Este es un problema bastante común.
B-Tree simple los índices no son buenos para consultas como esta:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Un índice es bueno para buscar los valores dentro de los límites dados, así:
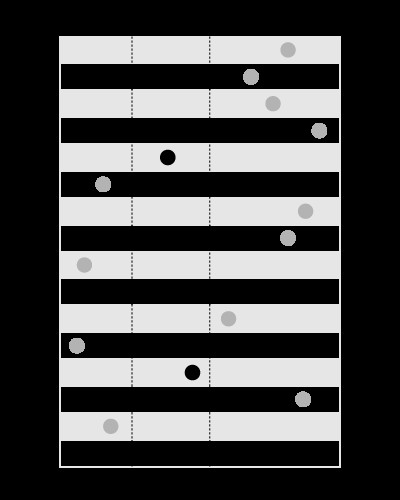
, pero no para buscar los límites que contienen el valor dado, así:
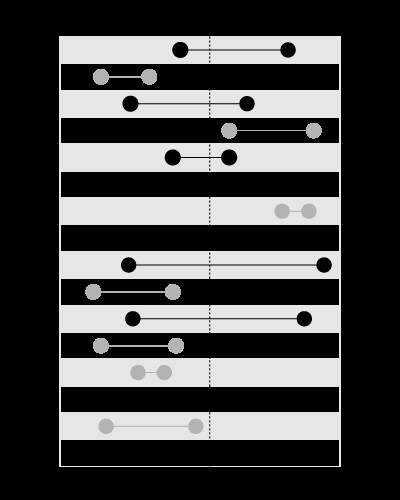
Este artículo en mi blog explica el problema con más detalle:
(el modelo de conjuntos anidados trata con el tipo similar de predicado).
Puedes hacer el índice en time , de esta forma los intervals liderará en la unión, el tiempo de rango se usará dentro de los bucles anidados. Esto requerirá ordenar en time .
Puede crear un índice espacial en intervals (disponible en MySQL usando MyISAM almacenamiento) que incluiría start y end en una columna de geometría. De esta forma, measures puede conducir en la unión y no será necesario ordenar.
Los índices espaciales, sin embargo, son más lentos, por lo que esto solo será eficiente si tiene pocas medidas pero muchos intervalos.
Dado que tiene pocos intervalos pero muchas medidas, solo asegúrese de tener un índice en measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Actualización:
Aquí hay un script de muestra para probar:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Esta consulta:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
usa NESTED LOOPS y regresa en 1.7 segundos.
Esta consulta:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
usa MERGE JOIN y tuve que detenerlo después de 5 minutos.
Actualización 2:
Lo más probable es que deba obligar al motor a usar el orden de tabla correcto en la unión usando una sugerencia como esta:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
El Oracle El optimizador de no es lo suficientemente inteligente como para ver que los intervalos no se cruzan. Es por eso que lo más probable es que use measures como mesa principal (lo que sería una buena decisión si los intervalos se cruzaran).
Actualización 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Esta consulta divide el eje de tiempo en rangos y usa un HASH JOIN para unir las medidas y las marcas de tiempo en los valores del rango, con un filtrado fino más adelante.
Consulte este artículo en mi blog para obtener explicaciones más detalladas sobre cómo funciona: