Si bien SQL Server en Linux se ha robado casi todos los titulares sobre v.Next, hay otros avances interesantes en la próxima versión de nuestra plataforma de base de datos favorita. En el frente de T-SQL, finalmente tenemos una forma integrada de realizar la concatenación de cadenas agrupadas:STRING_AGG() .
Digamos que tenemos la siguiente estructura de tabla simple:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
Para las pruebas de rendimiento, vamos a completar esto usando sys.all_objects y sys.all_columns . Pero primero para una demostración simple, agreguemos las siguientes filas:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); Si los foros son una indicación, es un requisito muy común devolver una fila para cada objeto, junto con una lista de nombres de columna separados por comas. (Extrapole eso a cualquier tipo de entidad que modele de esta manera:nombres de productos asociados con un pedido, nombres de partes involucradas en el ensamblaje de un producto, subordinados que reportan a un gerente, etc.) Entonces, por ejemplo, con los datos anteriores, quiero una salida como esta:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
La forma en que lograríamos esto en las versiones actuales de SQL Server probablemente sea usar FOR XML PATH , como demostré ser el más eficiente fuera de CLR en esta publicación anterior. En este ejemplo, se vería así:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Como era de esperar, obtenemos el mismo resultado demostrado anteriormente. En SQL Server v.Next, podremos expresar esto de manera más simple:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Nuevamente, esto produce exactamente el mismo resultado. Y pudimos hacer esto con una función nativa, evitando tanto el costoso FOR XML PATH andamios, y el STUFF() función utilizada para eliminar la primera coma (esto sucede automáticamente).
¿Qué pasa con el pedido?
Uno de los problemas con muchas de las soluciones kludge para la concatenación agrupada es que el orden de la lista separada por comas debe considerarse arbitrario y no determinista.
Para la XML PATH solución, demostré en otra publicación anterior que agregar un ORDER BY es trivial y garantizado. Entonces, en este ejemplo, podríamos ordenar la lista de columnas por nombre de columna alfabéticamente en lugar de dejar que SQL Server la ordene (o no):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Salida:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1 agrega WITHIN GROUP a STRING_AGG() , por lo que usando el nuevo enfoque, podemos decir:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Ahora obtenemos los mismos resultados. Tenga en cuenta que, al igual que un ORDER BY normal cláusula, puede agregar múltiples columnas de orden o expresiones dentro de WITHIN GROUP () .
Muy bien, ¡actuación ya!
Usando procesadores quad-core de 2,6 GHz, 8 GB de memoria y SQL Server CTP1.1 (14.0.100.187), creé una nueva base de datos, volví a crear estas tablas y agregué filas desde sys.all_objects y sys.all_columns . Me aseguré de incluir solo objetos que tuvieran al menos una columna:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); En mi sistema, esto arrojó 656 objetos y 8085 columnas (su sistema puede generar números ligeramente diferentes).
Los planes
Primero, comparemos los planes y las pestañas de E/S de la tabla para nuestras dos consultas desordenadas, utilizando Plan Explorer. Estas son las métricas generales de tiempo de ejecución:
 Métricas de tiempo de ejecución para XML PATH (arriba) y STRING_AGG() (abajo)
Métricas de tiempo de ejecución para XML PATH (arriba) y STRING_AGG() (abajo)
El plan gráfico y la E/S de la tabla de FOR XML PATH consulta:
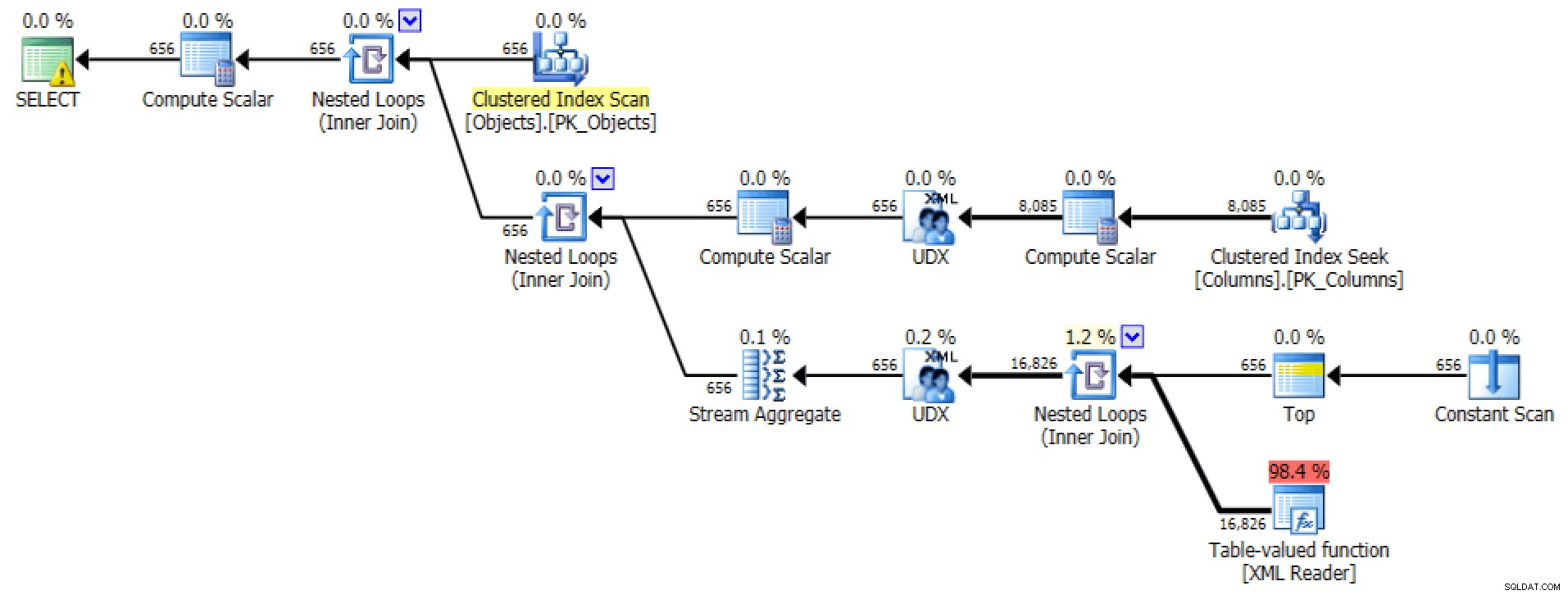
 E/S de plan y tabla para XML PATH, sin orden
E/S de plan y tabla para XML PATH, sin orden
Y del STRING_AGG versión:
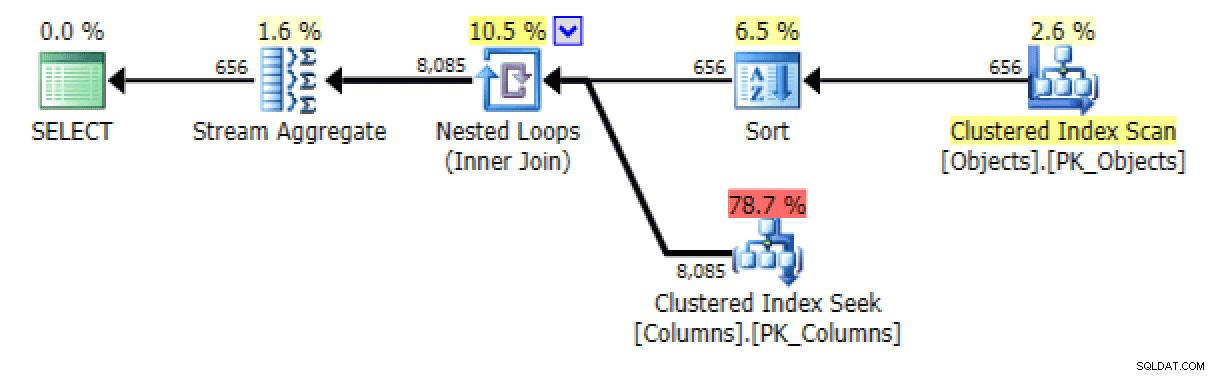
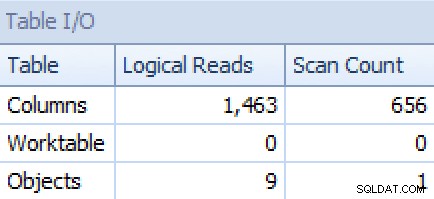 E/S de plan y tabla para STRING_AGG, sin pedidos
E/S de plan y tabla para STRING_AGG, sin pedidos
Para este último, la búsqueda de índice agrupado me parece un poco preocupante. Este parecía un buen caso para probar el FORCESCAN que rara vez se usa sugerencia (y no, esto ciertamente no ayudaría a FOR XML PATH consulta):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; Ahora el plan y la pestaña E/S de la tabla se ven mucho mucho mejor, al menos a primera vista:
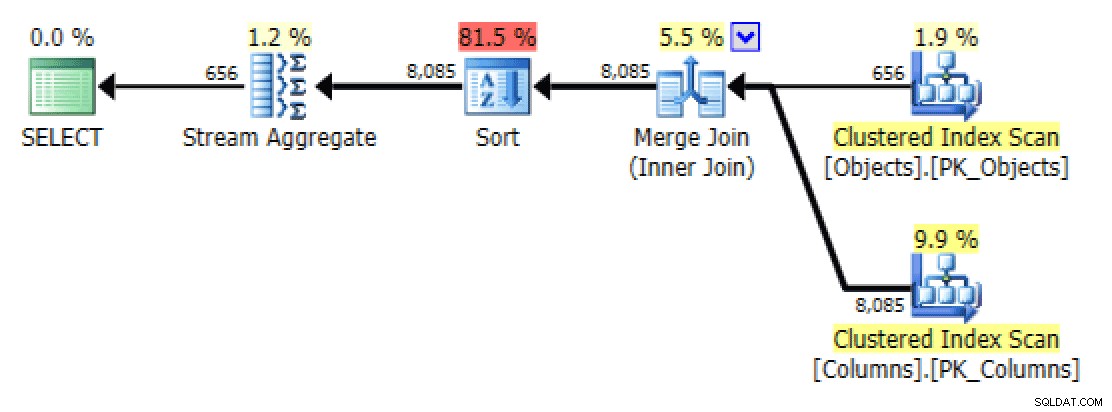
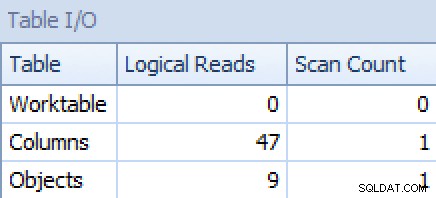 E/S de plan y tabla para STRING_AGG(), sin pedidos, con FORCESCAN
E/S de plan y tabla para STRING_AGG(), sin pedidos, con FORCESCAN
Las versiones ordenadas de las consultas generan aproximadamente los mismos planes. Para FOR XML PATH versión, se añade una ordenación:
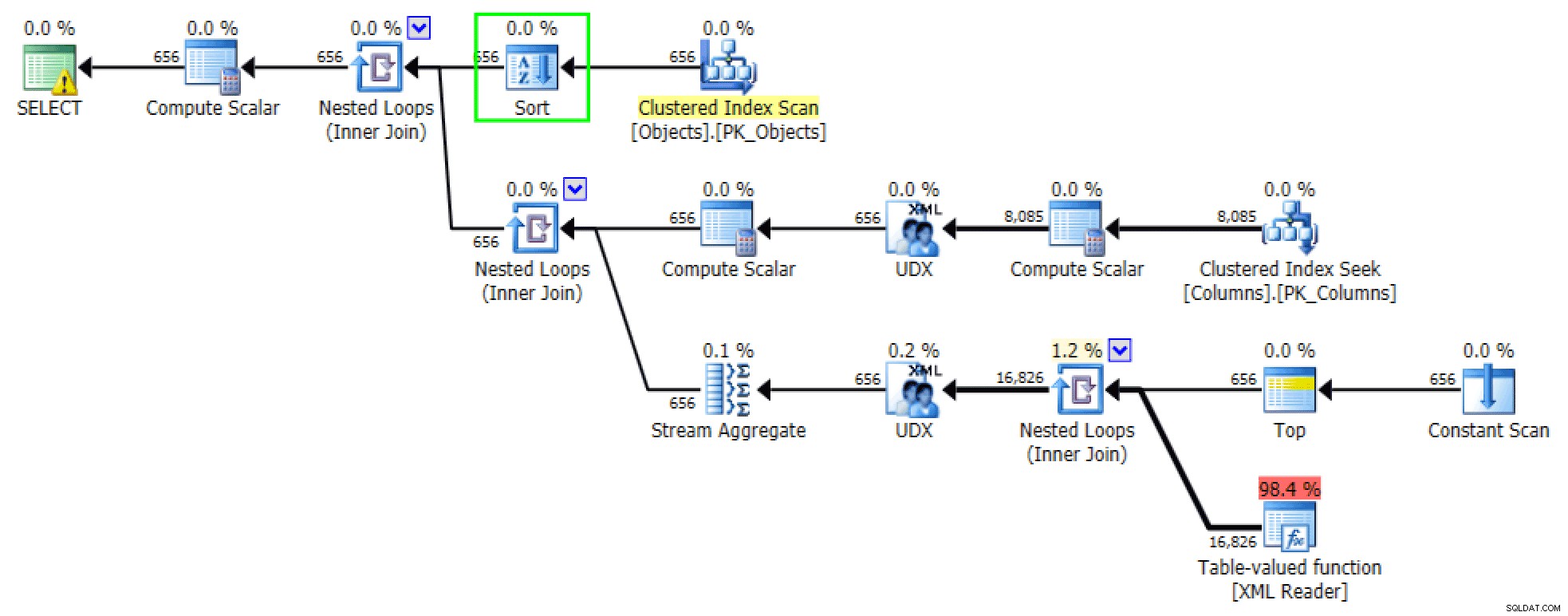 Ordenación agregada en la versión FOR XML PATH
Ordenación agregada en la versión FOR XML PATH
Para STRING_AGG() , se elige un escaneo en este caso, incluso sin el FORCESCAN sugerencia, y no se requiere ninguna operación de clasificación adicional, por lo que el plan se ve idéntico al FORCESCAN versión.
A escala
Observar un plan y métricas de tiempo de ejecución únicas podría darnos una idea de si STRING_AGG() funciona mejor que el FOR XML PATH existente solución, pero una prueba más grande podría tener más sentido. ¿Qué sucede cuando realizamos la concatenación agrupada 5000 veces?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
Después de ejecutar este script cinco veces, promedié los números de duración y estos son los resultados:
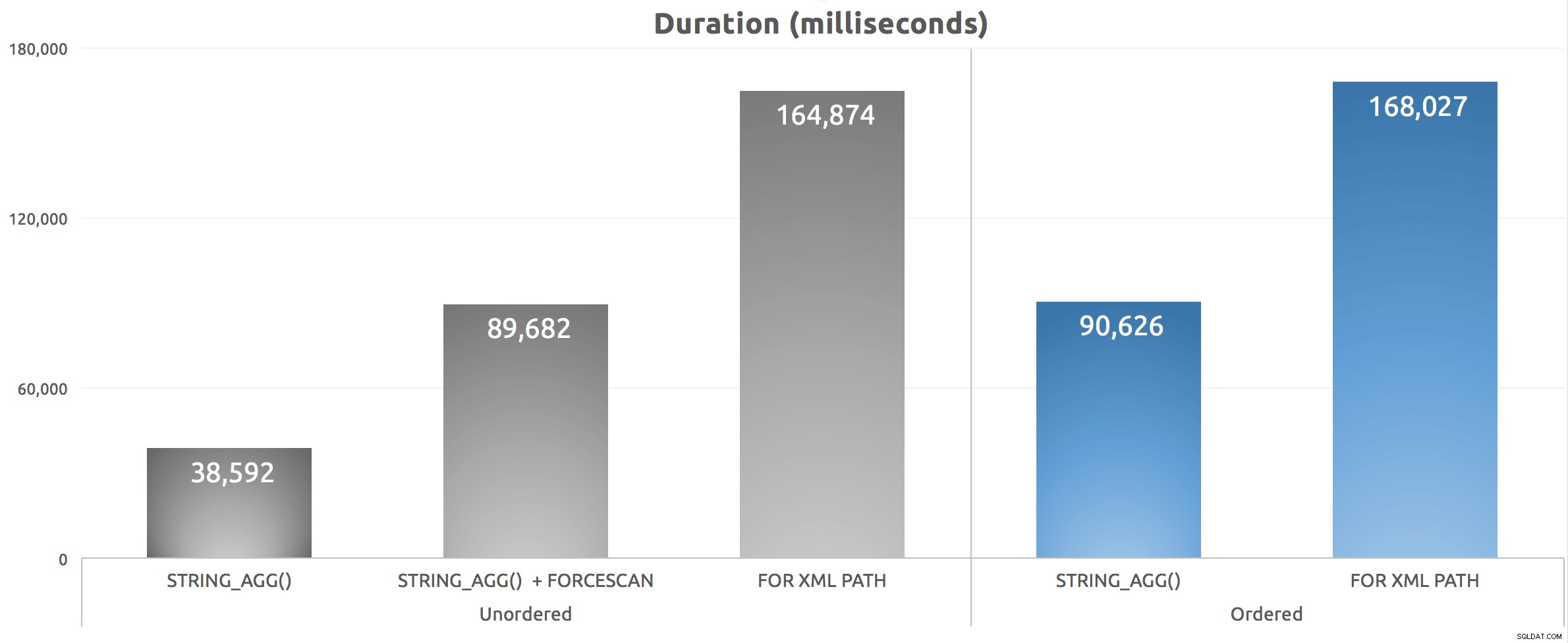 Duración (milisegundos) para varios enfoques de concatenación agrupada
Duración (milisegundos) para varios enfoques de concatenación agrupada
Podemos ver que nuestro FORCESCAN La sugerencia realmente empeoró las cosas:aunque cambiamos el costo de la búsqueda de índice agrupado, el tipo fue mucho peor, a pesar de que los costos estimados los consideraron relativamente equivalentes. Más importante aún, podemos ver que STRING_AGG() ofrece un beneficio de rendimiento, ya sea que las cadenas concatenadas deban o no ordenarse de una manera específica. Como con STRING_SPLIT() , que revisé en marzo, estoy bastante impresionado de que esta función se adapte bien antes de "v1".
Tengo más pruebas planeadas, quizás para una publicación futura:
- Cuando todos los datos provienen de una sola tabla, con y sin un índice que admita la ordenación
- Pruebas de rendimiento similares en Linux
Mientras tanto, si tiene casos de uso específicos para la concatenación agrupada, compártalos a continuación (o envíeme un correo electrónico a [email protected]). Siempre estoy dispuesto a asegurarme de que mis pruebas sean lo más reales posible.