¿No es genial tener disponible una nueva versión de SQL Server? Esto es algo que solo sucede cada dos años, y este mes vimos que uno alcanzó la disponibilidad general. (Ok, sé que obtenemos una nueva versión de SQL Database en Azure casi continuamente, pero considero que esto es diferente). Reconociendo este nuevo lanzamiento, el martes de T-SQL de este mes (presentado por Michael Swart – @mjswart) trata el tema de todo lo relacionado con SQL Server 2016.
¿No es genial tener disponible una nueva versión de SQL Server? Esto es algo que solo sucede cada dos años, y este mes vimos que uno alcanzó la disponibilidad general. (Ok, sé que obtenemos una nueva versión de SQL Database en Azure casi continuamente, pero considero que esto es diferente). Reconociendo este nuevo lanzamiento, el martes de T-SQL de este mes (presentado por Michael Swart – @mjswart) trata el tema de todo lo relacionado con SQL Server 2016.
Así que hoy quiero ver la función de tablas temporales de SQL 2016 y echar un vistazo a algunas situaciones de planes de consulta que podría terminar viendo. Me encantan las tablas temporales, pero me he encontrado con un problema del que tal vez quieras estar al tanto.
Ahora, a pesar de que SQL Server 2016 ahora está en RTM, estoy usando AdventureWorks2016CTP3, que puede descargar aquí, pero no descargue solo AdventureWorks2016CTP3.bak , también tome SQLServer2016CTP3Samples.zip del mismo sitio.
Verá, en el archivo de muestras, hay algunos scripts útiles para probar nuevas funciones, incluidas algunas para tablas temporales. Es beneficioso para todos:puedes probar un montón de funciones nuevas y no tengo que repetir tanto el guión en esta publicación. De todos modos, vaya y obtenga los dos scripts sobre tablas temporales, ejecutando AW 2016 CTP3 Temporal Setup.sql , seguido de Temporal System-Versioning Sample.sql .
Estos scripts configuran versiones temporales de algunas tablas, incluido HumanResources.Employee . Crea HumanResources.Employee_Temporal (aunque, técnicamente, podría haberse llamado cualquier cosa). Al final de CREATE TABLE declaración, aparece este bit, agregando dos columnas ocultas para indicar cuándo la fila es válida e indicando que se debe crear una tabla llamada HumanResources.Employee_Temporal_History para almacenar las versiones antiguas.
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
Lo que quiero explorar en esta publicación es lo que sucede con los planes de consulta cuando se usa el historial.
Si consulto la tabla para ver la última fila de un BusinessEntityID en particular , obtengo una búsqueda de índice agrupado, como se esperaba.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
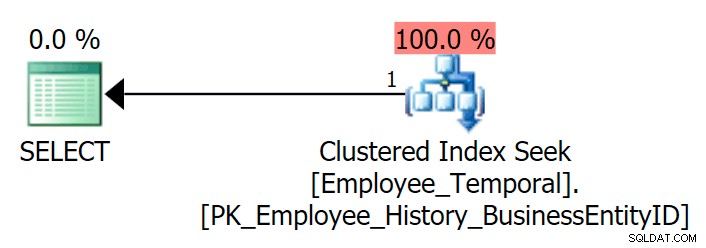
Estoy seguro de que podría consultar esta tabla usando otros índices, si tuviera alguno. Pero en este caso, no lo hace. Vamos a crear uno.
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
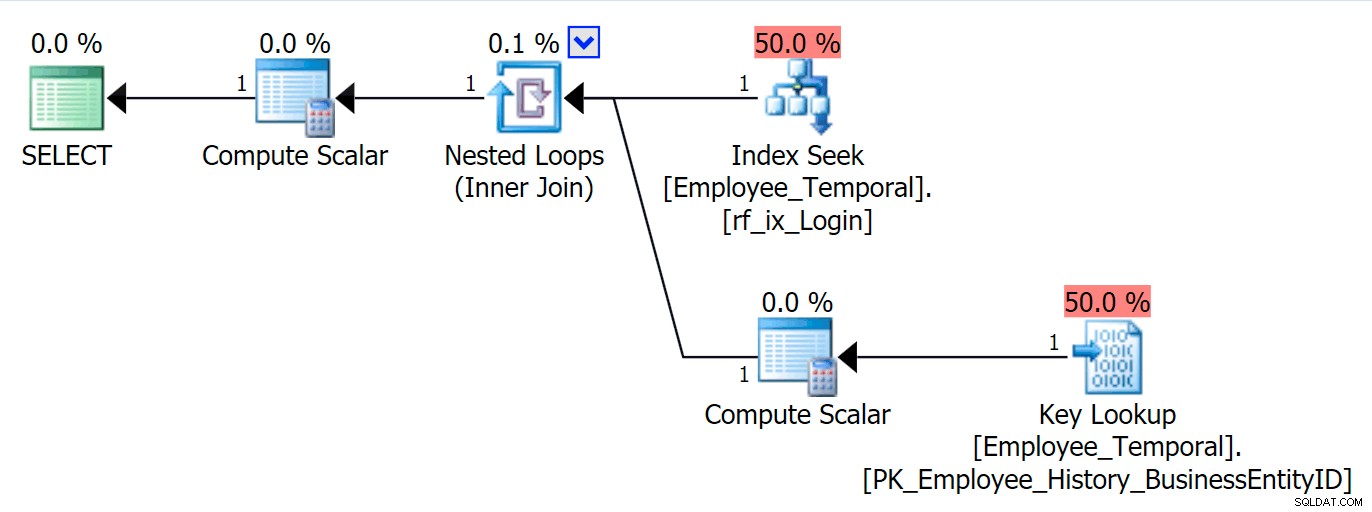
Ahora puedo consultar la tabla por LoginID , y verá una Búsqueda de clave si solicito columnas que no sean Loginid o BusinessEntityID . Nada de esto es sorprendente.
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
Usemos SQL Server Management Studio por un minuto y veamos cómo se ve esta tabla en el Explorador de objetos.

Podemos ver la tabla Historial mencionada en HumanResources.Employee_Temporal y las columnas e índices tanto de la propia tabla como de la tabla de historial. Pero mientras que los índices en la tabla adecuada son la clave principal (en BusinessEntityID ) y el índice que acababa de crear, la tabla Historial no tiene índices coincidentes.
El índice de la tabla de historial está en ValidTo y ValidFrom . Podemos hacer clic derecho en el índice y seleccionar Propiedades, y vemos este cuadro de diálogo:
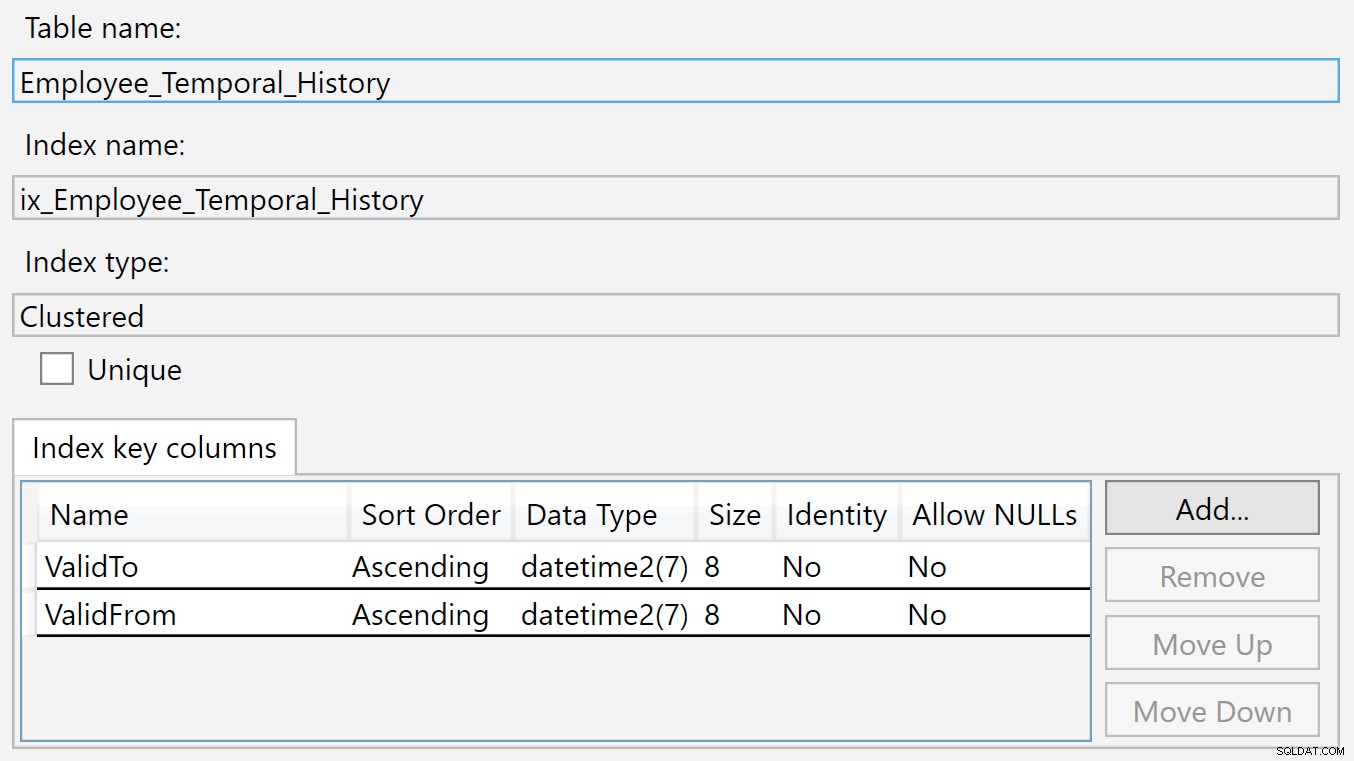
Se inserta una nueva fila en esta tabla de Historial cuando ya no es válida en la tabla principal, porque acaba de ser eliminada o modificada. Los valores en el ValidTo se rellenan de forma natural con la hora actual, por lo que ValidTo actúa como una clave ascendente, como una columna de identidad, de modo que aparecen nuevas inserciones al final de la estructura del árbol b.
Pero, ¿cómo funciona esto cuando quieres consultar la tabla?
Si queremos consultar en nuestra tabla lo que estaba actualizado en un momento determinado, debemos usar una estructura de consulta como:
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
Esta consulta necesita concatenar las filas apropiadas de la tabla principal con las filas apropiadas de la tabla de historial.
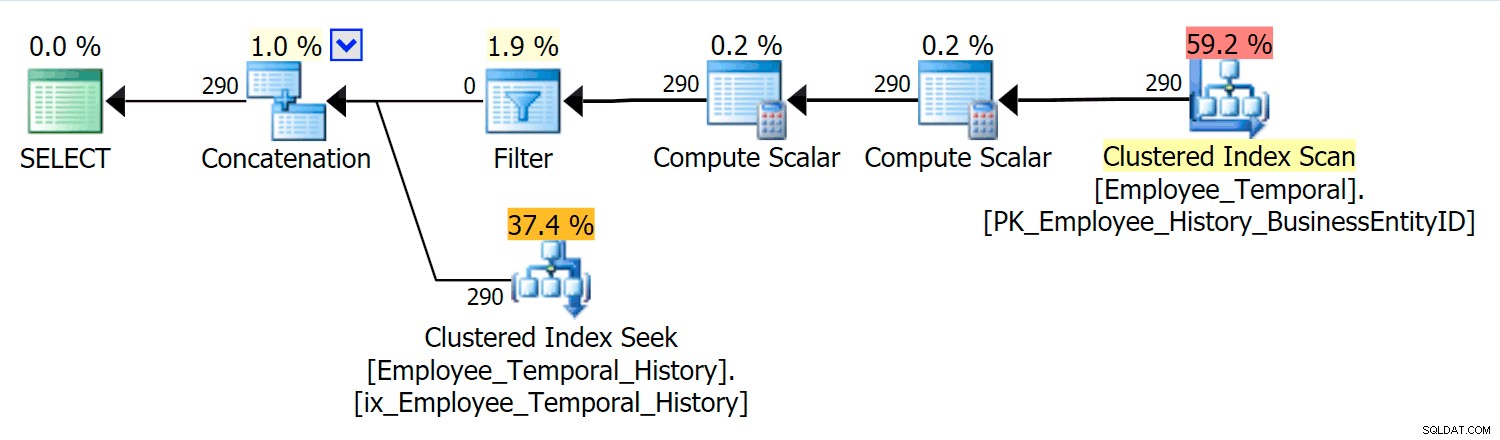
En este escenario, las filas que eran válidas en el momento que elegí eran todas de la tabla de historial, pero no obstante, vemos un análisis de índice agrupado en la tabla principal, que fue filtrado por un operador de filtro. El predicado de este filtro es:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Repasemos esto en un momento.
La búsqueda de índice agrupado en la tabla de historial claramente debe aprovechar un predicado de búsqueda en ValidTo. El inicio del escaneo de rango de Seek es HumanResources.Employee_Temporal_History.ValidTo > Operador escalar('2016-06-12 11:22:00') , pero no hay End, porque cada fila que tiene un ValidTo después del tiempo que nos interesa es una fila candidata y debe probarse para un ValidFrom apropiado valor por el predicado residual, que es HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Ahora, los intervalos son difíciles de indexar; eso es algo conocido que se ha discutido en muchos blogs. La mayoría de las soluciones efectivas consideran formas creativas de escribir consultas, pero no se han incorporado tales inteligencias en las tablas temporales. Sin embargo, también puede poner índices en otras columnas, como en ValidFrom, o incluso tener índices que coincidan con los tipos de consultas que pueda tener en la tabla principal. Con un índice agrupado que es una clave compuesta en ambos ValidTo y ValidFrom , estas dos columnas se incluyen en todas las demás columnas, lo que brinda una buena oportunidad para algunas pruebas de predicado residual.
Si sé qué ID de inicio de sesión me interesa, mi plan tiene una forma diferente.
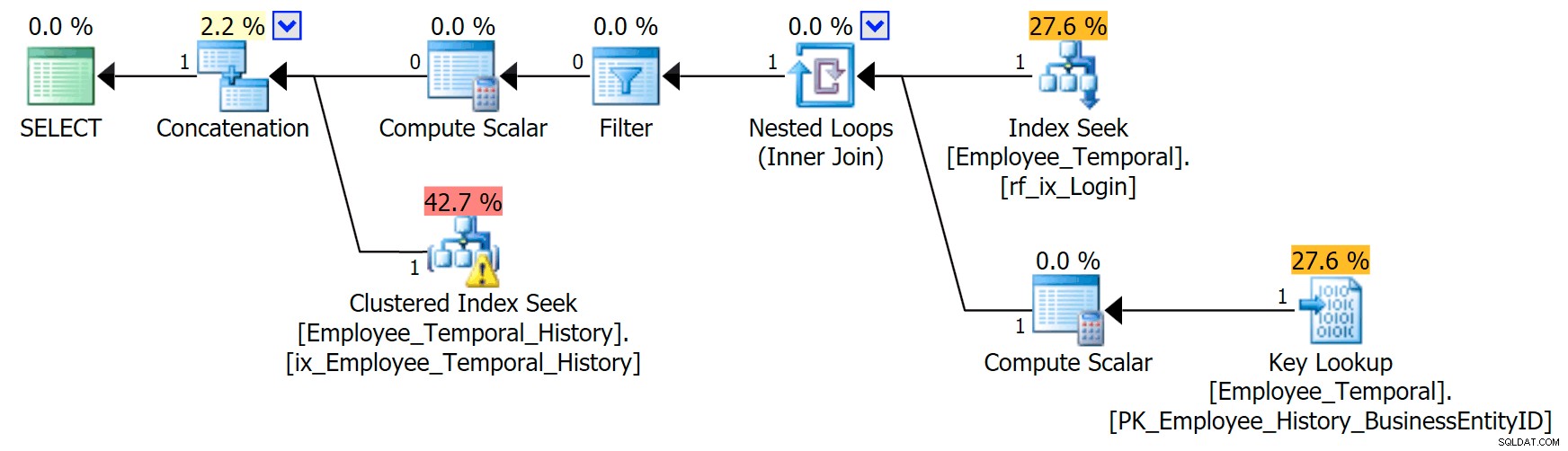
La rama superior del operador Concatenación tiene un aspecto similar al anterior, aunque ese operador Filtro ha entrado en la refriega para eliminar las filas que no son válidas, pero la Búsqueda de índice agrupado en la rama inferior tiene una Advertencia. Esta es una advertencia de predicado residual, como los ejemplos en una publicación anterior mía. Es capaz de filtrar entradas que son válidas hasta cierto punto después del tiempo que nos interesa, pero el predicado residual ahora filtra al LoginID así como ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Los cambios en las filas de rob0 serán una pequeña proporción de las filas en el Historial. Esta columna no será única como en la tabla principal, porque es posible que la fila se haya cambiado varias veces, pero sigue siendo un buen candidato para la indexación.
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
Este nuevo índice tiene un efecto notable en nuestro plan.
¡¡Ahora ha cambiado nuestra búsqueda de índice agrupado en un escaneo de índice agrupado!!
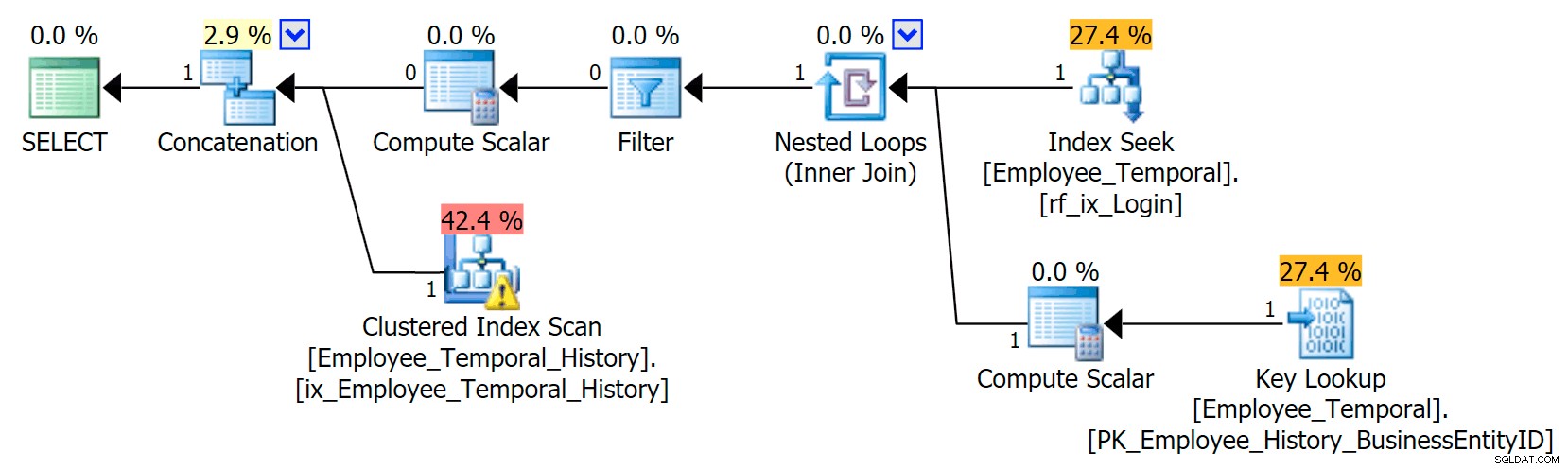
Verá, el Optimizador de consultas ahora determina que lo mejor que puede hacer es usar el nuevo índice. Pero también decide que el esfuerzo de tener que hacer búsquedas para obtener todas las demás columnas (porque estaba preguntando por todas las columnas) sería simplemente demasiado trabajo. Se alcanzó el punto de inflexión (lamentablemente, una suposición incorrecta en este caso), y en su lugar se eligió un SCAN de índice agrupado. Aunque sin el índice no agrupado, la mejor opción hubiera sido usar una búsqueda de índice agrupado, cuando el índice no agrupado se ha considerado y rechazado por razones de punto de inflexión, elige escanear.
Lamentablemente, acabo de crear este índice y sus estadísticas deberían ser buenas. Debería saber que una búsqueda que requiere exactamente una búsqueda debería ser mejor que un escaneo de índice agrupado (solo por estadísticas, si estaba pensando que debería saber esto porque LoginID es único en la tabla principal, recuerda que puede no haberlo sido siempre). Por lo tanto, sospecho que se deben evitar las búsquedas en las tablas de historial, aunque aún no he investigado lo suficiente sobre esto.
Ahora, si solo consultáramos las columnas que aparecen en nuestro índice no agrupado, obtendríamos un comportamiento mucho mejor. Ahora que no se requiere búsqueda, nuestro nuevo índice en la tabla de historial se usa felizmente. Todavía necesita aplicar un predicado residual basado en solo poder filtrar a LoginID y ValidTo , pero se comporta mucho mejor que pasar a un análisis de índice agrupado.
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
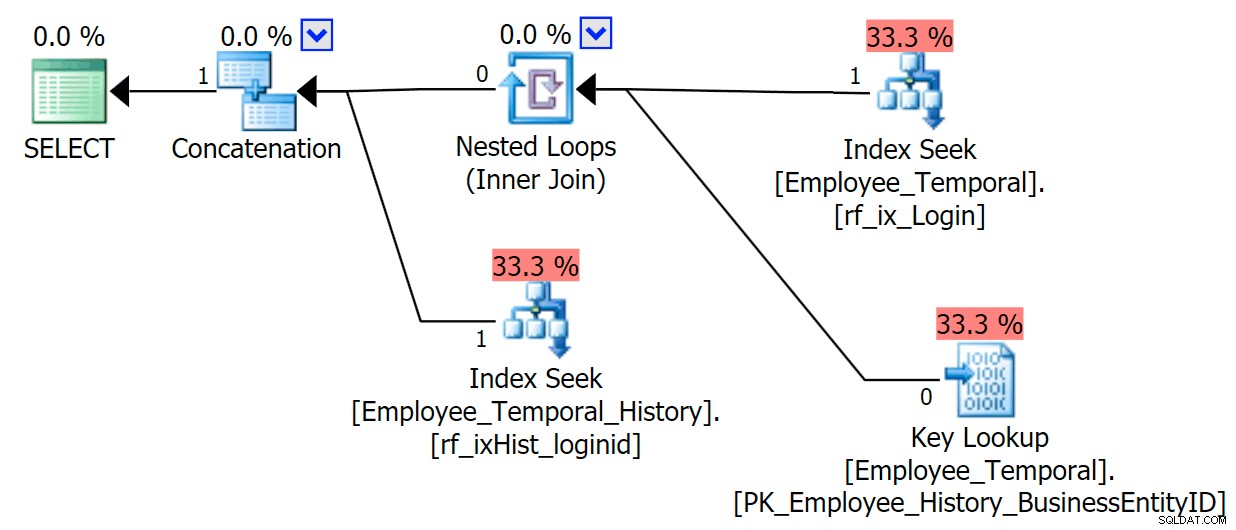
Por lo tanto, indexe sus tablas de historial de formas adicionales, teniendo en cuenta cómo las consultará. Incluya las columnas necesarias para evitar búsquedas, porque realmente está evitando escaneos.
Estas tablas de historial pueden aumentar de tamaño si los datos cambian con frecuencia. Así que tenga en cuenta cómo se están manejando. Esta misma situación ocurre cuando se usa el otro FOR SYSTEM_TIME construcciones, por lo que debe (como siempre) revisar los planes que producen sus consultas e indexar para asegurarse de que está bien posicionado para aprovechar lo que es una característica muy poderosa de SQL Server 2016.