Python y SQL son dos de los lenguajes más importantes para los analistas de datos.
En este artículo, lo guiaré a través de todo lo que necesita saber para conectar Python y SQL.
Aprenderá cómo extraer datos de bases de datos relacionales directamente a sus canalizaciones de aprendizaje automático, almacenar datos de su aplicación Python en una base de datos propia o cualquier otro caso de uso que se le ocurra.
Juntos cubriremos:
- ¿Por qué aprender a usar Python y SQL juntos?
- Cómo configurar su entorno Python y MySQL Server
- Conexión al servidor MySQL en Python
- Crear una nueva base de datos
- Creación de tablas y relaciones entre tablas
- Rellenar tablas con datos
- Lectura de datos
- Actualización de registros
- Eliminación de registros
- Creación de registros a partir de listas de Python
- Crear funciones reutilizables para hacer todo esto por nosotros en el futuro
Eso es un montón de cosas muy útiles y muy interesantes. ¡Vamos a hacerlo!
Una nota rápida antes de comenzar:hay un Jupyter Notebook que contiene todo el código utilizado en este tutorial disponible en este repositorio de GitHub. ¡Se recomienda encarecidamente la codificación!
La base de datos y el código SQL que se usan aquí provienen de mi serie anterior Introducción a SQL publicada en Towards Data Science (contácteme si tiene algún problema para ver los artículos y puedo enviarle un enlace para verlos de forma gratuita).
Si no está familiarizado con SQL y los conceptos detrás de las bases de datos relacionales, le recomendaría esa serie (¡además, por supuesto, hay una gran cantidad de cosas geniales disponibles aquí en freeCodeCamp!)
¿Por qué Python con SQL?
Para los analistas de datos y los científicos de datos, Python tiene muchas ventajas. Una amplia gama de bibliotecas de código abierto lo convierten en una herramienta increíblemente útil para cualquier analista de datos.
Tenemos pandas, NumPy y Vaex para análisis de datos, Matplotlib, seaborn y Bokeh para visualización, y TensorFlow, scikit-learn y PyTorch para aplicaciones de aprendizaje automático (y muchas, muchas más).
Con su curva de aprendizaje (relativamente) fácil y su versatilidad, no sorprende que Python sea uno de los lenguajes de programación de más rápido crecimiento que existen.
Entonces, si usamos Python para el análisis de datos, vale la pena preguntarse:¿de dónde provienen todos estos datos?
Si bien existe una gran variedad de fuentes para conjuntos de datos, en muchos casos, particularmente en negocios empresariales, los datos se almacenarán en una base de datos relacional. Las bases de datos relacionales son una forma extremadamente eficiente, poderosa y ampliamente utilizada para crear, leer, actualizar y eliminar datos de todo tipo.
Los sistemas de gestión de bases de datos relacionales (RDBMS) más utilizados (Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2) utilizan el lenguaje de consulta estructurado (SQL) para acceder y realizar cambios en los datos.
Tenga en cuenta que cada RDBMS usa un sabor ligeramente diferente de SQL, por lo que el código SQL escrito para uno generalmente no funcionará en otro sin modificaciones (normalmente bastante menores). Pero los conceptos, estructuras y operaciones son en gran medida idénticos.
Esto significa que para un analista de datos que trabaja, una sólida comprensión de SQL es muy importante. Saber cómo usar Python y SQL juntos le dará una ventaja aún mayor cuando se trata de trabajar con sus datos.
El resto de este artículo se dedicará a mostrarle exactamente cómo podemos hacerlo.
Cómo empezar
Requisitos e instalación
Para codificar junto con este tutorial, necesitará configurar su propio entorno de Python.
Yo uso Anaconda, pero hay muchas formas de hacerlo. Simplemente busque en Google "cómo instalar Python" si necesita más ayuda. También puede usar Binder para codificar junto con el Jupyter Notebook asociado.
Usaremos MySQL Community Server ya que es gratuito y ampliamente utilizado en la industria. Si usa Windows, esta guía lo ayudará a configurarlo. Aquí también hay guías para usuarios de Mac y Linux (aunque puede variar según la distribución de Linux).
Una vez que los haya configurado, necesitaremos que se comuniquen entre sí.
Para eso, necesitamos instalar la biblioteca MySQL Connector Python. Para hacer esto, siga las instrucciones o simplemente use pip:
pip install mysql-connector-pythonTambién vamos a usar pandas, así que asegúrese de tener eso instalado también.
pip install pandasImportación de bibliotecas
Como con todos los proyectos en Python, lo primero que queremos hacer es importar nuestras bibliotecas.
Es una buena práctica importar todas las bibliotecas que vamos a usar al comienzo del proyecto, para que las personas que lean o revisen nuestro código sepan aproximadamente lo que se avecina y no haya sorpresas.
Para este tutorial, solo usaremos dos bibliotecas:MySQL Connector y pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdImportamos la función Error por separado para que podamos acceder fácilmente a ella para nuestras funciones.
Conectando al servidor MySQL
Llegados a este punto, deberíamos tener MySQL Community Server configurado en nuestro sistema. Ahora necesitamos escribir un código en Python que nos permita establecer una conexión con ese servidor.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionCrear una función reutilizable para código como este es una buena práctica, de modo que podamos usarla una y otra vez con el mínimo esfuerzo. Una vez que esto esté escrito, podrás reutilizarlo en todos tus proyectos en el futuro, así que en el futuro, ¡te lo agradecerás!
Repasemos esto línea por línea para que entendamos lo que está pasando aquí:
La primera línea es nosotros nombrando la función (create_server_connection) y nombrando los argumentos que tomará esa función (host_name, user_name y user_password).
La siguiente línea cierra cualquier conexión existente para que el servidor no se confunda con varias conexiones abiertas.
A continuación, usamos un bloque try-except de Python para manejar cualquier error potencial. La primera parte intenta crear una conexión con el servidor usando el método mysql.connector.connect() usando los detalles especificados por el usuario en los argumentos. Si esto funciona, la función imprime un pequeño y feliz mensaje de éxito.
La parte excepto del bloque imprime el error que devuelve MySQL Server, en el desafortunado caso de que haya un error.
Finalmente, si la conexión es exitosa, la función devuelve un objeto de conexión.
Usamos esto en la práctica asignando la salida de la función a una variable, que luego se convierte en nuestro objeto de conexión. Luego podemos aplicarle otros métodos (como el cursor) y crear otros objetos útiles.
connection = create_server_connection("localhost", "root", pw)Esto debería producir un mensaje de éxito:

Creando una nueva base de datos
Ahora que hemos establecido una conexión, nuestro próximo paso es crear una nueva base de datos en nuestro servidor.
En este tutorial, haremos esto solo una vez, pero nuevamente lo escribiremos como una función reutilizable para que tengamos una buena función útil que podamos reutilizar para proyectos futuros.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Esta función toma dos argumentos, conexión (nuestro objeto de conexión) y consulta (una consulta SQL que escribiremos en el siguiente paso). Ejecuta la consulta en el servidor a través de la conexión.
Usamos el método del cursor en nuestro objeto de conexión para crear un objeto de cursor (MySQL Connector usa un paradigma de programación orientado a objetos, por lo que hay muchos objetos que heredan propiedades de los objetos principales).
Este objeto de cursor tiene métodos como ejecutar, ejecutar muchos (que usaremos en este tutorial) junto con varios otros métodos útiles.
Si ayuda, podemos pensar que el objeto del cursor nos proporciona acceso al cursor parpadeante en una ventana de terminal del servidor MySQL.
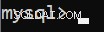
A continuación definimos una consulta para crear la base de datos y llamamos a la función:

Todas las consultas SQL utilizadas en este tutorial se explican en mi serie de tutoriales Introducción a SQL, y el código completo se puede encontrar en el Jupyter Notebook asociado en este repositorio de GitHub, por lo que no proporcionaré explicaciones de lo que hace el código SQL en este tutorial.
Sin embargo, esta es quizás la consulta SQL más simple posible. ¡Si puedes leer inglés, probablemente puedas averiguar lo que hace!
Al ejecutar la función create_database con los argumentos anteriores, se crea una base de datos llamada 'escuela' en nuestro servidor.
¿Por qué nuestra base de datos se llama 'escuela'? Tal vez ahora sea un buen momento para ver con más detalle exactamente lo que vamos a implementar en este tutorial.
Nuestra base de datos
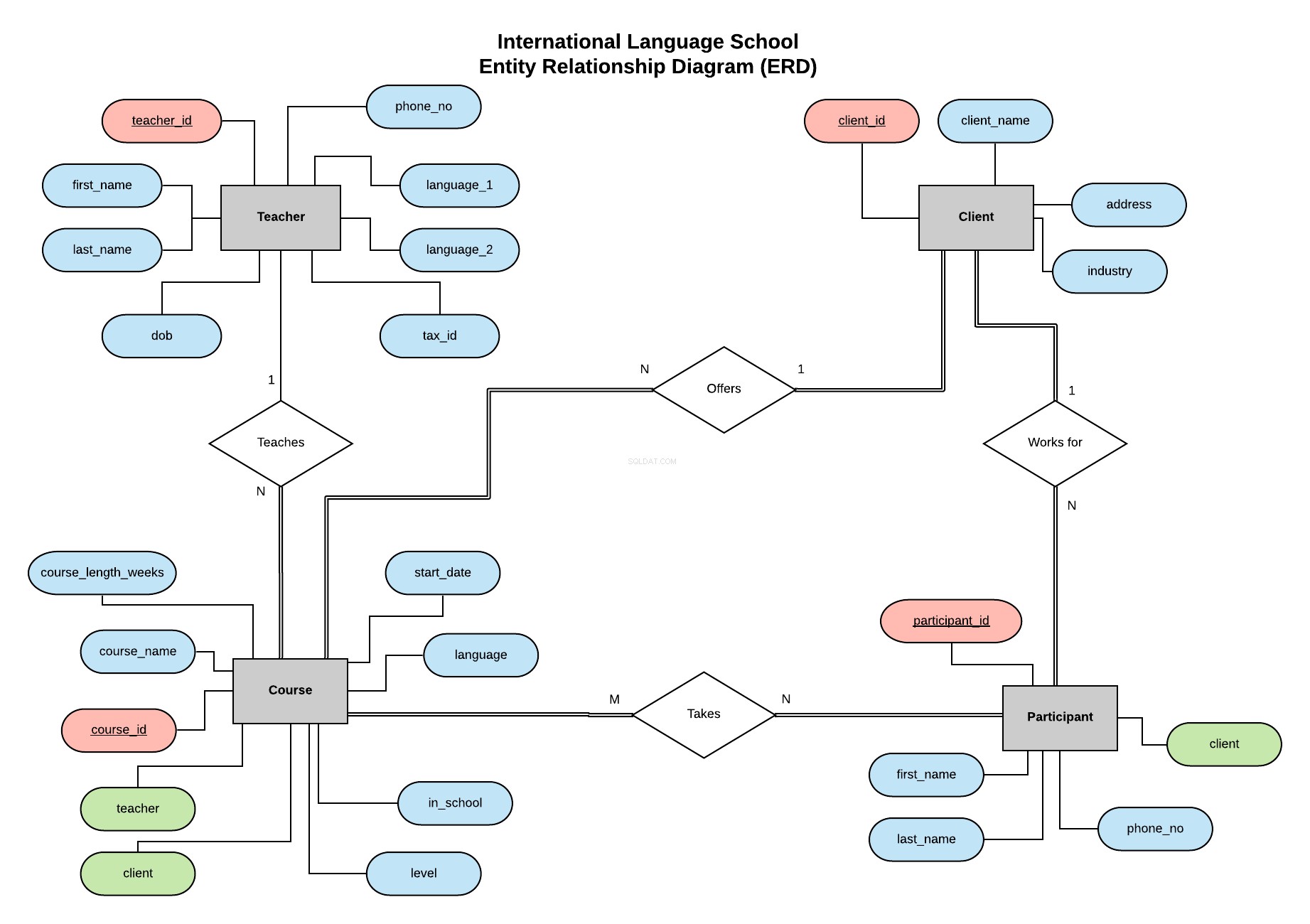
Siguiendo el ejemplo de mi serie anterior, implementaremos la base de datos para la Escuela Internacional de Idiomas, una escuela ficticia de capacitación en idiomas que brinda lecciones profesionales de idiomas a clientes corporativos.
Este Diagrama de Relación de Entidades (ERD) presenta nuestras entidades (Profesor, Cliente, Curso y Participante) y define las relaciones entre ellas.
Toda la información sobre qué es un ERD y qué considerar al crear uno y diseñar una base de datos se puede encontrar en este artículo.
El código SQL sin procesar, los requisitos de la base de datos y los datos para entrar en la base de datos están todos contenidos en este repositorio de GitHub, pero también lo verás a medida que avanzamos en este tutorial.
Conectando a la base de datos
Ahora que hemos creado una base de datos en MySQL Server, podemos modificar nuestra función create_server_connection para conectarnos directamente a esta base de datos.
Tenga en cuenta que es posible, de hecho, común, tener varias bases de datos en un servidor MySQL, por lo que queremos conectarnos siempre y automáticamente a la base de datos que nos interesa.
Podemos hacer esto así:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionEsta es exactamente la misma función, pero ahora tomamos un argumento más, el nombre de la base de datos, y lo pasamos como argumento al método connect().
Creando una Función de Ejecución de Consultas
La función final que vamos a crear (por ahora) es extremadamente vital:una función de ejecución de consultas. Esto tomará nuestras consultas SQL, almacenadas en Python como cadenas, y las pasará al método cursor.execute() para ejecutarlas en el servidor.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Esta función es exactamente igual a nuestra función create_database anterior, excepto que usa el método connection.commit() para asegurarse de que se implementen los comandos detallados en nuestras consultas SQL.
Esta será nuestra función de caballo de batalla, que usaremos (junto con create_db_connection) para crear tablas, establecer relaciones entre esas tablas, llenar las tablas con datos y actualizar y eliminar registros en nuestra base de datos.
Si es un experto en SQL, esta función le permitirá ejecutar todos y cada uno de los comandos y consultas complejos que pueda tener, directamente desde un script de Python. Esta puede ser una herramienta muy poderosa para administrar sus datos.
Creando Tablas
Ahora estamos listos para comenzar a ejecutar comandos SQL en nuestro servidor y comenzar a construir nuestra base de datos. Lo primero que queremos hacer es crear las tablas necesarias.
Comencemos con nuestra tabla de profesores:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryEn primer lugar asignamos nuestro comando SQL (explicado en detalle aquí) a una variable con un nombre apropiado.
En este caso, usamos la notación de comillas triples de Python para cadenas de varias líneas para almacenar nuestra consulta SQL, luego la ingresamos en nuestra función execute_query para implementarla.
Tenga en cuenta que este formato de varias líneas es puramente para el beneficio de los humanos que leen nuestro código. Ni a SQL ni a Python 'les importa' si el comando SQL se distribuye de esta manera. Siempre que la sintaxis sea correcta, ambos idiomas la aceptarán.
Sin embargo, para el beneficio de los humanos que leerán su código (¡incluso si solo será usted en el futuro!), es muy útil hacer esto para que el código sea más legible y comprensible.
Lo mismo es cierto para las MAYÚSCULAS de los operadores en SQL. Esta es una convención ampliamente utilizada que se recomienda encarecidamente, pero el software real que ejecuta el código no distingue entre mayúsculas y minúsculas y tratará 'CREATE TABLE teacher' y 'create table teacher' como comandos idénticos.

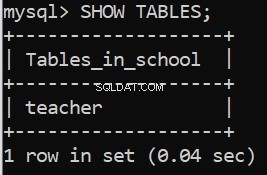
Ejecutar este código nos da nuestros mensajes de éxito. También podemos verificar esto en el cliente de línea de comandos del servidor MySQL:
¡Estupendo! Ahora vamos a crear las tablas restantes.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Esto crea las cuatro tablas necesarias para nuestras cuatro entidades.
Ahora queremos definir las relaciones entre ellos y crear una tabla más para manejar la relación de muchos a muchos entre las tablas de participantes y del curso (consulte aquí para obtener más detalles).
Hacemos esto exactamente de la misma manera:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Ahora nuestras tablas están creadas, junto con las restricciones apropiadas, la clave principal y las relaciones de clave externa.
Rellenando las Tablas
El siguiente paso es agregar algunos registros a las tablas. Nuevamente usamos execute_query para alimentar nuestros comandos SQL existentes en el servidor. Empecemos de nuevo con la mesa del profesor.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)¿Esto funciona? Podemos comprobar de nuevo en nuestro cliente de línea de comandos de MySQL:
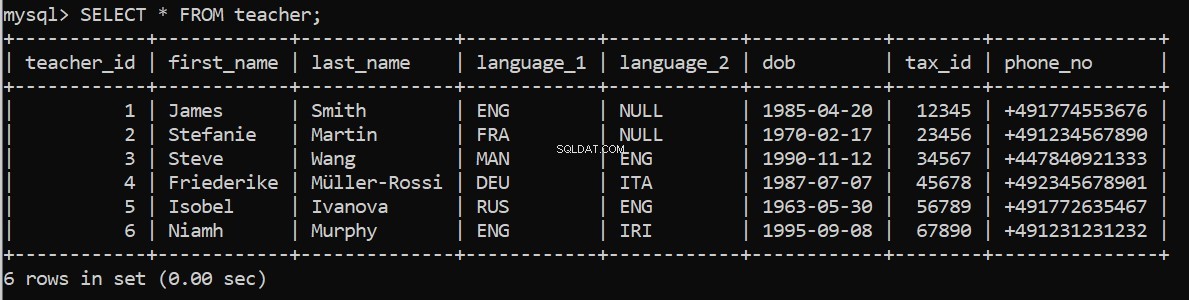
Ahora para llenar las tablas restantes.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)¡Increíble! Ahora hemos creado una base de datos completa con relaciones, restricciones y registros en MySQL, usando nada más que comandos de Python.
Hemos repasado esto paso a paso para que sea comprensible. Pero en este punto, puede ver que todo esto podría escribirse muy fácilmente en un script de Python y ejecutarse en un comando en la terminal. Cosas poderosas.
Lectura de datos
Ahora tenemos una base de datos funcional para trabajar. Como analista de datos, es probable que entre en contacto con las bases de datos existentes en las organizaciones en las que trabaja. Será muy útil saber cómo extraer datos de esas bases de datos para que luego puedan introducirse en su tubería de datos de python. Esto es en lo que vamos a trabajar a continuación.
Para esto, necesitaremos una función más, esta vez utilizando cursor.fetchall() en lugar de cursor.commit(). Con esta función, estamos leyendo datos de la base de datos y no haremos ningún cambio.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Nuevamente, vamos a implementar esto de una manera muy similar a ejecutar_consulta. Probémoslo con una simple consulta para ver cómo funciona.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)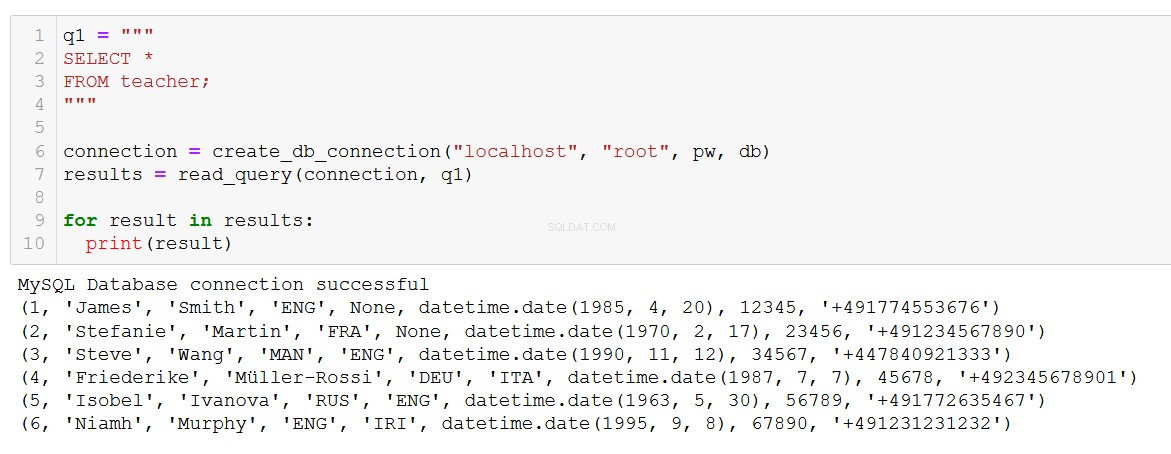
Exactamente lo que estamos esperando. La función también funciona con consultas más complejas, como esta que involucra un JOIN en las tablas del curso y del cliente.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)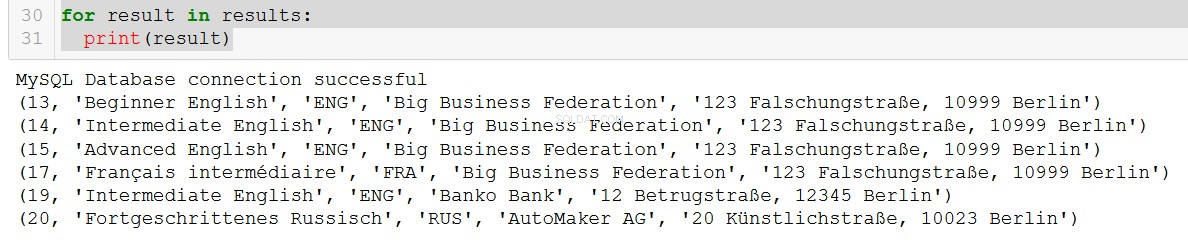
Muy agradable.
Para nuestras canalizaciones de datos y flujos de trabajo en Python, es posible que deseemos obtener estos resultados en diferentes formatos para que sean más útiles o estén listos para que los manipulemos.
Veamos un par de ejemplos para ver cómo podemos hacerlo.
Dar formato a la salida en una lista
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Dar formato a la salida en una lista de listas
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatting Output en un pandas DataFrame
Para los analistas de datos que usan Python, pandas es nuestro hermoso y confiable viejo amigo. Es muy simple convertir la salida de nuestra base de datos en un DataFrame, ¡y desde allí las posibilidades son infinitas!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)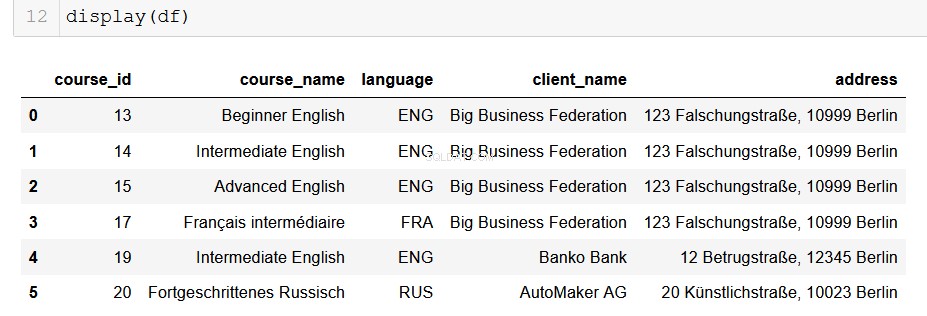
Esperemos que pueda ver las posibilidades que se despliegan frente a usted aquí. Con solo unas pocas líneas de código, podemos extraer fácilmente todos los datos que podemos manejar de las bases de datos relacionales donde residen e incorporarlos a nuestras canalizaciones de análisis de datos de última generación. Esto es realmente útil.
Actualización de registros
Cuando mantenemos una base de datos, a veces necesitaremos hacer cambios en los registros existentes. En esta sección vamos a ver cómo hacerlo.
Digamos que se notifica a la ILS que uno de sus clientes existentes, la Big Business Federation, mudará sus oficinas a 23 Fingiertweg, 14534 Berlín. En este caso, el administrador de la base de datos (¡somos nosotros!) deberá realizar algunos cambios.
Afortunadamente, podemos hacer esto con nuestra función execute_query junto con la instrucción SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Tenga en cuenta que la cláusula WHERE es muy importante aquí. Si ejecutamos esta consulta sin la cláusula WHERE, todas las direcciones de todos los registros en nuestra tabla de clientes se actualizarán a 23 Fingertweg. Eso no es lo que buscamos hacer.
También tenga en cuenta que usamos "WHERE client_id =101" en la consulta de ACTUALIZACIÓN. También habría sido posible usar "WHERE client_name ='Big Business Federation'" o "WHERE dirección ='123 Falschungstraße, 10999 Berlin'" o incluso "WHERE dirección LIKE '%Falschung%'".
Lo importante es que la cláusula WHERE nos permite identificar de forma única el registro (o registros) que queremos actualizar.
Eliminación de registros
También es posible usar nuestra función execute_query para borrar registros, usando DELETE.
Al usar SQL con bases de datos relacionales, debemos tener cuidado al usar el operador DELETE. Esto no es Windows, no hay '¿Está seguro de que desea eliminar esto?' ventana emergente de advertencia y no hay papelera de reciclaje. Una vez que eliminamos algo, realmente desaparece.
Dicho esto, realmente necesitamos eliminar cosas a veces. Así que echemos un vistazo a eso eliminando un curso de nuestra tabla de cursos.
En primer lugar, recordemos qué cursos tenemos.
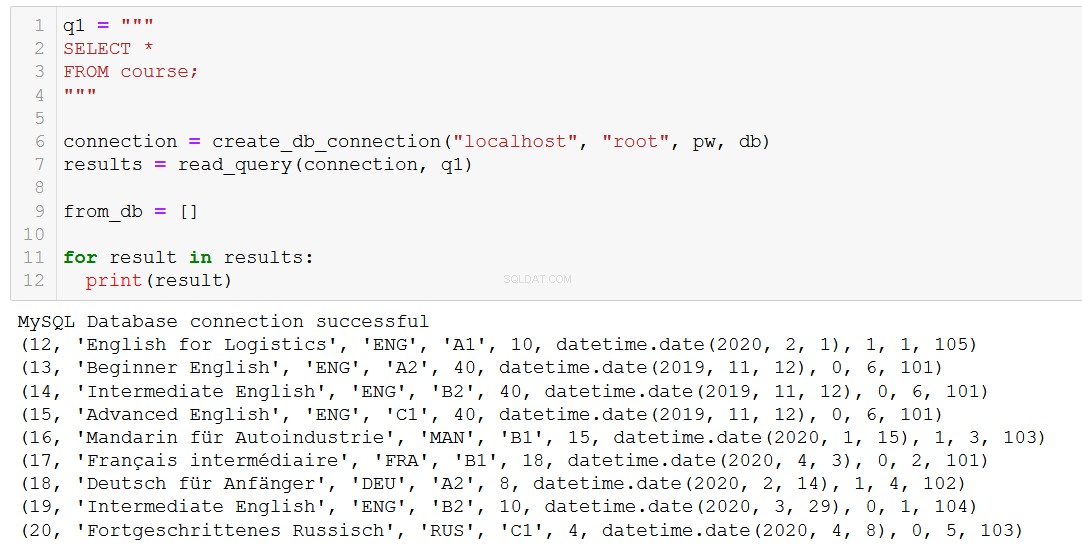
Digamos que el curso 20, 'Fortgeschrittenes Russisch' (que es 'Ruso avanzado' para usted y para mí), está llegando a su fin, por lo que debemos eliminarlo de nuestra base de datos.
En esta etapa, no se sorprenderá en absoluto con la forma en que hacemos esto:guarde el comando SQL como una cadena, luego introdúzcalo en nuestra función de ejecución de consulta de caballo de batalla.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Verifiquemos para confirmar que tuvo el efecto deseado:
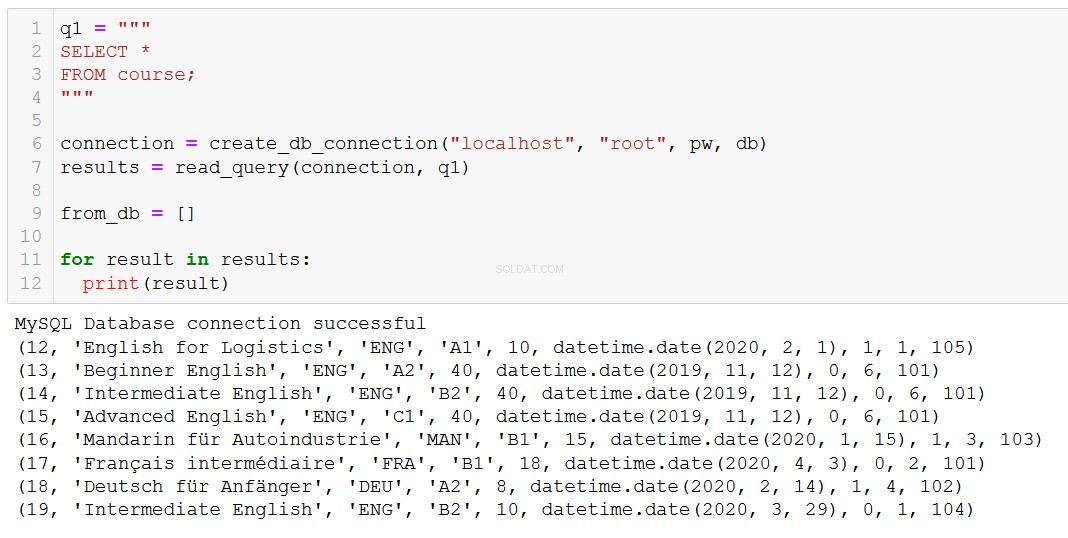
El 'ruso avanzado' se ha ido, como esperábamos.
Esto también funciona con la eliminación de columnas completas usando DROP COLUMN y tablas completas usando los comandos DROP TABLE, pero no los cubriremos en este tutorial.
Sin embargo, continúe y experimente con ellos; no importa si elimina una columna o una tabla de una base de datos para una escuela ficticia, y es una buena idea familiarizarse con estos comandos antes de pasar a un entorno de producción.
Oh CRUD
En este punto, ahora podemos completar las cuatro operaciones principales para el almacenamiento persistente de datos.
Hemos aprendido a:
- Crear:bases de datos, tablas y registros completamente nuevos
- Lectura:extraiga datos de una base de datos y almacene esos datos en varios formatos
- Actualizar:realice cambios en los registros existentes en la base de datos
- Eliminar:elimina registros que ya no son necesarios
Estas son cosas fantásticamente útiles para poder hacer.
Antes de terminar las cosas aquí, tenemos una habilidad más muy útil para aprender.
Creando Registros desde Listas
Vimos al llenar nuestras tablas que podemos usar el comando SQL INSERT en nuestra función execute_query para insertar registros en nuestra base de datos.
Dado que estamos usando Python para manipular nuestra base de datos SQL, sería útil poder tomar una estructura de datos de Python (como una lista) e insertarla directamente en nuestra base de datos.
Esto podría ser útil cuando queremos almacenar registros de la actividad del usuario en una aplicación de redes sociales que hemos escrito en Python, o la entrada de los usuarios en un wiki que hemos creado, por ejemplo. Hay tantos usos posibles para esto como puedas imaginar.
Este método también es más seguro si nuestra base de datos está abierta a nuestros usuarios en cualquier momento, ya que ayuda a prevenir ataques de inyección SQL, que pueden dañar o incluso destruir toda nuestra base de datos.
Para hacer esto, escribiremos una función usando el método executemany(), en lugar del método de ejecución() más simple que hemos estado usando hasta ahora.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Ahora que tenemos la función, necesitamos definir un comando SQL ('sql') y una lista que contiene los valores que deseamos ingresar a la base de datos ('val'). Los valores deben almacenarse como una lista de tuplas, que es una forma bastante común de almacenar datos en Python.
Para agregar dos nuevos maestros a la base de datos, podemos escribir un código como este:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Observe aquí que en el código 'sql' usamos '%s' como marcador de posición para nuestro valor. El parecido con el marcador de posición '%s' para una cadena en python es solo una coincidencia (y, francamente, muy confuso), queremos usar '%s' para todos los tipos de datos (cadenas, enteros, fechas, etc.) con MySQL Python Conector.
Puede ver una serie de preguntas en Stackoverflow donde alguien se confundió e intentó usar marcadores de posición '%d' para números enteros porque están acostumbrados a hacer esto en Python. Esto no funcionará aquí:necesitamos usar un '%s' para cada columna a la que queremos agregar un valor.
La función executemany luego toma cada tupla en nuestra lista 'val' e inserta el valor relevante para esa columna en lugar del marcador de posición y ejecuta el comando SQL para cada tupla contenida en la lista.
Esto se puede realizar para varias filas de datos, siempre que tengan el formato correcto. En nuestro ejemplo solo añadiremos dos nuevos profesores, con fines ilustrativos, pero en principio podemos añadir tantos como queramos.
Avancemos y ejecutemos esta consulta y agreguemos los maestros a nuestra base de datos.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)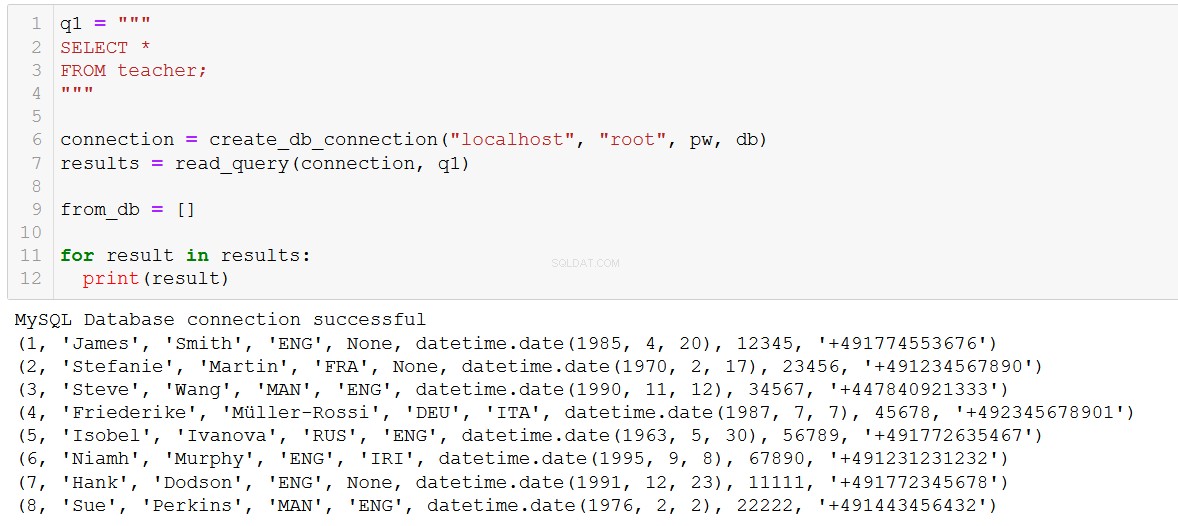
¡Bienvenidos a la ILS, Hank y Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!