La indexación de Hive se introdujo en Hive 0.7.0 (HIVE-417) y se eliminó en Hive 3.0 (HIVE-18448). Lea los comentarios en este Jira. La función era completamente inútil en Hive. Estos índices eran demasiado caros para big data, RIP.
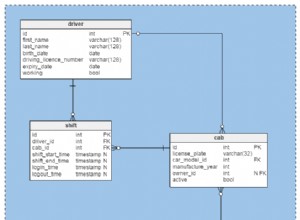
A partir de Hive 2.1.0 (HIVE-13290), Hive incluye compatibilidad con restricciones de clave principal y externa no validadas . Estas restricciones no están validadas, un sistema ascendente debe garantizar la integridad de los datos antes de cargarlos en Hive. Estas restricciones son útiles para las herramientas que generan consultas y diagramas ER. Además, tales restricciones no validadas son útiles como autodocumentación. Puede averiguar fácilmente qué se supone que es un PK si la tabla tiene tal restricción.
En la base de datos Oracle, las restricciones Unique, PK y FK están respaldadas con índices, por lo que pueden funcionar rápidamente y son realmente útiles. Pero no es así como funciona Hive ni para qué fue diseñado.
Un escenario bastante normal es cuando cargó un archivo muy grande con datos semiestructurados en HDFS. Crear un índice en él es demasiado costoso y sin un índice para verificar la violación de PK solo es posible escanear todos los datos. Y normalmente no puede imponer restricciones en BigData. El proceso ascendente puede cuidar la integridad y la consistencia de los datos, pero esto no garantiza que finalmente no tendrá una violación de PK en Hive en alguna tabla grande cargada desde diferentes fuentes.
Algunos formatos de almacenamiento de archivos como ORC tienen "índices" internos livianos para acelerar el filtrado y permitir la inserción de predicados (PPD), no se implementan restricciones de PK y FK utilizando dichos índices. Esto no se puede hacer porque normalmente puede tener muchos de estos archivos que pertenecen a la misma tabla en Hive y los archivos incluso pueden tener diferentes esquemas. Hive creado para petabytes y puede procesar petabytes en una sola ejecución, los datos pueden estar semiestructurados, los archivos pueden tener diferentes esquemas. Hadoop no admite escrituras aleatorias y esto agrega más complicaciones y costos si desea reconstruir índices.