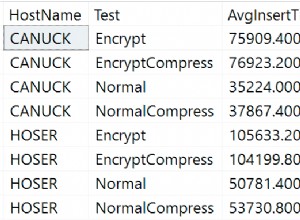
DECLARE @Data TABLE (ID INTEGER, X INTEGER, Y INTEGER)
INSERT @Data VALUES (1,1,1),(2,1,2),(3,1,2),(4,1,3),(5,1,3),
(6,2,4),(7,2,5),(8,2,5),(9,2,5),(10,3,1),(11,3,10),(12,3,10)
;WITH CTE AS
(
SELECT ID, X, Y,
ROW_NUMBER() OVER(PARTITION BY X ORDER BY Y DESC, ID ASC) AS RowNo
FROM @Data
)
SELECT ID, X, Y FROM CTE WHERE RowNo = 1
Entonces, usando ROW_NUMBER() para asignar a cada fila un número incremental que se restablece a 1 para cada nuevo valor de X. Para las filas con el mismo valor para X, el número de fila se asigna incrementalmente ordenado por Y DESCENDENTE e ID ASCENDENTE; por lo tanto, para un valor X en particular, el número de fila 1 se asignará al que tenga el valor MÁS ALTO de Y y el valor de ID MÁS BAJO. Luego agregamos una restricción para devolver solo aquellos donde RowNo es 1.