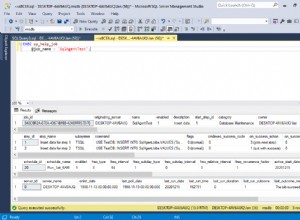
Podrías hacer algo peor que mirar la GEOGRAPHY tipo de datos, por ejemplo:
CREATE TABLE Places
(
SeqID INT IDENTITY(1,1),
Place NVARCHAR(20),
Location GEOGRAPHY
)
GO
INSERT INTO Places (Place, Location) VALUES ('Coventry', geography::Point(52.4167, -1.55, 4326))
INSERT INTO Places (Place, Location) VALUES ('Sheffield', geography::Point(53.3667, -1.5, 4326))
INSERT INTO Places (Place, Location) VALUES ('Penzance', geography::Point(50.1214, -5.5347, 4326))
INSERT INTO Places (Place, Location) VALUES ('Brentwood', geography::Point(52.6208, 0.3033, 4326))
INSERT INTO Places (Place, Location) VALUES ('Inverness', geography::Point(57.4760, -4.2254, 4326))
GO
SELECT p1.Place, p2.place, p1.location.STDistance(p2.location) / 1000 AS DistanceInKilometres
FROM Places p1
CROSS JOIN Places p2
GO
SELECT p1.Place, p2.place, p1.location.STDistance(p2.location) / 1000 AS DistanceInKilometres
FROM Places p1
INNER JOIN Places p2 ON p1.SeqID > p2.SeqID
GO
geography::Point toma la latitud y la longitud, así como un SRID (Número de identificación de referencia especial). En este caso, el SRID es 4326, que es la latitud y longitud estándar. Como ya tiene la latitud y la longitud, puede simplemente ALTER TABLE para agregar la columna de geografía, luego UPDATE para llenarlo.
He mostrado dos formas de sacar los datos de la tabla, sin embargo, no puede crear una vista indexada con esto (las vistas indexadas no pueden tener uniones automáticas). Sin embargo, podría crear una tabla secundaria que sea efectivamente un caché, que se complete en función de lo anterior. Luego, solo tiene que preocuparse por mantenerlo (se puede hacer a través de disparadores o algún otro proceso).
Tenga en cuenta que la unión cruzada le dará 250 000 000 000 filas, pero la búsqueda es simple ya que solo necesita mirar una de las columnas de lugares (es decir, SELECT * FROM table WHERE Place1 = 'Sheffield' AND distance < 100 , el segundo le dará significativamente menos filas, pero la consulta debe considerar tanto la columna Place1 como Place2).