La búsqueda de datos de cadena para una coincidencia de subcadena arbitraria puede ser una operación costosa en SQL Server. Consultas del formulario Column LIKE '%match%' no puede usar las capacidades de búsqueda de un índice de árbol b, por lo que el procesador de consultas tiene que aplicar el predicado a cada fila individualmente. Además, cada prueba debe aplicar correctamente el conjunto completo de reglas de colación complicadas. Al combinar todos estos factores, no sorprende que este tipo de búsquedas requieran muchos recursos y sean lentas.
La búsqueda de texto completo es una herramienta poderosa para la coincidencia lingüística, y la búsqueda semántica estadística más nueva es excelente para encontrar documentos con significados similares. Pero a veces, realmente solo necesita encontrar cadenas que contengan una subcadena en particular, una subcadena que puede que ni siquiera sea una palabra, en cualquier idioma.
Si los datos buscados no son grandes o los requisitos de tiempo de respuesta no son críticos, use LIKE '%match%' bien podría ser una solución adecuada. Pero, en las raras ocasiones en las que la necesidad de una búsqueda superrápida supere todas las demás consideraciones (incluido el espacio de almacenamiento), puede considerar una solución personalizada utilizando n-gramas. La variación específica explorada en este artículo es un trigrama de tres caracteres.
Búsqueda con comodines usando trigramas
La idea básica de una búsqueda de trigramas es bastante simple:
- Persistir subcadenas de tres caracteres (trigramas) de los datos de destino.
- Divida los términos de búsqueda en trigramas.
- Hacer coincidir los trigramas de búsqueda con los trigramas almacenados (búsqueda de igualdad)
- Intersecta las filas calificadas para encontrar cadenas que coincidan con todos los trigramas
- Aplicar el filtro de búsqueda original a la intersección muy reducida
Trabajaremos con un ejemplo para ver exactamente cómo funciona todo esto y cuáles son las ventajas y desventajas.
Tabla de muestra y datos
El siguiente script crea una tabla de ejemplo y la completa con un millón de filas de datos de cadena. Cada cadena tiene 20 caracteres, siendo los primeros 10 caracteres numéricos. Los 10 caracteres restantes son una combinación de números y letras de la A a la F, generados con NEWID() . No hay nada terriblemente especial en estos datos de muestra; la técnica del trigrama es bastante general.
-- The test table
CREATE TABLE dbo.Example
(
id integer IDENTITY NOT NULL,
string char(20) NOT NULL,
CONSTRAINT [PK dbo.Example (id)]
PRIMARY KEY CLUSTERED (id)
);
GO
-- 1 million rows
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1 * 1000 * 1000)
-- 10 numeric characters
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
-- plus 10 mixed numeric + [A-F] characters
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
OPTION (MAXDOP 1); Tarda alrededor de 3 segundos para crear y completar los datos en mi modesta computadora portátil. Los datos son pseudoaleatorios, pero como indicación se verá así:
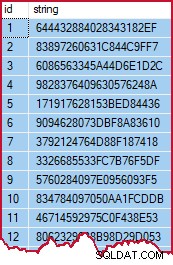
Muestra de datos
Generando trigramas
La siguiente función en línea genera distintos trigramas alfanuméricos a partir de una cadena de entrada determinada:
--- Generate trigrams from a string
CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING
AS RETURN
WITH
N16 AS
(
SELECT V.v
FROM
(
VALUES
(0),(0),(0),(0),(0),(0),(0),(0),
(0),(0),(0),(0),(0),(0),(0),(0)
) AS V (v)),
-- Numbers table (256)
Nums AS
(
SELECT n = ROW_NUMBER() OVER (ORDER BY A.v)
FROM N16 AS A
CROSS JOIN N16 AS B
),
Trigrams AS
(
-- Every 3-character substring
SELECT TOP (CASE WHEN LEN(@string) > 2 THEN LEN(@string) - 2 ELSE 0 END)
trigram = SUBSTRING(@string, N.n, 3)
FROM Nums AS N
ORDER BY N.n
)
-- Remove duplicates and ensure all three characters are alphanumeric
SELECT DISTINCT
T.trigram
FROM Trigrams AS T
WHERE
-- Binary collation comparison so ranges work as expected
T.trigram COLLATE Latin1_General_BIN2 NOT LIKE '%[^A-Z0-9a-z]%'; Como ejemplo de su uso, la siguiente llamada:
SELECT
GT.trigram
FROM dbo.GenerateTrigrams('SQLperformance.com') AS GT; Produce los siguientes trigramas:

Trigramas de SQLperformance.com
El plan de ejecución es una traducción bastante directa de T-SQL en este caso:
- Generación de filas (unión cruzada de escaneos constantes)
- Numeración de filas (Proyecto de segmento y secuencia)
- Limitación de los números necesarios en función de la longitud de la cadena (Arriba)
- Eliminar trigramas con caracteres no alfanuméricos (Filtro)
- Eliminar duplicados (ordenación distinta)

Plan de generación de trigramas
Cargando los trigramas
El siguiente paso es conservar los trigramas para los datos de ejemplo. Los trigramas se mantendrán en una nueva tabla, completada con la función en línea que acabamos de crear:
-- Trigrams for Example table
CREATE TABLE dbo.ExampleTrigrams
(
id integer NOT NULL,
trigram char(3) NOT NULL
);
GO
-- Generate trigrams
INSERT dbo.ExampleTrigrams WITH (TABLOCKX)
(id, trigram)
SELECT
E.id,
GT.trigram
FROM dbo.Example AS E
CROSS APPLY dbo.GenerateTrigrams(E.string) AS GT; Eso toma alrededor de 20 segundos para ejecutar en mi instancia de computadora portátil SQL Server 2016. Esta ejecución en particular produjo 17,937,972 filas de trigramas para el millón de filas de datos de prueba de 20 caracteres. El plan de ejecución esencialmente muestra el plan de funciones que se está evaluando para cada fila de la tabla Ejemplo:
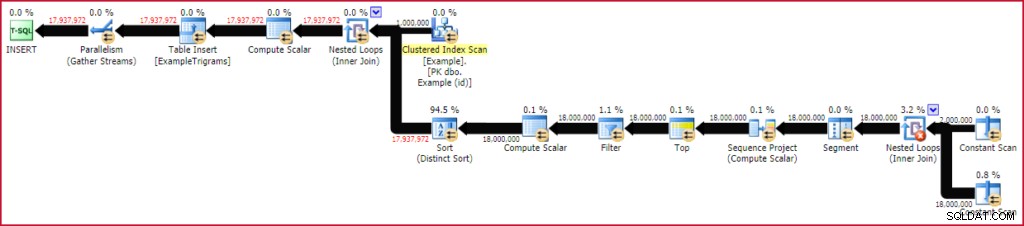
Poblando la tabla de trigramas
Dado que esta prueba se realizó en SQL Server 2016 (cargando una tabla heap, con un nivel de compatibilidad de base de datos 130 y con un TABLOCK sugerencia), el plan se beneficia de la inserción paralela. Las filas se distribuyen entre subprocesos mediante el escaneo paralelo de la tabla Ejemplo y permanecen en el mismo subproceso a partir de entonces (sin intercambios de partición).
El operador Ordenar puede parecer un poco imponente, pero los números muestran el número total de filas ordenadas, sobre todas las iteraciones de la combinación de bucle anidado. De hecho, hay un millón de tipos separados, de 18 filas cada uno. Con un grado de paralelismo de cuatro (dos núcleos hiperprocesos en mi caso), hay un máximo de cuatro ordenaciones diminutas en un momento dado, y cada instancia de ordenación puede reutilizar la memoria. Esto explica por qué el uso máximo de memoria de este plan de ejecución es de apenas 136 KB. (aunque se otorgaron 2152 KB).
La tabla de trigramas contiene una fila para cada trigrama distinto en cada fila de la tabla de origen (identificado por id ):
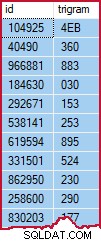
Ejemplo de tabla de trigramas
Ahora creamos un índice de árbol b agrupado para admitir la búsqueda de coincidencias de trigramas:
-- Trigram search index
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigrams (trigram, id)]
ON dbo.ExampleTrigrams (trigram, id)
WITH (DATA_COMPRESSION = ROW); Esto toma alrededor de 45 segundos , aunque algo de eso se debe al tipo de derrame (mi instancia está limitada a 4 GB de memoria). Una instancia con más memoria disponible probablemente podría completar ese índice paralelo mínimamente registrado un poco más rápido.
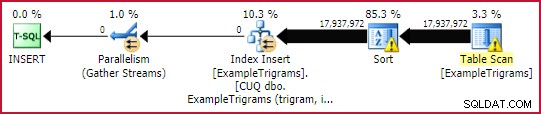
Plan de construcción de índice
Observe que el índice se especifica como único (usando ambas columnas en la clave). Podríamos haber creado un índice agrupado no único en el trigrama solo, pero SQL Server habría agregado uniquificadores de 4 bytes a casi todas las filas de todos modos. Una vez que tenemos en cuenta que los uniquificadores se almacenan en la parte de longitud variable de la fila (con la sobrecarga asociada), tiene más sentido incluir id en la llave y listo.
Se especifica la compresión de filas porque reduce de manera útil el tamaño de la tabla de trigramas de 277 MB a 190 MB. (a modo de comparación, la tabla de ejemplo es de 32 MB). Si al menos no usa SQL Server 2016 SP1 (donde la compresión de datos estuvo disponible para todas las ediciones), puede omitir la cláusula de compresión si es necesario.
Como optimización final, también crearemos una vista indexada sobre la tabla de trigramas para que sea rápido y fácil encontrar qué trigramas son los más y los menos comunes en los datos. Este paso se puede omitir, pero se recomienda para el rendimiento.
-- Selectivity of each trigram (performance optimization)
CREATE VIEW dbo.ExampleTrigramCounts
WITH SCHEMABINDING
AS
SELECT ET.trigram, cnt = COUNT_BIG(*)
FROM dbo.ExampleTrigrams AS ET
GROUP BY ET.trigram;
GO
-- Materialize the view
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigramCounts (trigram)]
ON dbo.ExampleTrigramCounts (trigram); 
Plano de construcción con vista indexada
Esto solo toma un par de segundos en completarse. El tamaño de la vista materializada es pequeño, solo 104 KB .
Búsqueda de trigramas
Dada una cadena de búsqueda (por ejemplo, '%find%this%' ), nuestro enfoque será:
- Generar el conjunto completo de trigramas para la cadena de búsqueda
- Use la vista indexada para encontrar los tres trigramas más selectivos
- Encuentra los ID que coinciden con todos los trigramas disponibles
- Recuperar las cadenas por id
- Aplicar el filtro completo a las filas calificadas por trigramas
Encontrar trigramas selectivos
Los dos primeros pasos son bastante sencillos. Ya tenemos una función para generar trigramas para una cadena arbitraria. Se puede encontrar el más selectivo de esos trigramas uniéndose a la vista indexada. El siguiente código envuelve la implementación de nuestra tabla de ejemplo en otra función en línea. Gira los tres trigramas más selectivos en una sola fila para facilitar su uso más adelante:
-- Most selective trigrams for a search string
-- Always returns a row (NULLs if no trigrams found)
CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING AS
RETURN
SELECT
-- Pivot
trigram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.trigram END),
trigram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.trigram END),
trigram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.trigram END)
FROM
(
-- Generate trigrams for the search string
-- and choose the most selective three
SELECT TOP (3)
rn = ROW_NUMBER() OVER (
ORDER BY ETC.cnt ASC),
GT.trigram
FROM dbo.GenerateTrigrams(@string) AS GT
JOIN dbo.ExampleTrigramCounts AS ETC
WITH (NOEXPAND)
ON ETC.trigram = GT.trigram
ORDER BY
ETC.cnt ASC
) AS BT; Como ejemplo:
SELECT
EGBT.trigram1,
EGBT.trigram2,
EGBT.trigram3
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT; devuelve (para mis datos de muestra):
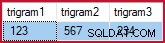
Trigramas seleccionados
El plan de ejecución es:
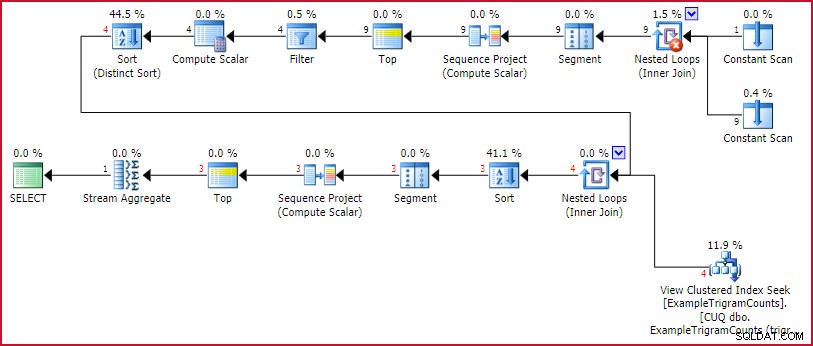
Plan de ejecución GetBestTrigrams
Este es el plan familiar de generación de trigramas de antes, seguido de una búsqueda en la vista indexada para cada trigrama, ordenando por el número de coincidencias, numerando las filas (Proyecto de secuencia), limitando el conjunto a tres filas (Arriba), luego girando el resultado (Stream Aggregate).
Encontrar ID que coincidan con todos los trigramas
El siguiente paso es encontrar los identificadores de fila de la tabla de ejemplo que coincidan con todos los trigramas no nulos recuperados en la etapa anterior. El problema aquí es que podemos tener cero, uno, dos o tres trigramas disponibles. La siguiente implementación envuelve la lógica necesaria en una función de declaración múltiple, devolviendo los identificadores de calificación en una variable de tabla:
-- Returns Example ids matching all provided (non-null) trigrams
CREATE FUNCTION dbo.Example_GetTrigramMatchIDs
(
@Trigram1 char(3),
@Trigram2 char(3),
@Trigram3 char(3)
)
RETURNS @IDs table (id integer PRIMARY KEY)
WITH SCHEMABINDING AS
BEGIN
IF @Trigram1 IS NOT NULL
BEGIN
IF @Trigram2 IS NOT NULL
BEGIN
IF @Trigram3 IS NOT NULL
BEGIN
-- 3 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
INTERSECT
SELECT ET3.id
FROM dbo.ExampleTrigrams AS ET3
WHERE ET3.trigram = @Trigram3
OPTION (MERGE JOIN);
END;
ELSE
BEGIN
-- 2 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
OPTION (MERGE JOIN);
END;
END;
ELSE
BEGIN
-- 1 trigram available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1;
END;
END;
RETURN;
END; El plan de ejecución estimado para esta función muestra la estrategia:
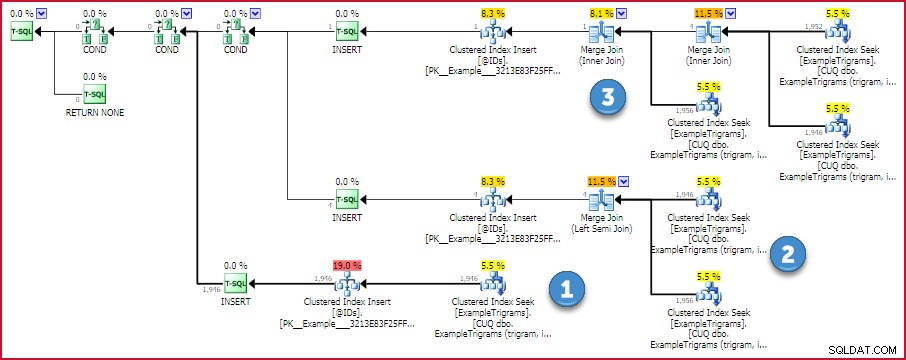
Plan de ID de coincidencia de trigramas
Si hay un trigrama disponible, se realiza una única búsqueda en la tabla de trigramas. De lo contrario, se realizan dos o tres búsquedas y se encuentra la intersección de los identificadores utilizando una combinación eficiente de uno a muchos. No hay operadores que consumen memoria en este plan, por lo que no hay posibilidad de un hash o un derrame de clasificación.
Continuando con la búsqueda del ejemplo, podemos encontrar identificadores que coincidan con los trigramas disponibles aplicando la nueva función:
SELECT EGTMID.id
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT
CROSS APPLY dbo.Example_GetTrigramMatchIDs
(EGBT.trigram1, EGBT.trigram2, EGBT.trigram3) AS EGTMID; Esto devuelve un conjunto como el siguiente:

ID coincidentes
El plan real (posterior a la ejecución) para la nueva función muestra la forma del plan con tres entradas de trigrama que se utilizan:
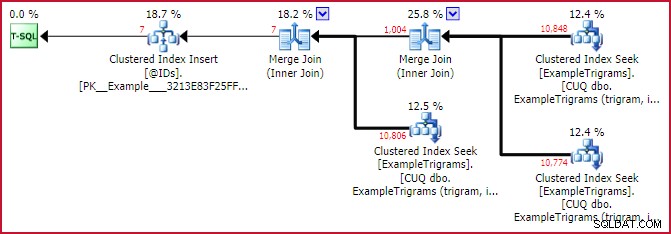
Plan de coincidencia de ID real
Esto muestra bastante bien el poder de la combinación de trigramas. Aunque cada uno de los tres trigramas identifica alrededor de 11 000 filas en la tabla Ejemplo, la primera intersección reduce este conjunto a 1004 filas y la segunda intersección lo reduce a solo 7. .
Implementación completa de búsqueda de trigramas
Ahora que tenemos los identificadores que coinciden con los trigramas, podemos buscar las filas coincidentes en la tabla Ejemplo. Todavía necesitamos aplicar la condición de búsqueda original como verificación final, porque los trigramas pueden generar falsos positivos (pero no falsos negativos). El último problema a abordar es que las etapas anteriores pueden no haber encontrado ningún trigrama. Esto podría deberse, por ejemplo, a que la cadena de búsqueda contiene muy poca información. Una cadena de búsqueda de '%FF%' no puede usar la búsqueda de trigramas porque dos caracteres no son suficientes para generar ni siquiera un solo trigrama. Para manejar este escenario correctamente, nuestra búsqueda detectará esta condición y recurrirá a una búsqueda sin trigramas.
La siguiente función en línea final implementa la lógica requerida:
-- Search implementation
CREATE FUNCTION dbo.Example_TrigramSearch
(
@Search varchar(255)
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
Result.string
FROM dbo.Example_GetBestTrigrams(@Search) AS GBT
CROSS APPLY
(
-- Trigram search
SELECT
E.id,
E.string
FROM dbo.Example_GetTrigramMatchIDs
(GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID
JOIN dbo.Example AS E
ON E.id = MID.id
WHERE
-- At least one trigram found
GBT.trigram1 IS NOT NULL
AND E.string LIKE @Search
UNION ALL
-- Non-trigram search
SELECT
E.id,
E.string
FROM dbo.Example AS E
WHERE
-- No trigram found
GBT.trigram1 IS NULL
AND E.string LIKE @Search
) AS Result;
La característica clave es la referencia externa a GBT.trigram1 en ambos lados de la UNION ALL . Estos se traducen en filtros con expresiones de puesta en marcha en el plan de ejecución. Un filtro de inicio solo ejecuta su subárbol si su condición se evalúa como verdadera. El efecto neto es que solo se ejecutará una parte de la unión, dependiendo de si encontramos un trigrama o no. La parte relevante del plan de ejecución es:
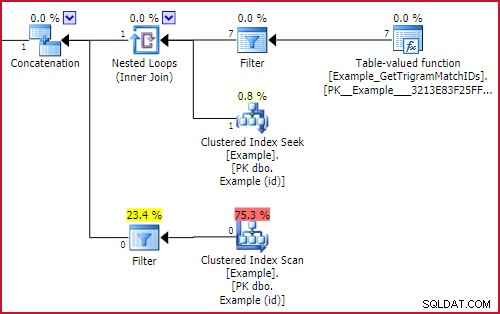
Efecto de filtro de inicio
O el Example_GetTrigramMatchIDs se ejecutará la función (y los resultados se buscarán en el ejemplo usando una búsqueda en id), o el escaneo de índice agrupado del ejemplo con un LIKE residual el predicado se ejecutará, pero no ambos.
Rendimiento
El siguiente código prueba el rendimiento de la búsqueda de trigramas contra el equivalente LIKE :
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT F2.string
FROM dbo.Example AS F2
WHERE
F2.string LIKE '%1234%5678%'
OPTION (MAXDOP 1);
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
GO
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%1234%5678%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Ambos producen la(s) misma(s) fila(s) de resultados pero el LIKE la consulta se ejecuta durante 2100 ms , mientras que la búsqueda de trigramas tarda 15 ms .
Es posible un rendimiento aún mejor. En general, el rendimiento mejora a medida que los trigramas se vuelven más selectivos y menos numerosos (por debajo del máximo de tres en esta implementación). Por ejemplo:
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%BEEF%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Esa búsqueda devolvió 111 filas a la cuadrícula SSMS en 4 ms . El LIKE corrió equivalente para 1950ms .
Manteniendo los trigramas
Si la tabla de destino es estática, obviamente no hay problema para mantener sincronizadas la tabla base y la tabla de trigramas relacionada. Del mismo modo, si no se requiere que los resultados de la búsqueda estén completamente actualizados en todo momento, una actualización programada de la(s) tabla(s) de trigramas puede funcionar bien.
De lo contrario, podemos usar algunos disparadores bastante simples para mantener los datos de búsqueda de trigramas sincronizados con las cadenas subyacentes. La idea general es generar trigramas para filas eliminadas e insertadas, luego agregarlos o eliminarlos en la tabla de trigramas según corresponda. Los activadores de inserción, actualización y eliminación a continuación muestran esta idea en la práctica:
-- Maintain trigrams after Example inserts
CREATE TRIGGER MaintainTrigrams_AI
ON dbo.Example
AFTER INSERT
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END; -- Maintain trigrams after Example deletes
CREATE TRIGGER MaintainTrigrams_AD
ON dbo.Example
AFTER DELETE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
END; -- Maintain trigrams after Example updates
CREATE TRIGGER MaintainTrigrams_AU
ON dbo.Example
AFTER UPDATE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END;
Los disparadores son bastante eficientes y manejarán cambios de una sola fila y de varias filas (incluidas las múltiples acciones disponibles cuando se usa un MERGE declaración). SQL Server mantendrá automáticamente la vista indexada sobre la tabla de trigramas sin que tengamos que escribir ningún código de activación.
Operación de activación
Como ejemplo, ejecute una instrucción para eliminar una fila arbitraria de la tabla Ejemplo:
-- Single row delete DELETE TOP (1) dbo.Example;
El plan de ejecución posterior a la ejecución (real) incluye una entrada para el activador posterior a la eliminación:
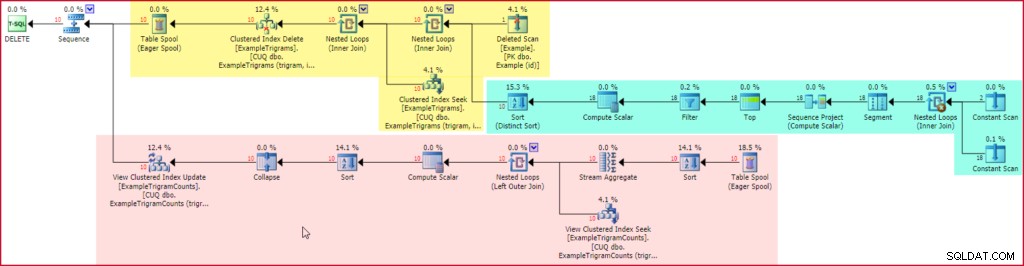
Eliminar plan de ejecución de activadores
La sección amarilla del plan lee las filas de los eliminados pesudo-table, genera trigramas para cada cadena de ejemplos eliminada (usando el plan familiar resaltado en verde), luego localiza y elimina las entradas de la tabla de trigramas asociadas. SQL Server agrega automáticamente la sección final del plan, que se muestra en rojo, para mantener actualizada la vista indexada.
El plan para el disparador de inserción es extremadamente similar. Las actualizaciones se manejan realizando una eliminación seguida de una inserción. Ejecute el siguiente script para ver estos planes y confirme que las filas nuevas y actualizadas se pueden ubicar mediante la función de búsqueda de trigramas:
-- Single row insert
INSERT dbo.Example (string)
VALUES ('SQLPerformance.com');
-- Find the new row
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%perf%') AS ETS;
-- Single row update
UPDATE TOP (1) dbo.Example
SET string = '12345678901234567890';
-- Multi-row insert
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1000)
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1;
-- Multi-row update
UPDATE TOP (1000) dbo.Example
SET string = '12345678901234567890';
-- Search for the updated rows
SELECT ETS.string
FROM dbo.Example_TrigramSearch('12345678901234567890') AS ETS; Ejemplo de fusión
El siguiente script muestra un MERGE instrucción que se utiliza para insertar, eliminar y actualizar la tabla de ejemplo a la vez:
-- MERGE demo
DECLARE @MergeData table
(
id integer UNIQUE CLUSTERED NULL,
operation char(3) NOT NULL,
string char(20) NULL
);
INSERT @MergeData
(id, operation, string)
VALUES
(NULL, 'INS', '11223344556677889900'), -- Insert
(1001, 'DEL', NULL), -- Delete
(2002, 'UPD', '00000000000000000000'); -- Update
DECLARE @Actions table
(
action$ nvarchar(10) NOT NULL,
old_id integer NULL,
old_string char(20) NULL,
new_id integer NULL,
new_string char(20) NULL
);
MERGE dbo.Example AS E
USING @MergeData AS MD
ON MD.id = E.id
WHEN MATCHED AND MD.operation = 'DEL'
THEN DELETE
WHEN MATCHED AND MD.operation = 'UPD'
THEN UPDATE SET E.string = MD.string
WHEN NOT MATCHED AND MD.operation = 'INS'
THEN INSERT (string) VALUES (MD.string)
OUTPUT $action, Deleted.id, Deleted.string, Inserted.id, Inserted.string
INTO @Actions (action$, old_id, old_string, new_id, new_string);
SELECT * FROM @Actions AS A; La salida mostrará algo como:

Resultado de la acción
Reflexiones finales
Tal vez haya cierto alcance para acelerar las operaciones de actualización y eliminación de gran tamaño al hacer referencia a los identificadores directamente en lugar de generar trigramas. Esto no se implementa aquí porque requeriría un nuevo índice no agrupado en la tabla de trigramas, duplicando el espacio de almacenamiento (ya significativo) utilizado. La tabla de trigramas contiene un solo entero y un char(3) por fila; un índice no agrupado en la columna de enteros obtendría el char(3) columna en todos los niveles (cortesía del índice agrupado y la necesidad de que las claves de índice sean únicas en cada nivel). También hay que tener en cuenta el espacio de memoria, ya que las búsquedas de trigramas funcionan mejor cuando todas las lecturas son de caché.
El índice adicional haría que la integridad referencial en cascada fuera una opción, pero eso a menudo es más problemático de lo que vale.
La búsqueda de trigramas no es una panacea. Los requisitos de almacenamiento adicionales, la complejidad de la implementación y el impacto en el rendimiento de las actualizaciones pesan mucho en su contra. La técnica tampoco sirve para búsquedas que no generan trigramas (mínimo 3 caracteres). Aunque la implementación básica que se muestra aquí puede manejar muchos tipos de búsqueda (comienza con, contiene, termina con múltiples comodines), no cubre todas las posibles expresiones de búsqueda que se pueden hacer para trabajar con LIKE . Funciona bien para cadenas de búsqueda que generan trigramas de tipo AND; se necesita más trabajo para manejar las cadenas de búsqueda que requieren manejo de tipo OR u opciones más avanzadas como expresiones regulares.
Dicho todo esto, si su aplicación realmente debe tenga búsquedas rápidas de cadenas comodín, los n-gramas son algo a considerar seriamente.
Contenido relacionado:Una forma de obtener una búsqueda de índice para un %comodín líder por Aaron Bertrand.