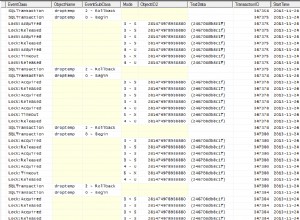
Probé algunos SELECT COUNT(*) FROM MyTable vs. SELECT COUNT(SomeColumn) FROM MyTable con varios tamaños de tablas, y donde SomeColumn una vez es una columna de clave de agrupación, una vez está en un índice no agrupado y una vez no está en ningún índice.
En todos los casos, con todos los tamaños de tablas (desde 300'000 filas hasta 170 millones de filas), nunca veo ninguna diferencia en términos de velocidad o plan de ejecución - en todos los casos, el COUNT se maneja haciendo un escaneo de índice agrupado -> es decir, escaneando toda la tabla, básicamente. Si hay un índice no agrupado involucrado, entonces el escaneo está en ese índice, incluso cuando se hace SELECT COUNT(*) !
No parece haber ninguna diferencia en términos de velocidad o enfoque de cómo se cuentan esas cosas; para contarlas todas, SQL Server solo necesita escanear toda la tabla, punto.
Las pruebas se realizaron en SQL Server 2008 R2 Developer Edition