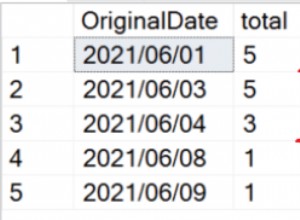
Ya que está en SQL Server 2012... aquí hay una versión que usa eso. Puede que sea más rápido que otras soluciones, pero debe probarlo en sus datos.
sum() over() hará una suma acumulada ordenada por Id agregando 1 cuando hay un valor en la columna y se mantiene el valor actual para null valores. La suma acumulada calculada se usa luego para dividir el resultado en first_value() over() . El primer valor ordenado por Id para cada "grupo" de filas generadas por la suma acumulada tiene el valor que desea.
select T.Id,
first_value(T.FeeModeId)
over(partition by T.NF
order by T.Id
rows between unbounded preceding and current row) as FeeModeId,
first_value(T.Name)
over(partition by T.NS
order by T.Id
rows between unbounded preceding and current row) as Name,
T.Amount
from (
select Id,
FeeModeId,
Name,
Amount,
sum(case when FeeModeId is null then 0 else 1 end)
over(order by Id) as NF,
sum(case when Name is null then 0 else 1 end)
over(order by Id) as NS
from YourTable
) as T
Algo que funcionará antes de SQL Server 2012:
select T1.Id,
T3.FeeModeId,
T2.Name,
T1.Amount
from YourTable as T1
outer apply (select top(1) Name
from YourTable as T2
where T1.Id >= T2.Id and
T2.Name is not null
order by T2.Id desc) as T2
outer apply (select top(1) FeeModeId
from YourTable as T3
where T1.Id >= T3.Id and
T3.FeeModeId is not null
order by T3.Id desc) as T3