Estas pruebas (base de datos AdventureWorks2008R2) muestran lo que sucede:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Resultados:
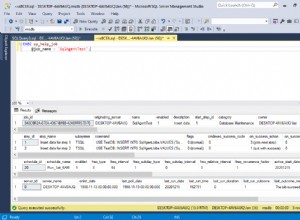
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Los resultados de SET STATISTICS IO muestra que LIO son lo mismo .Pero los planes de ejecución son bastante diferentes: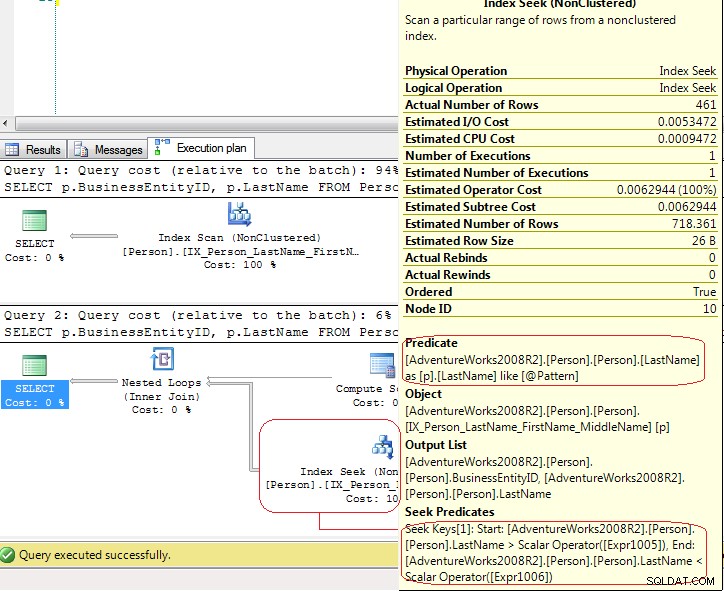
En la primera prueba, SQL Server usa un Index Scan explícito pero en la segunda prueba SQL Server usa un Index Seek que es un Index Seek - range scan . En el último caso, SQL Server usa un Compute Scalar operador para generar estos valores
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
y, la Index Seek el operador usa un Seek Predicate (optimizado) para un range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) más otro Predicate no optimizado (LastName LIKE @pattern ).
Mi respuesta:no es una Index Seek "real" . Es un Index Seek - range scan que, en este caso, tiene el mismo rendimiento que Index Scan .
Consulte también la diferencia entre Index Seek y Index Scan (debate similar):Entonces... ¿es una búsqueda o un escaneo?
.
Edición 1: El plan de ejecución para OPTION(RECOMPILE) (vea la recomendación de Aaron por favor) muestra, también, un Index Scan (en lugar de Index Seek ):