Un desarrollador de Oracle que a menudo usa expresiones regulares en el código tarde o temprano puede enfrentarse a un fenómeno que es realmente místico. Las búsquedas a largo plazo de la raíz del problema pueden provocar pérdida de peso, apetito y provocar varios tipos de trastornos psicosomáticos; todo esto se puede prevenir con la ayuda de la función regexp_replace. Puede tener hasta 6 argumentos:
REGEXP_REPLACE (
- fuente_cadena,
- plantilla,
- sustituir_cadena,
- la posición de inicio de la búsqueda de coincidencias con una plantilla (predeterminada 1),
- una posición de aparición de la plantilla en una cadena de origen (de forma predeterminada, 0 equivale a todas las apariciones),
- modificador (hasta ahora es un caballo oscuro)
)
Devuelve la fuente_cadena modificada en la que todas las apariciones de la plantilla se reemplazan por el valor pasado en el parámetro cadena_sustituta. A menudo se usa una versión corta de la función, donde se especifican los primeros 3 argumentos, lo cual es suficiente para resolver muchos problemas. Voy a hacer lo mismo. Supongamos que necesitamos enmascarar todos los caracteres de la cadena con asteriscos en la cadena 'MÁSCARA:minúsculas'. Para especificar el rango de caracteres en minúsculas, el patrón '[a-z]' debería ser adecuado.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Expectativa
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realidad
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Si este evento no se ha reproducido en su base de datos, entonces tiene suerte hasta ahora. Pero lo más frecuente es que empieces a profundizar en el código, conviertas cadenas de un conjunto de caracteres a otro y, finalmente, llega la desesperación.
Definición de un problema
Surge la pregunta:¿qué tiene de especial la letra 'A' que no ha sido reemplazada porque se suponía que el resto de los caracteres en mayúsculas no debían reemplazarse también? Tal vez haya otras letras correctas excepto esta. Es necesario mirar todo el alfabeto de caracteres en mayúsculas.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Sin embargo
Si el sexto argumento de la función no se especifica explícitamente, por ejemplo, 'i' no distingue entre mayúsculas y minúsculas o 'c' distingue entre mayúsculas y minúsculas cuando se compara una cadena de origen con una plantilla, el la expresión regular usa el parámetro NLS_SORT de la sesión/base de datos de forma predeterminada. Por ejemplo:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Este parámetro especifica el método de clasificación en ORDER BY. Si hablamos de clasificar caracteres individuales simples, entonces un cierto número binario (código NLSSORT) corresponde a cada uno de ellos y la clasificación realmente se lleva a cabo por el valor de estos números.
Para ilustrar esto, tomemos los primeros y últimos caracteres del alfabeto, tanto en minúsculas como en mayúsculas, y colóquelos en un conjunto de tablas condicionalmente desordenado y llámelo ABC. Luego, clasifiquemos este conjunto por el campo SÍMBOLO y mostremos su código NLSSORT en formato HEX al lado de cada símbolo.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
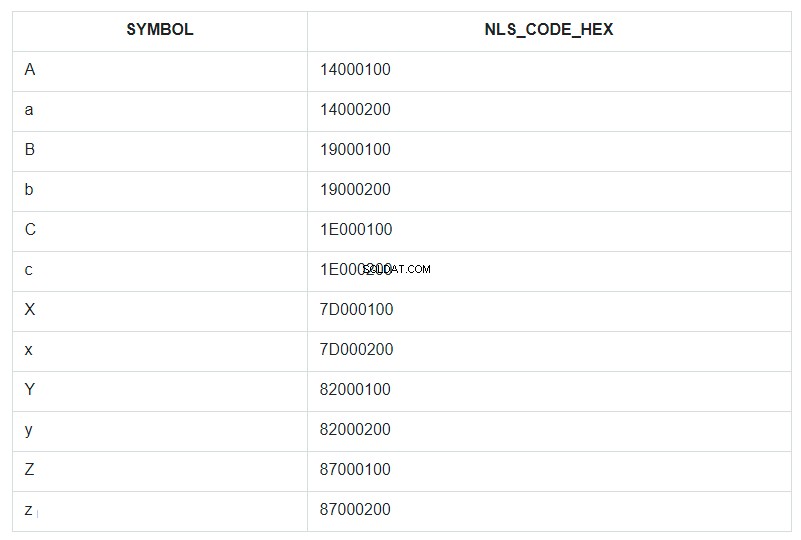
En la consulta, se especifica ORDER BY para el campo SYMBOL, pero de hecho, en la base de datos, la ordenación fue por los valores del campo NLS_CODE_HEX.
Ahora, regrese al rango de la plantilla y mire la tabla:¿cuál es la vertical entre el símbolo 'a' (código 14000200) y 'z' (código 87000200)? Todo excepto la letra mayúscula 'A'. Eso es todo lo que ha sido reemplazado con un asterisco. Y el código 14000100 de la letra 'A' no está incluido en el rango de reemplazo de 14000200 a 87000200.
Cura
Especifique explícitamente el modificador de distinción entre mayúsculas y minúsculas
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Algunas fuentes dicen que el modificador 'c' está configurado de forma predeterminada, pero acabamos de ver que esto no es del todo cierto. Y si alguien no lo vio, lo más probable es que el parámetro NLS_SORT de su sesión/base de datos esté configurado en BINARIO y la clasificación se realice en correspondencia con códigos de caracteres reales. De hecho, si cambia el parámetro de sesión, el problema se resolverá.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Las pruebas se realizaron en Oracle 12c.
Siéntete libre de dejar tus comentarios y cuidarte.