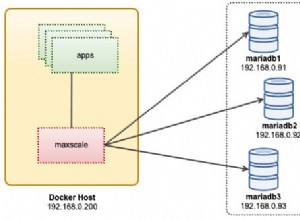
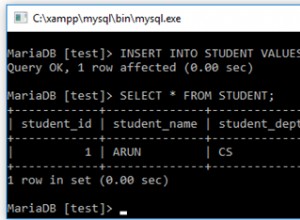
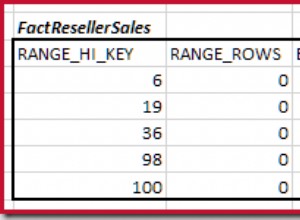
La principal diferencia es la precisión de clasificación (al comparar caracteres en el idioma) y el rendimiento. El único especial es utf8_bin, que es para comparar caracteres en formato binario.
utf8_general_ci es algo más rápido que utf8_unicode_ci , pero menos preciso (para ordenar). La codificación utf8 del idioma específico (como utf8_swedish_ci ) contienen reglas de idioma adicionales que los hacen más precisos para ordenar esos idiomas. La mayor parte del tiempo uso utf8_unicode_ci (Prefiero la precisión a las pequeñas mejoras de rendimiento), a menos que tenga una buena razón para preferir un idioma específico.
Puede leer más sobre conjuntos de caracteres Unicode específicos en el manual de MySQL - http://dev.mysql.com/doc/refman/5.0/en/charset-unicode-sets.html