas directamente. Puede enumerarlos todos usando la siguiente consulta:
SELECT specific_name FROM information_schema.routines;Al igual que con la replicación, se cubren una serie de tareas, pero si terminó en una situación que aún no está cubierta, no tendrá suerte.
Interoperabilidad y configuraciones de nube híbrida
Esta es otra área en la que RDS carece de flexibilidad. Supongamos que desea crear una configuración local/en la nube mixta:tiene una infraestructura RDS y le gustaría crear un par de esclavos en las instalaciones. El principal problema al que se enfrentará es que no hay forma de mover datos fuera de RDS, excepto para realizar un volcado lógico. Puede tomar instantáneas de los datos de RDS, pero no tiene acceso a ellos y no puede moverlos fuera de AWS. Tampoco tiene acceso físico a la instancia para usar xtrabackup, rsync o incluso cp. La única opción para usted es usar mysqldump, mydumper o herramientas similares. Esto agrega complejidad (la configuración del juego de caracteres y la intercalación tiene el potencial de causar problemas) y requiere mucho tiempo (lleva mucho tiempo volcar y cargar datos usando herramientas de copia de seguridad lógicas).
Es posible configurar la replicación entre RDS y una instancia externa (en ambos sentidos, por lo que también es posible migrar datos a RDS), pero puede ser un proceso que requiere mucho tiempo.
Por otro lado, si desea permanecer dentro de un entorno RDS y expandir su infraestructura a lo largo del Atlántico o de la costa este a oeste de EE. UU., RDS le permite hacerlo:puede elegir fácilmente una región cuando crea un nuevo esclavo.
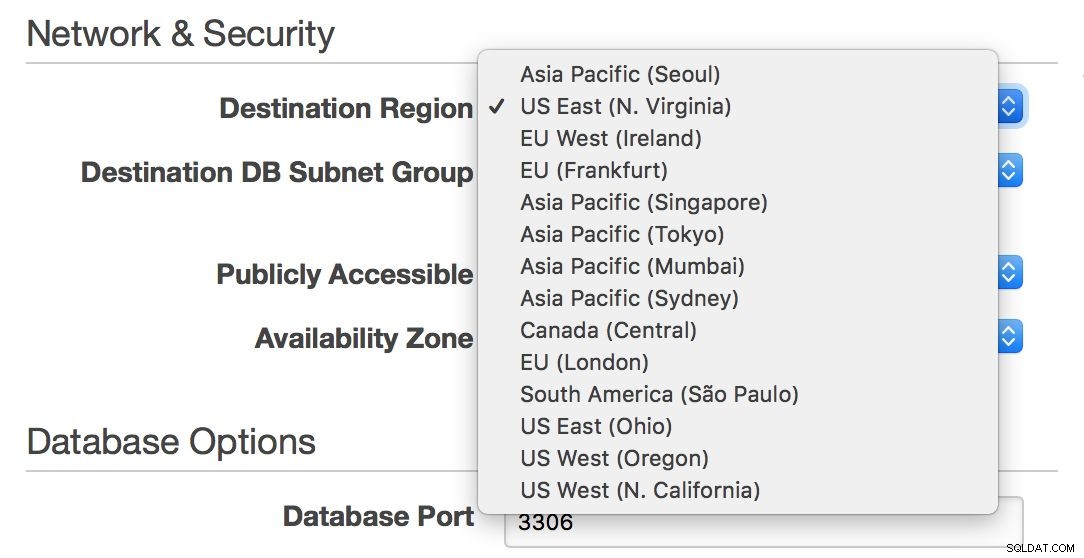
Desafortunadamente, si desea mover su maestro de una región a otra, esto prácticamente no es posible sin tiempo de inactividad, a menos que su único nodo pueda manejar todo su tráfico.
Seguridad
Si bien MySQL RDS es un servicio administrado, los ingenieros de Amazon no se ocupan de todos los aspectos relacionados con la seguridad. Amazon lo llama “Modelo de responsabilidad compartida”. En definitiva, Amazon se encarga de la seguridad de la capa de red y almacenamiento (para que los datos se transfieran de forma segura), sistema operativo (parches, arreglos de seguridad). Por otro lado, el usuario tiene que cuidar el resto del modelo de seguridad. Asegúrese de que el tráfico hacia y desde la instancia de RDS esté limitado dentro de la VPC, asegúrese de que la autenticación a nivel de la base de datos se realice correctamente (sin cuentas de usuario de MySQL sin contraseña), verifique que la seguridad de la API esté garantizada (las AMI están configuradas correctamente y con los privilegios mínimos requeridos). El usuario también debe cuidar la configuración del firewall (grupos de seguridad) para minimizar la exposición de RDS y la VPC en la que se encuentra a redes externas. También es responsabilidad del usuario implementar el cifrado de datos en reposo, ya sea en el nivel de la aplicación o en el nivel de la base de datos, creando una instancia RDS cifrada en primer lugar.
El cifrado a nivel de base de datos solo se puede habilitar en la creación de la instancia, no se puede cifrar una base de datos existente que ya se esté ejecutando.
Limitaciones de RDS
Si planea usar RDS o si ya lo está usando, debe tener en cuenta las limitaciones que vienen con MySQL RDS.
Falta de privilegio SUPER puede ser, como mencionamos, muy molesto. Si bien los procedimientos almacenados se encargan de una serie de operaciones, es una curva de aprendizaje, ya que necesita aprender a hacer las cosas de una manera diferente. La falta de privilegio SUPER también puede crear problemas en el uso de herramientas externas de monitoreo y tendencias; todavía hay algunas herramientas que pueden requerir este privilegio para alguna parte de su funcionalidad.
La falta de acceso directo al directorio de datos y registros de MySQL dificulta la realización de acciones que los involucra. Ocurre de vez en cuando que un DBA necesita analizar registros binarios o errores de cola, consultas lentas o registros generales. Si bien es posible acceder a esos registros en RDS, es más engorroso que hacer lo que sea necesario al iniciar sesión en Shell en el servidor MySQL. Descargarlos localmente también lleva algo de tiempo y agrega latencia adicional a cualquier cosa que haga.
Falta de control sobre la topología de replicación, alta disponibilidad solo en implementaciones multi-AZ. Dado que no tiene control sobre la replicación, no puede implementar ningún tipo de mecanismo de alta disponibilidad en su capa de base de datos. No importa que tenga varios esclavos, no puede usar algunos de ellos como candidatos a maestro porque incluso si promueve un esclavo a maestro, no hay forma de volver a esclavizar a los esclavos restantes de este nuevo maestro. Esto obliga a los usuarios a usar implementaciones multi-AZ y aumenta los costos (la instancia "sombra" no es gratuita, el usuario debe pagar por ella).
Disponibilidad reducida debido al tiempo de inactividad planificado. Al implementar una instancia de RDS, se ve obligado a elegir un período de tiempo semanal de 30 minutos durante el cual se pueden ejecutar las operaciones de mantenimiento en su instancia de RDS. Por un lado, esto es comprensible ya que RDS es una base de datos como servicio, por lo que los ingenieros de AWS administran las actualizaciones de hardware y software de sus instancias de RDS. Por otro lado, esto reduce su disponibilidad porque no puede evitar que su base de datos maestra deje de funcionar durante el período de mantenimiento. Nuevamente, en este caso, el uso de la configuración multi-AZ aumenta la disponibilidad ya que los cambios ocurren primero en la instancia oculta y luego se ejecuta la conmutación por error. Sin embargo, la conmutación por error en sí misma no es transparente, por lo que, de una forma u otra, se pierde el tiempo de actividad. Esto lo obliga a diseñar su aplicación teniendo en cuenta las fallas maestras inesperadas de MySQL. No es que sea un mal patrón de diseño:las bases de datos pueden colapsar en cualquier momento y su aplicación debe construirse de manera que pueda soportar incluso el escenario más grave. Es solo que con RDS, tiene opciones limitadas para alta disponibilidad.
Opciones reducidas para implementación de alta disponibilidad. Dada la falta de flexibilidad en la administración de la topología de replicación, el único método factible de alta disponibilidad es la implementación multi-AZ. Este método es bueno, pero existen herramientas para la replicación de MySQL que minimizarían aún más el tiempo de inactividad. Por ejemplo, MHA o ClusterControl, cuando se usan en conexión con ProxySQL, pueden ofrecer (en algunas condiciones, como la falta de transacciones de ejecución prolongada) un proceso de conmutación por error transparente para la aplicación. Mientras esté en RDS, no podrá usar este método.
Información reducida sobre el rendimiento de su base de datos. Si bien puede obtener métricas de MySQL, a veces no es suficiente para obtener una vista completa de la situación de 10k pies. En algún momento, la mayoría de los usuarios tendrán que lidiar con problemas realmente extraños causados por hardware defectuoso o infraestructura defectuosa:paquetes de red perdidos, conexiones terminadas abruptamente o una utilización de CPU inesperadamente alta. Cuando tiene acceso a su host MySQL, puede aprovechar muchas herramientas que lo ayudan a diagnosticar el estado de un servidor Linux. Cuando usa RDS, está limitado a las métricas disponibles en Cloudwatch, la herramienta de monitoreo y tendencias de Amazon. Cualquier diagnóstico más detallado requiere ponerse en contacto con el soporte y pedirles que verifiquen y solucionen el problema. Esto puede ser rápido, pero también puede ser un proceso muy largo con mucha comunicación por correo electrónico de ida y vuelta.
El bloqueo del proveedor causado por el proceso complejo y lento de obtener datos de MySQL RDS. RDS no otorga acceso al directorio de datos de MySQL, por lo que no hay forma de utilizar herramientas estándar de la industria como xtrabackup para mover datos de forma binaria. Por otro lado, el RDS bajo el capó es un MySQL mantenido por Amazon, es difícil saber si es 100% compatible con upstream o no. RDS solo está disponible en AWS, por lo que no podrá realizar una configuración híbrida.
Resumen
MySQL RDS tiene fortalezas y debilidades. Esta es una muy buena herramienta para aquellos que deseen concentrarse en la aplicación sin tener que preocuparse por operar la base de datos. Implementa una base de datos y comienza a emitir consultas. No es necesario crear secuencias de comandos de copia de seguridad ni configurar una solución de monitoreo porque ya lo han hecho los ingenieros de AWS; todo lo que necesita hacer es usarlo.
También hay un lado oscuro de MySQL RDS. Falta de opciones para construir configuraciones más complejas y escalar fuera de solo agregar más esclavos. Falta de soporte para una mejor alta disponibilidad que la propuesta en las implementaciones multi-AZ. Acceso engorroso a los registros de MySQL. Falta de acceso directo al directorio de datos de MySQL y falta de soporte para copias de seguridad físicas, lo que dificulta mover los datos fuera de la instancia de RDS.
En resumen, RDS puede funcionar bien para usted si valora la facilidad de uso sobre el control detallado de la base de datos. Debe tener en cuenta que, en algún momento en el futuro, puede superar a MySQL RDS. No estamos hablando necesariamente aquí solo de rendimiento. Se trata más de las necesidades de su organización para una topología de replicación más compleja o la necesidad de tener una mejor visión de las operaciones de la base de datos para tratar rápidamente los diferentes problemas que surgen de vez en cuando. En ese caso, si su conjunto de datos ya ha crecido en tamaño, puede resultarle complicado salir del RDS. Antes de tomar la decisión de mover sus datos a RDS, los administradores de información deben considerar los requisitos y limitaciones de su organización en áreas específicas.
En las próximas publicaciones de blog, le mostraremos cómo sacar sus datos del RDS a una ubicación separada. Hablaremos sobre la migración a EC2 y a la infraestructura local.