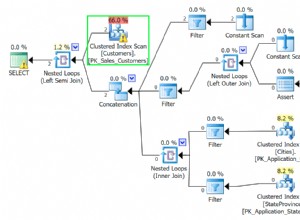
Mejorar las estadísticas. El número estimado de filas es 1, pero el número real de filas supera los 7 millones y sigue aumentando. Esto hace que el plan de ejecución utilice un bucle anidado en lugar de una unión hash. Un bucle anidado funciona mejor para pequeñas cantidades de datos y una unión hash funciona mejor para grandes cantidades de datos. Arreglar eso puede ser tan fácil como asegurarse de que las tablas relevantes tengan estadísticas actualizadas y precisas. Por lo general, esto se puede hacer recopilando estadísticas con la configuración predeterminada, por ejemplo:exec dbms_stats.gather_table_stats('SIRS_UATC1', 'TBL_RECON_PM'); .
Si eso no mejora la estimación de la cardinalidad, intente usar una sugerencia de muestreo dinámico, como /*+ dynamic_sampling(5) */ . Para una consulta tan prolongada, vale la pena dedicar un poco más de tiempo al muestreo de datos por adelantado si conduce a un mejor plan.
Utilice el paralelismo a nivel de declaración en lugar del paralelismo a nivel de objeto. Este es probablemente el error más común con SQL paralelo. Si usa paralelismo a nivel de objeto, la sugerencia debe hacer referencia al alias del objeto Desde 11gR2 no hay necesidad de preocuparse por especificar objetos. Esta declaración solo necesita una pista:INSERT /*+ PARALLEL(16) APPEND */ ... . Tenga en cuenta que NOLOGGING no es una pista real.