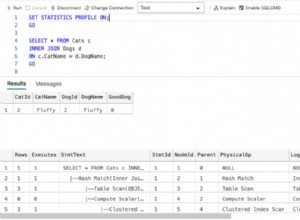
Mejora significativamente el rendimiento (promedio de decenas de porcentaje) en consultas que no se pueden resolver mediante una simple búsqueda de índice único, p. la tabla se une. Sin embargo, tiene el potencial de ocultar datos/errores de aplicación.
Tengamos una mesa:
create table t (id number(10,0), padding varchar2(1000));
--intencionalmente no use PK para que el ejemplo sea lo más simple posible. El relleno se utiliza para simular la carga de datos reales en cada registro
con muchos registros:
insert into t (id, padding)
select rownum, rpad(' ', 1000) from dual connect by level < 10000
Ahora, si preguntas algo como
select 1 into ll_exists
from t where id = 5;
la base de datos debe recorrer toda la tabla, ya sea que haya encontrado el único registro coincidente en el primer bloque de datos (que, por cierto, no podemos saber porque podría insertarse de muchas maneras diferentes) o en el último. Eso es porque no sabe que solo hay un registro coincidente. Por otro lado, si usa ... y rownum =1, puede dejar de recorrer los datos después de encontrar el registro porque le dijo que no hay (o no se necesita) otro registro coincidente.
El inconveniente es que con la restricción de número de fila puede obtener resultados no deterministas si los datos contienen más de un registro posible. Si la consulta fue
select id into ll_id
from t where mod (id, 2) = 1
and rownum = 1;
entonces puedo recibir de DB la respuesta 1, así como la 3 y la 123 ... el orden no está garantizado y esta es la consecuencia. (sin la cláusula rownum obtendría una excepción TOO_MANY_ROWS. Depende de la situación, cuál es peor)
Si realmente quieres consultar qué prueba la existencia, ESCRIBELO DE ESA MANERA.
begin
select 'It does'
into ls_exists
from dual where
exists (your_original_query_without_rownum);
do_something_when_it_does_exist
exception
when no_data_found then
do_something_when_it_doesn't_exist
end;