Pivotar es muy parecido a agrupar. Podría verlo como una agrupación limitada con un "efecto especial". La limitación consiste en que sólo puede haber una sola columna agregada. (En la consulta normal GROUP BY, puede tener más de una, naturalmente). Y por el 'efecto especial' quiero decir, por supuesto, que una de las otras columnas (y, de nuevo, solo una) se transforma en múltiples columnas.
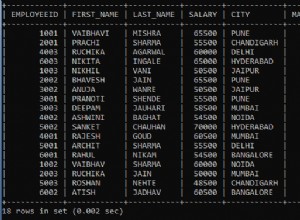
Tomemos su consulta GROUP BY como ejemplo. Tienes tres columnas en la salida. Uno de ellos, Count , es la misma columna que contiene información agregada. Ese es el que estaría disperso entre varias columnas en una consulta PIVOT. Otra columna, Priority , es una de las otras dos columnas por las que se agrupan los resultados y también la que se debe pivotar. Finalmente, EntryDate es la otra columna GROUP BY. Simplemente debe permanecer como está, porque no participa directamente en el pivote.
Veamos ahora cómo su SELECT principal se transforma de una consulta GROUP BY habitual a una consulta PIVOT, paso a paso:
-
Dado que la agrupación está implícita en una consulta PIVOT, se elimina la cláusula GROUP BY. En su lugar, se introduce una cláusula PIVOT.
-
El
Countla expresión de la columna se mueve de la cláusula SELECT a la cláusula PIVOT. -
La división de la
Priorityla columna se define en la cláusula PIVOT. -
La
PriorityyCountlas columnas de la cláusula SELECT se reemplazan por la lista de las columnas definidas en la cláusula PIVOT. -
La
EntryDatela columna permanece sin cambios en la cláusula SELECT.
Y aquí está la consulta resultante, con comentarios que marcan cada parte de la transformación descrita anteriormente:
WITH TATH(Priority, EntryDate) AS
(
SELECT TH.Priority as Priority, DATEADD(dd, 0, DATEDIFF(dd, 0, entryDate)) as EntryDate
FROM TicketAssignment TA, TicketHeader TH
WHERE TA.TicketID = TH.TicketID
AND TA.Company = 'IT'
AND TA.CurrentRole IN ('SA1B','SA1C','SDA')
)
SELECT
convert(varchar(10), EntryDate,103) as EntryDate, -- #5
[0] AS Priority0, [1] AS Priority1, [2] AS Priority2, [3] AS Priority3 -- #4
FROM TATH
PIVOT ( -- #1
COUNT(*) -- #2
FOR Priority IN ([0], [1], [2], [3]) -- #3
) p
/* -- your original main query, for comparison
SELECT
Priority, -- #4
convert(varchar(10), -- #5
EntryDate,103) as EntryDate, COUNT(*) AS Count -- ##2&4
FROM TATH
GROUP BY Priority, EntryDate -- #1
*/
Hay una nota adicional en la lista de columnas en la cláusula PIVOT. En primer lugar, debe comprender que se supone que el conjunto resultante de una consulta SQL es fijo en términos de la cantidad de columnas y sus nombres. Eso significa que debe enumerar explícitamente todas las columnas transformadas que desea ver en la salida. Los nombres se derivan de los valores de la columna que se está dinamizando, pero deben especificarse como nombres , no como valores. Es por eso que puede ver corchetes alrededor de los números enumerados. Dado que los números en sí mismos no cumplen las reglas para identificadores regulares , deben estar delimitados.
También puede ver que puede asignar un alias a las columnas pivoteadas en la cláusula SELECT como cualquier otra columna o expresión. Entonces, al final, no tienes que terminar con el 0 sin sentido , 1 etc. identificadores y, en su lugar, puede asignar a esas columnas los nombres que desee.
Si desea que el número y/o los nombres de las columnas dinámicas sean dinámicos, deberá crear la consulta dinámicamente, es decir, recopilar primero los nombres y luego incorporarlos en una cadena que contenga el resto de la consultar e invocar la consulta final con EXEC () o EXEC sp_executesql . Puede buscar en este sitio
para obtener más información sobre el pivote dinámico.