Esta publicación es parte del tutorial de Oracle SQL y estaríamos discutiendo las funciones analíticas en Oracle (por partición) con ejemplos, explicación detallada.
Ya hemos estudiado sobre la función Oracle Aggregate como avg, sum, count. Tomemos un ejemplo
Primero vamos a crear los datos de muestra
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Ahora el ejemplo de funciones agregadas se dará a continuación
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Aquí podemos ver que reduce el número de filas en cada una de las consultas. Ahora viene la pregunta de qué hacer si necesitamos que todas las filas se devuelvan con conteo (*) también
Para ese oráculo ha proporcionado un conjunto de funciones analíticas. Entonces, para resolver el último problema, podemos escribir como
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
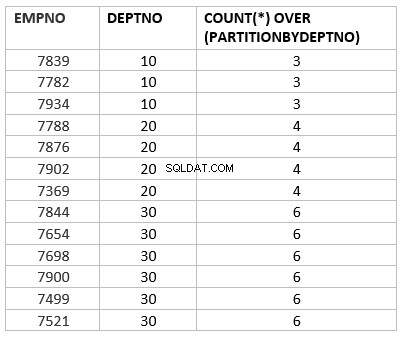
Aquí count(*) over (partición por dept_no) es la versión analítica de la función agregada de conteo. El trabajo clave principal que es diferente según la función agregada es sobre la partición por
Las funciones analíticas calculan un valor agregado basado en un grupo de filas. Se diferencian de las funciones agregadas en que devuelven varias filas para cada grupo. El grupo de filas se denomina ventana y está definido por la cláusula_analítica.
Aquí está la sintaxis general
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Ejemplo
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Repasemos cada parte
cláusula_partición_consulta
Definía el grupo de filas. Puede gustar a continuación
partición por deptno :grupo de filas del mismo deptno
o
() :Todas las filas
SQL> select empno ,deptno , count(*) over () from emp;
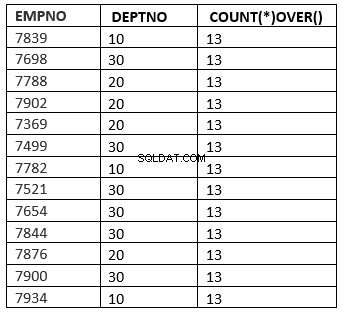
[ order_by_clause [ windowing_clause ] ]
Esta cláusula se usa cuando desea ordenar las filas en la partición. Esto es particularmente útil si desea que la función analítica considere el orden de las filas.
El ejemplo será la función número_fila
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
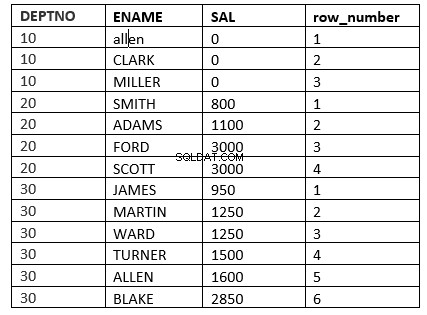
Otro ejemplo sería
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
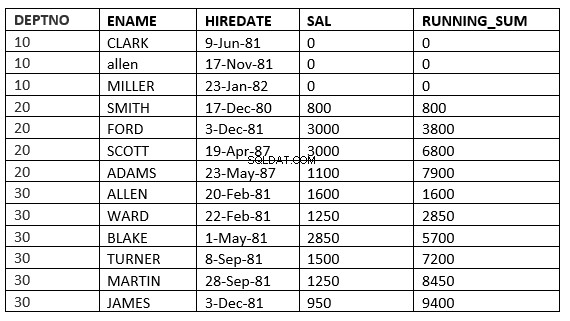
Cláusula_ventana
Esto siempre se usa con la cláusula order by y da más control sobre el conjunto de filas en el grupo
Con la cláusula Windowing, para cada fila, se define una ventana deslizante de filas. La ventana determina el rango de filas utilizadas para realizar los cálculos para la fila actual. Los tamaños de ventana se pueden basar en un número físico de filas o en un intervalo lógico como el tiempo.
Cuando se usa la cláusula order by y no se proporciona nada para la cláusula_ventana, se toma el valor predeterminado de la cláusula_ventana
RANGO ENTRE LA FILA PRECEDENTE SIN LÍMITES Y LA FILA ACTUAL o RANGO PRECEDENTE SIN LÍMITES
Significa "Las filas actual y anterior en la fila actual". partición son las filas que deben usarse en el cálculo”
El siguiente ejemplo lo establece claramente. Este es el promedio móvil en el departamento
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
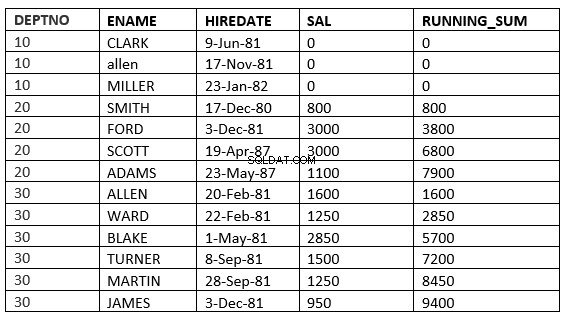
Ahora windowing_clause se puede definir de varias maneras
Primero comprendamos la terminología
FILAS especifica la ventana en unidades físicas (filas).
RANGO especifica la ventana como un desplazamiento lógico. la cláusula de ventana RANGE solo se puede usar con cláusulas ORDER BY que contienen columnas o expresiones de tipos de datos numéricos o de fecha
ANTERIOR – obtener filas antes de la actual.
SIGUIENTE – obtener filas después de la actual.
SIN LÍMITES – cuando se usa con PRECEDING o FOLLOWING, devuelve todo antes o después. FILA ACTUAL
Por lo tanto, generalmente se define como
FILAS PRECEDENTES ILIMITADAS :Las filas actuales y anteriores en la partición actual son las filas que deben usarse en el cálculo
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
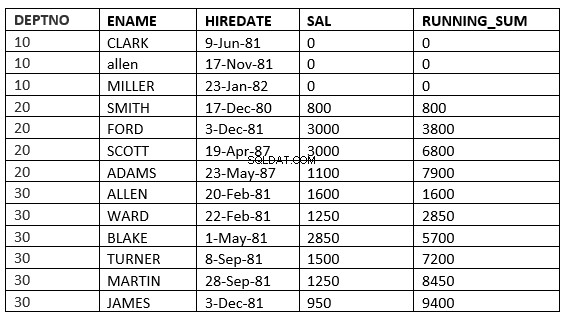
RANGO ILIMITADO PRECEDENTE :Las filas actual y anterior en la partición actual son las filas que deben usarse en el cálculo. Además, dado que se especifica el rango, todo toma los valores que son iguales a las filas actuales.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
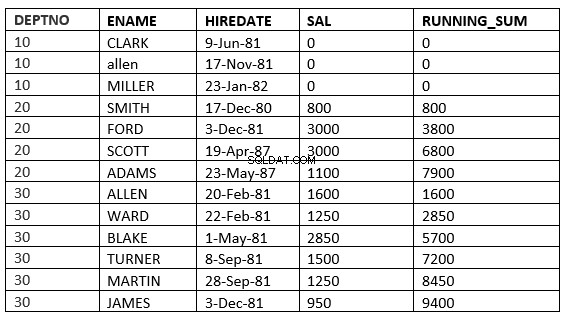
Es posible que no vea la diferencia entre el rango y las filas, ya que la fecha_contratación es diferente para todos. La diferencia será más clara si usamos sal como cláusula order by
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
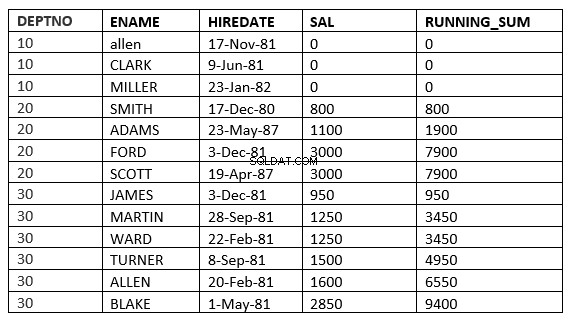
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
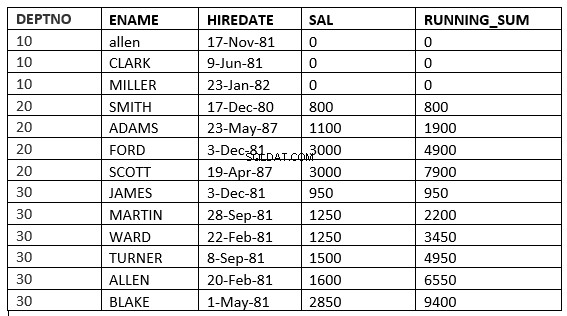
Puede encontrar la diferencia en la línea 6
RANGO value_expr PRECEDENTE :La ventana comienza con la fila cuyo valor ORDER BY es filas de expresión numérica anteriores o anteriores a la fila actual y finaliza con la fila actual que se está procesando.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
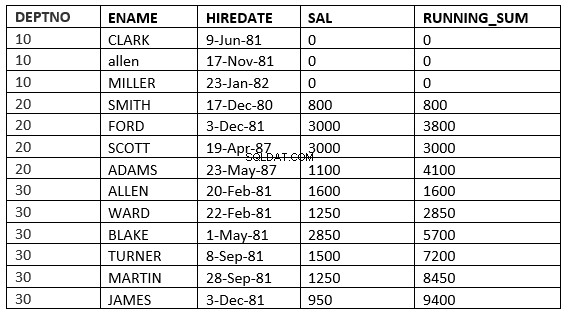
Aquí toma todas las filas en las que el valor de la fecha de contratación se encuentra dentro de los 365 días anteriores al valor de la fecha de contratación de la fila actual
FILAS valor_expr PRECEDENTES :La ventana comienza con la fila dada y termina con la fila actual procesada
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
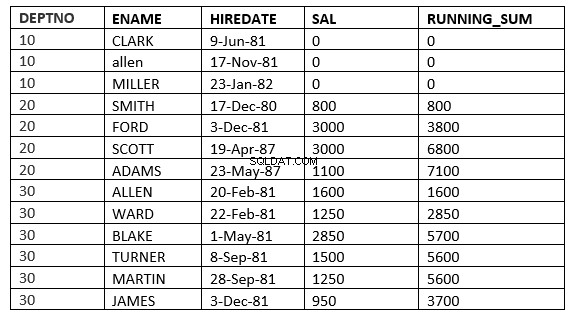
Aquí la ventana comienza desde 2 filas que preceden a la fila actual
RANGO ENTRE LA FILA ACTUAL y value_expr SIGUIENTE :La ventana comienza con la fila actual y termina con la fila cuyo valor ORDER BY es filas de expresión numérica menores que o siguientes
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
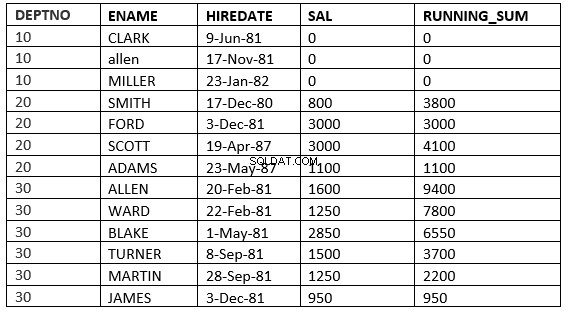
FILAS ENTRE LA FILA ACTUAL y value_expr SIGUIENTE :La ventana comienza con la fila actual y termina con las filas posteriores a la actual
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
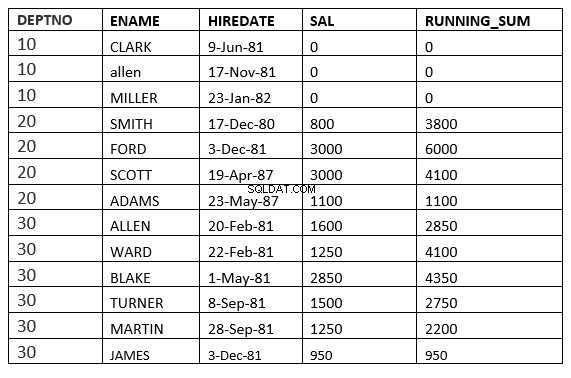
RANGO ENTRE PRECEDENTE SIN LÍMITES y SIGUIENTE SIN LÍMITES
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
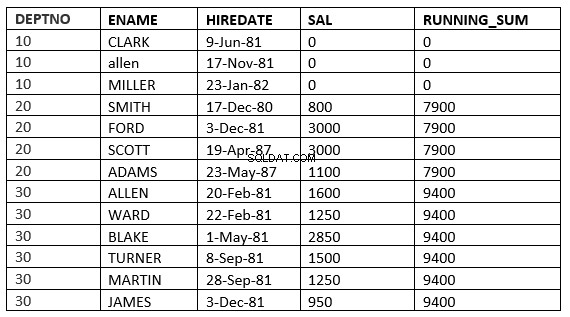
RANGO ENTRE value_expr PRECEDENTE y value_expr SIGUIENTE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Algunas notas importantes
(1)Las funciones analíticas son el último conjunto de operaciones realizadas en una consulta, excepto la cláusula ORDER BY final. Todas las uniones y todas las cláusulas WHERE, GROUP BY y HAVING se completan antes de que se procesen las funciones analíticas. Por lo tanto, las funciones analíticas solo pueden aparecer en la lista de selección o en la cláusula ORDER BY.
(2) Las funciones analíticas se usan comúnmente para calcular agregados acumulativos, móviles, centrados y de generación de informes.
Espero que les guste esta explicación detallada de las funciones analíticas en Oracle (sobre la cláusula de partición)
Artículos relacionados
Función LEAD en Oracle
Función DENSE en Oracle
Función Oracle LISTAGG
Agregación de datos mediante funciones de grupo
https://docs.oracle.com/cd/E11882_01/ servidor.112/e41084/funciones004.htm