Hace unas semanas, hice un gran alboroto sobre el Service Pack 1 de SQL Server 2016. Muchas funciones que antes estaban reservadas para Enterprise Edition se lanzaron a ediciones inferiores, y me encantó conocer estos cambios.
No obstante, veo algunas personas que están, digamos, un poco menos emocionadas que yo.
Es importante tener en cuenta que los cambios aquí no estaban destinados a proporcionar una paridad completa de funciones en todas las ediciones; tenían el propósito específico de crear un área de superficie de programación más consistente. Ahora los clientes pueden usar funciones como In-Memory OLTP, Columnstore y compresión sin preocuparse por las ediciones objetivo, solo por lo bien que escalarán. También se abren varias características de seguridad que realmente no parecían tener nada que ver con la edición. El que menos entendí fue Always Encrypted; No podía entender por qué solo los clientes de Enterprise necesitaban proteger cosas como los datos de la tarjeta de crédito. El Cifrado de datos transparente sigue siendo solo para empresas, en versiones anteriores a SQL Server 2019, porque esta no es realmente una función de programación (ya sea que esté activada o no).
Entonces, ¿cuál es realmente el beneficio para los clientes de la Edición estándar?
Creo que el mayor problema que tiene la mayoría de la gente es que la memoria máxima en la Edición estándar todavía está limitada a 128 GB. Miran eso y dicen:"Vaya, gracias por todas las funciones, pero el límite de memoria significa que realmente no puedo usarlas".
Sin embargo, los cambios en el área superficial generan oportunidades de mejora del rendimiento, incluso si esa no fuera su intención original (o incluso si lo fuera, yo no estuve en ninguna de esas reuniones). Echemos un vistazo más de cerca a una pequeña sección de la letra pequeña (de los documentos oficiales):
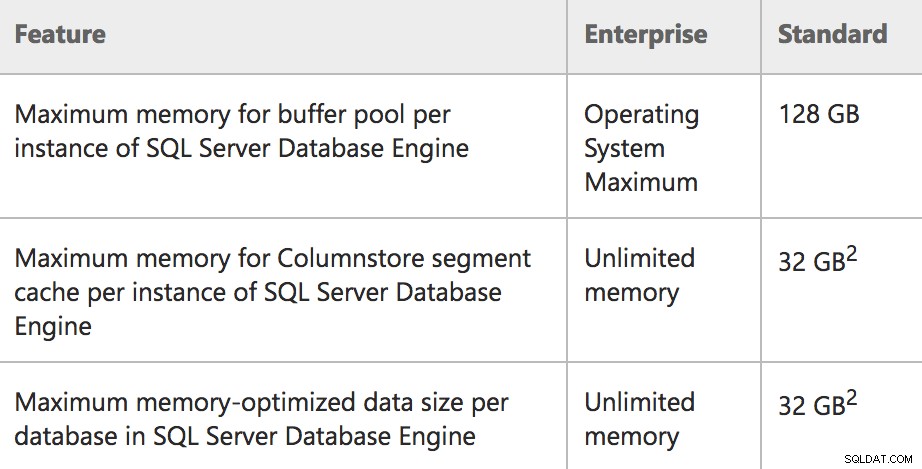 Límites de memoria para Enterprise/Standard en SQL Server 2016 SP1
Límites de memoria para Enterprise/Standard en SQL Server 2016 SP1
El lector astuto notará que la redacción del límite del grupo de búfer ha cambiado, de:
Memoria:memoria máxima utilizada por instanciaPara:
Memoria:tamaño máximo del grupo de búfer por instanciaEsta es una mejor descripción de lo que realmente sucede en la Edición estándar:un límite de 128 GB solo para el grupo de búfer, y otras reservas de memoria pueden estar por encima de eso (piense en grupos como el caché del plan). Entonces, en efecto, un servidor Standard Edition podría usar 128 GB de grupo de búfer, luego la memoria máxima del servidor podría ser mayor y admitir más memoria utilizada para otras reservas. Del mismo modo, Express Edition ahora está correctamente documentado para usar 1,4 GB para el grupo de búfer.
También puede notar una redacción muy específica en esa columna más a la izquierda (por ejemplo, "por instancia" y "por base de datos") para las funciones que se exponen en la Edición estándar por primera vez. Para ser más específicos:
- La instancia está limitada a 128 GB de memoria para el grupo de búfer .
- La instancia puede tener un adicional 32 GB asignados a objetos de almacén de columnas, por encima del límite del grupo de búfer.
- Cada base de datos de usuario en la instancia puede tener una adicional 32 GB asignados a tablas optimizadas para memoria, por encima del límite del grupo de búfer.
Y para que quede claro:Estos límites de memoria para ColumnStore e In-Memory OLTP NO se restan del límite del grupo de búfer , siempre que el servidor tenga más de 128 GB de memoria disponible. Si el servidor tiene menos de 128 GB, verá que estas tecnologías compiten con la memoria del grupo de búfer y, de hecho, se limitan a un % de la memoria máxima del servidor. Hay más detalles disponibles en esta publicación de Parikshit Savjani de Microsoft.
No tengo hardware a mano para probar el alcance de esto, pero si tuviera una máquina con 256 GB o 512 GB de memoria, teóricamente podría usarlo todo con una sola instancia de Standard Edition, si pudiera, por ejemplo, distribuir su In -Memoria de datos en bases de datos en <=fragmentos de 32 GB, para un total de 128 GB + (32 GB * (# de bases de datos)). Si quisiera usar ColumnStore en lugar de In-Memory, podría distribuir sus datos en varias instancias, lo que le daría (128 GB + 32 GB) * (cantidad de instancias). Y podría combinar estas estrategias para ((128 GB + 32 GB de ColumnStore) * (# de instancias)) + (32 GB en memoria * (# de bases de datos * # de instancias)).
Si dividir sus datos de esta manera es práctico para su aplicación, no estoy seguro; Sólo estoy sugiriendo que es posible. Es posible que algunos de ustedes ya estén haciendo algunas de estas cosas para obtener un mejor uso de la Edición estándar en servidores con más de 128 GB de memoria.
Específicamente con ColumnStore, además de poder usar 32 GB además del grupo de búfer, tenga en cuenta que la compresión que puede obtener aquí significa que a menudo puede incluir mucho más en ese límite de 32 GB de lo que podría con los mismos datos en el almacenamiento tradicional. tienda de filas. Y si no puede usar ColumnStore por cualquier motivo (o aún no cabe en 32 GB), ahora puede implementar la compresión tradicional de páginas o filas; esto podría no permitirle colocar toda su base de datos en el grupo de búfer de 128 GB, pero podría permitir que más de sus datos estén en la memoria en un momento dado.
Cosas similares son posibles en Express (a menor escala), donde puede tener 1,4 GB para el grupo de búfer, pero ~352 MB adicionales por instancia para ColumnStore y ~352 MB por base de datos para In-Memory OLTP.
Pero Enterprise Edition todavía tiene muchas ventajas
Hay muchos otros diferenciadores para mantener el interés en Enterprise Edition, además de los límites de memoria ilimitados, desde reconstrucciones en línea y escaneos de carrusel hasta grupos de disponibilidad completos y todos los derechos de virtualización que pueda tener. Incluso los índices de ColumnStore tienen mejoras de rendimiento bien definidas reservadas para Enterprise Edition.
Entonces, el hecho de que haya algunas técnicas que le permitirán sacar más provecho de la Edición estándar, no significa que escalará mágicamente para satisfacer sus necesidades de rendimiento. Al igual que mis otras publicaciones sobre "hacerlo con un presupuesto" (por ejemplo, partición y secundarios legibles), ciertamente puede dedicar tiempo y esfuerzo a crear una solución, pero solo lo llevará hasta cierto punto. El objetivo de esta publicación era simplemente demostrar que puede llegar más lejos con la Edición estándar en 2016 SP1 que nunca antes.