Supongo que la razón es que simplemente no han considerado esta característica prioritaria que valga la pena implementar. Parece que Postgres sí apoyar a ambos
UNION y UNION ALL .
Si tiene un caso sólido para esta función, puede proporcionar comentarios en Connect (o cualquiera que sea la URL de su reemplazo).
Evitar que se agreguen duplicados podría ser útil, ya que una fila duplicada agregada en un paso posterior a uno anterior casi siempre terminará causando un bucle infinito o excediendo el límite máximo de recurrencia.
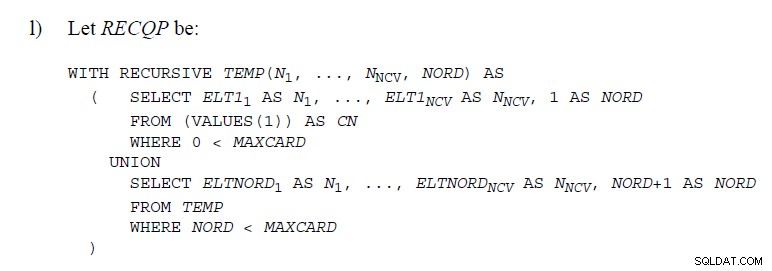
Hay bastantes lugares en los Estándares SQL
donde se usa código demostrando UNION como a continuación
Mientras tanto, puede lograr fácilmente lo mismo en un TVF de varias declaraciones.
Para tomar un ejemplo tonto a continuación (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Cambiando la UNION a UNION ALL y agregando un DISTINCT al final no te salvará de la recursividad infinita.
Pero puedes implementar esto como
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Lo anterior usa IGNORE_DUP_KEY para descartar duplicados. Si la lista de columnas es demasiado amplia para indexarla, necesitará DISTINCT y NOT EXISTS en cambio. Probablemente también desee un parámetro para establecer el número máximo de recurrencias y evitar bucles infinitos.