Primero Reemplazaría esta subconsulta sofisticada:
Select Rownum seq_number From Dual Connect By Rownum <=
(Select LPAD(9,(UTC.DATA_PRECISION - UTC.DATA_SCALE),9)
From User_Tab_Columns UTC
where UTC.Table_Name = 'Table_Name' And UTC.Column_Name = 'seq_number')
con este:
Select Rownum As seq_number From Dual
Connect By Rownum <= (Select max( seq_number ) + 10 From TEMP_TABLE_NAME )
o incluso con una simple constante:
Select Rownum As seq_number From Dual Connect By Rownum <= 1000000
Francamente, su subconsulta no funciona para un caso muy básico:
create table TEMP_TABLE_NAME(
seq_number NUMBER
);
SELECT LPAD (9,(UTC.DATA_PRECISION - UTC.DATA_SCALE),9) as x ,
UTC.DATA_PRECISION, UTC.DATA_SCALE, UTC.COLUMN_NAME
FROM User_Tab_Columns UTC
WHERE UTC.Table_Name = 'TEMP_TABLE_NAME'
AND UTC.Column_Name = 'SEQ_NUMBER'
;
X DATA_PRECISION DATA_SCALE COLUMN_NAME
-------- -------------- ---------- -----------
(null) (null) (null) SEQ_NUMBER
Y un segundo caso:
create table TEMP_TABLE_NAME(
seq_number NUMBER(15,0)
);
en este caso, la subconsulta intenta generar 999999999999999 filas, lo que rápidamente genera un error de falta de memoria
SELECT count(*) FROM (
SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <=
(SELECT LPAD (9,(UTC.DATA_PRECISION - UTC.DATA_SCALE),9)
FROM User_Tab_Columns UTC
WHERE UTC.Table_Name = 'TEMP_TABLE_NAME'
AND UTC.Column_Name = 'SEQ_NUMBER')
);
ORA-30009: Not enough memory for CONNECT BY operation
30009. 0000 - "Not enough memory for %s operation"
*Cause: The memory size was not sufficient to process all the levels of the
hierarchy specified by the query.
*Action: In WORKAREA_SIZE_POLICY=AUTO mode, set PGA_AGGREGATE_TARGET to
a reasonably larger value.
Or, in WORKAREA_SIZE_POLICY=MANUAL mode, set SORT_AREA_SIZE to a
reasonably larger value.
En segundo lugar, su consulta no es determinista !!!
Depende en gran medida de la estructura de una tabla física y no impone el orden correcto usando ORDER BY cláusula.
Recuerde ->Wikipedia - ORDER BY
Considere este caso de prueba:
create table TEMP_TABLE_NAME
as SELECT * FROM (
select rownum as seq_number , t.*
from ALL_OBJECTS t
cross join ( select * from dual connect by level <= 10)
where rownum <= 100000
)
ORDER BY DBMS_RANDOM.Value;
create unique index TEMP_TABLE_NAME_IDX on TEMP_TABLE_NAME(seq_Number);
select count(*) from TEMP_TABLE_NAME;
COUNT(*)
----------
100000
DELETE FROM TEMP_TABLE_NAME
WHERE seq_number between 10000 and 10002
OR seq_number between 20000 and 20002
OR seq_number between 30000 and 30002
OR seq_number between 40000 and 40002
OR seq_number between 50000 and 50002
OR seq_number between 60000 and 60002
;
Si el índice existe, entonces el resultado es correcto:
SELECT T1.*
FROM ( SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <= 1000000
) T1,
TEMP_TABLE_NAME T2
WHERE T1.seq_number = T2.seq_number(+)
AND T2.ROWID IS NULL
AND ROWNUM <= 10
;
SEQ_NUMBER
----------
10000
10001
10002
20000
20001
20002
30000
30001
30002
40000
Pero, ¿qué sucede cuando algún día alguien elimina el índice o el optimizador por alguna razón decide no usar ese índice?
Según la definición:Sin ORDER BY, el sistema de base de datos relacional puede devolver las filas en cualquier orden. Simulo estos casos usando una pista:
SELECT /*+ NO_INDEX(T2) */ T1.*
FROM ( SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <= 1000000
) T1,
TEMP_TABLE_NAME T2
WHERE T1.seq_number = T2.seq_number(+)
AND T2.ROWID IS NULL
AND ROWNUM <= 10
;
SEQ_NUMBER
----------
213856
910281
668862
412743
295487
214762
788486
346216
777734
806457
La siguiente consulta impone un orden adecuado usando ORDER BY y da resultados reproductivos independientemente de que exista o no el índice adecuado. sintaxis.
SELECT * FROM (
SELECT /*+ NO_INDEX(T2) */ T1.*
FROM ( SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <= 1000000
) T1
LEFT JOIN TEMP_TABLE_NAME T2
ON T1.seq_number = T2.seq_number
WHERE T2.ROWID IS NULL
ORDER BY T1.seq_number
)
WHERE ROWNUM <= 10
Rendimiento
La forma más sencilla de comprobar el rendimiento es hacer una prueba:ejecutar la consulta de 10 a 100 veces y medir el tiempo:
SET TIMING ON;
DECLARE
x NUMBER;
BEGIN
FOR i IN 1..10 LOOP
SELECT sum( seq_number ) INTO x
FROM (
SELECT * FROM (
SELECT T1.*
FROM ( SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <= 1000000
) T1
LEFT JOIN TEMP_TABLE_NAME T2
ON T1.seq_number = T2.seq_number
WHERE T2.ROWID IS NULL
ORDER BY T1.seq_number
)
WHERE ROWNUM <= 10
);
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:11.750
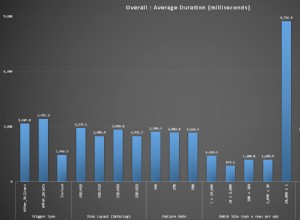
10 veces:11,75 segundos, por lo que una consulta tarda 1,2 segundos.
Y una próxima versión donde un límite en CONNECT BY utiliza una subconsulta:
SET TIMING ON;
DECLARE
x NUMBER;
BEGIN
FOR i IN 1..10 LOOP
SELECT sum( seq_number ) INTO x
FROM (
SELECT * FROM (
SELECT T1.*
FROM ( SELECT ROWNUM seq_number
FROM DUAL
CONNECT BY ROWNUM <= (Select max( seq_number ) + 10 From TEMP_TABLE_NAME )
) T1
LEFT JOIN TEMP_TABLE_NAME T2
ON T1.seq_number = T2.seq_number
WHERE T2.ROWID IS NULL
ORDER BY T1.seq_number
)
WHERE ROWNUM <= 10
);
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.986
Mucho mejor:solo 100 milisegundos.
Esto lleva a la conclusión de que CONECTAR POR parte es la más costosa.
Otro intento que usa una tabla con una secuencia de números pregenerada hasta 1 millón (tipo de vista materializada) en lugar de CONECTAR POR subconsulta que genera números cada vez sobre la marcha en la memoria:
create table seq(
seq_number int primary key
)
ORGANIZATION INDEX ;
INSERT INTO seq
SELECT level FROM dual
CONNECT BY LEVEL <= 1000000;
SET TIMING ON;
DECLARE
x NUMBER;
BEGIN
FOR i IN 1..10 LOOP
SELECT sum( seq_number ) INTO x
FROM (
SELECT * FROM (
SELECT T1.*
FROM seq T1
LEFT JOIN TEMP_TABLE_NAME T2
ON T1.seq_number = T2.seq_number
WHERE T2.ROWID IS NULL
ORDER BY T1.seq_number
)
WHERE ROWNUM <= 10
);
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.398
Este es el más rápido - solo 40 ms
El primero 1200 ms, el último 40 ms - 30 veces más rápido (3000 %).