Espero haberlo entendido correctamente. Así que repetiré.
- Tienes 1 tabla con muchas entradas
- Tienes esta lista de Excel donde buscas la "columna de búsqueda"
- En caso de coincidencia, reemplace el valor completo con "reemplazar columna"
Si este es el caso, entonces esta podría ser la solución:
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
La tabla "datos" sería en la que haces el reemplazo.
Puede haber bastantes efectos secundarios al usar eso (por ejemplo, comodines como % en "columna_búsqueda", tal vez múltiples coincidencias; en este momento se toma una "aleatoria", el rendimiento podría no ser el mejor, ...) Pero supongo que para una respuesta más precisa necesitaría una mejor pregunta.
Editar:
Gracias a Ralph... Agregué una prioridad a la tabla "reemplazar" para poder manejar coincidencias duplicadas.
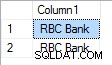
En caso de que "RBC" tenga prioridad 3, el resultado es:
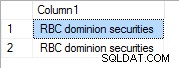
Con una prioridad de 1 es: