No hay un límite codificado relevante (65 536 * Tamaño de paquete de red de 4 KB es 268 MB y la longitud de su secuencia de comandos no se acerca a eso), aunque no es recomendable usar este método para una gran cantidad de filas.
El error que está viendo lo arrojan las herramientas del cliente, no SQL Server. Si construye la cadena SQL en SQL dinámico, la compilación puede al menos comenzar con éxito
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Aunque eliminé lo anterior después de ~ 30 minutos de tiempo de compilación y todavía no había producido una fila. Los valores literales deben almacenarse dentro del propio plan como una tabla de constantes y SQL Server gasta mucho tiempo tratando de derivar propiedades sobre ellos también.
SSMS es una aplicación de 32 bits y lanza un std::bad_alloc excepción al analizar el lote
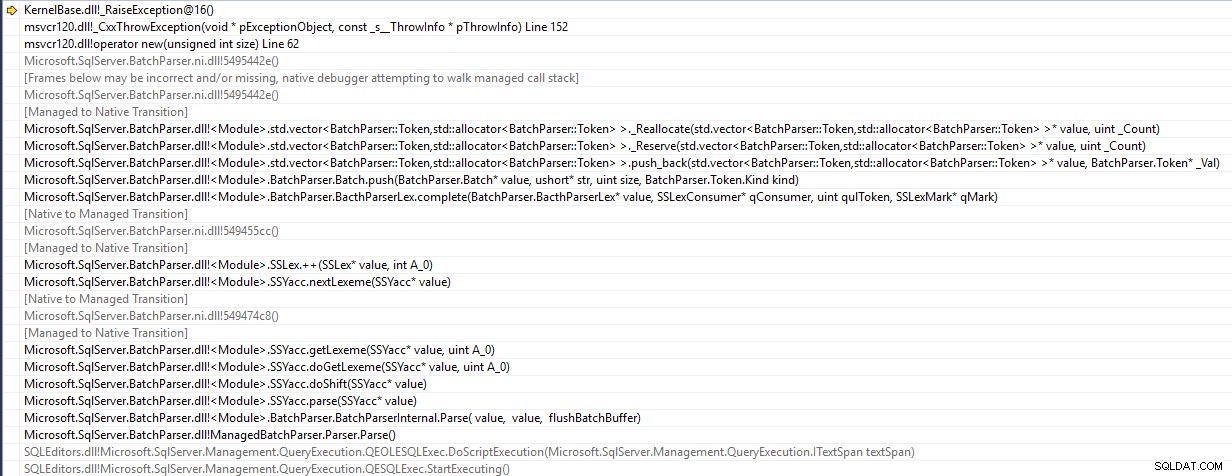
Intenta insertar un elemento en un vector de Token que ha alcanzado su capacidad y su intento de cambiar el tamaño falla debido a la falta de disponibilidad de un área de memoria contigua lo suficientemente grande. Entonces, la declaración nunca llega al servidor.
La capacidad del vector crece un 50 % cada vez (es decir, siguiendo la secuencia aquí ). La capacidad a la que el vector necesita crecer depende de cómo esté diseñado el código.
Lo siguiente necesita crecer de una capacidad de 19 a 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
y el siguiente solo necesita un tamaño de 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Lo siguiente necesita una capacidad de> 63 y <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
Para un millón de filas dispuestas como en el caso 1, la capacidad del vector debe aumentar a 3 543 306.
Puede encontrar que cualquiera de los siguientes permitirá que el análisis del lado del cliente tenga éxito.
- Reduzca el número de saltos de línea.
- Reiniciar SSMS con la esperanza de que la solicitud de memoria contigua grande tenga éxito cuando haya menos fragmentación del espacio de direcciones.
Sin embargo, incluso si lo envía con éxito al servidor, solo terminará matando al servidor durante la generación del plan de ejecución de todos modos, como se discutió anteriormente.
Será mucho mejor usar el asistente de importación y exportación para cargar la tabla. Si debe hacerlo en TSQL, encontrará que dividirlo en lotes más pequeños y/o usar otro método, como triturar XML, funcionará mejor que los constructores de valores de tabla. Lo siguiente se ejecuta en 13 segundos en mi máquina, por ejemplo (aunque si usa SSMS, es probable que tenga que dividirlo en varios lotes en lugar de pegar una cadena literal XML masiva).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)