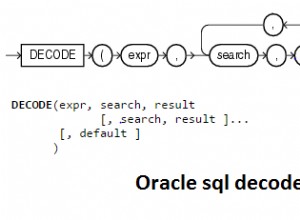
Si puede obtener sus datos en el formato de un par clave/valor por fila, gran parte del trabajo está hecho. Déjame llamar a ese resultado t . Algo como esto podría ayudarte el resto del camino:
select max(case when LEFT(data, 4) = 'key1' then SUBSTRING(data, 6, len(data)) end) as key1,
MAX(case when LEFT(data, 4) = 'key2' then SUBSTRING(data, 6, len(data)) end) as key2,
MAX(case when LEFT(data, 4) = 'key2' then SUBSTRING(data, 6, len(data)) end) as key3
from t
group by (id - 1)/3
Esto supone que el id se asigna secuencialmente, como se muestra en su ejemplo.