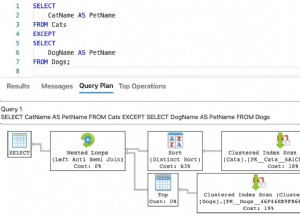
Los índices de texto completo solo consideran los caracteres _ y ` mientras se indexa. Todos los demás caracteres se ignoran y las palabras se dividen donde aparecen estos caracteres. Esto se debe principalmente a que los índices de texto completo están diseñados para indexar documentos grandes y solo se consideran las palabras adecuadas para que sea una búsqueda más refinada.
Nos enfrentamos a un problema similar. Para resolver esto, en realidad teníamos una tabla de traducción, donde caracteres como @,-, fueron reemplazadas con secuencias especiales como '`at` ','`guión` ','`barra diagonal` ', etc. Mientras busca en el texto completo, debe reemplazar nuevamente sus caracteres en la cadena de búsqueda con estas secuencias especiales y buscar. Esto debería ocuparse de los caracteres especiales.