Puedes hacerlo usando un OR :
WHERE (@Id > 0 AND Table1.Field = @Id)
OR (@Id = 0 AND Table1.Field IN (6,16,18))
Sin embargo, recomendaría usar (como ha dicho) IF/ELSE , cuando combina dos condiciones como esta, a menudo puede forzar planes subóptimos. por ejemplo, en su ejemplo, podría simplificar esto a un esquema de la siguiente manera:
CREATE TABLE T
( ID INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Field INT NOT NULL,
SomeOtherField INT NULL
);
GO
INSERT T (Field)
SELECT Number
FROM Master..spt_values
CROSS JOIN (VALUES (1), (2), (3)) t (A)
WHERE Type = 'P'
GO
CREATE NONCLUSTERED INDEX IX_T_Field ON T (Field) INCLUDE (SomeOtherField);
Esto simplemente llena una de las columnas con los números 0-2047 repetidos 4 veces cada uno (solo para algunos datos de ejemplo). Entonces, si creo dos procedimientos, uno que usa 'IF/ELSE' y otro que combina los criterios anteriores:
CREATE PROCEDURE dbo.Test @ID INT
AS
SELECT ID, Field, SomeOtherField
FROM T
WHERE (@Id > 0 AND T.Field = @Id)
OR (@Id = 0 AND T.Field IN (6,16,18))
GO
CREATE PROCEDURE dbo.Test2 @ID INT
AS
IF @ID = 0
SELECT ID, Field, SomeOtherField
FROM T
WHERE T.Field IN (6, 16, 18)
ELSE
SELECT ID, Field, SomeOtherField
FROM T
WHERE T.Field = @Id
GO
Dado que la compilación de consultas solo ocurrirá una vez (a menos que usted indique explícitamente lo contrario), el optimizador no elegirá un plan diferente dependiendo de si pasa 0 o pasa una ID> 0 al procedimiento, por lo tanto, ambos de los siguientes:
EXECUTE dbo.Test 0;
EXECUTE dbo.Test 1;
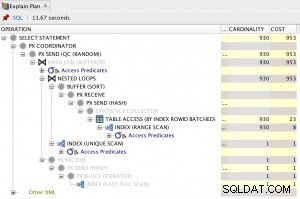
Dará este plan:

El segundo procedimiento es capaz de estimar mucho mejor el mejor plan de ejecución, por lo que ejecuta esto:
EXECUTE dbo.Test2 0;
EXECUTE dbo.Test2 1;
Da el siguiente plan:

Los ejemplos del mundo real obviamente variarán, y he construido deliberadamente un ejemplo que prueba mi punto. Es un poco más difícil duplicar una gran cantidad de código usando IF/ELSE , pero a menudo vale la pena.