A principios de esta semana, publiqué un seguimiento de mi publicación reciente sobre STRING_SPLIT() en SQL Server 2016, abordando varios comentarios dejados en la publicación y/o enviados directamente a mí:
STRING_SPLIT()en SQL Server 2016:Seguimiento #1
Después de que se escribió la mayor parte de esa publicación, hubo una pregunta de última hora de Doug Ellner:
¿Cómo se comparan estas funciones con los parámetros con valores de tabla?
Ahora, probar los TVP ya estaba en mi lista de proyectos futuros, después de un reciente intercambio de twitter con @Nick_Craver en Stack Overflow. Dijo que estaban emocionados de que STRING_SPLIT() se desempeñó bien, porque no estaban satisfechos con el rendimiento de enviar ~7000 valores a través de un parámetro con valores de tabla.
Mis exámenes
Para estas pruebas, utilicé SQL Server 2016 RC3 (13.0.1400.361) en una VM Windows 10 de 8 núcleos, con almacenamiento PCIe y 32 GB de RAM.
Creé una tabla simple que imitaba lo que estaban haciendo (seleccionando alrededor de 10 000 valores de una tabla de publicaciones de más de 3 millones de filas), pero para mis pruebas, tiene muchas menos columnas y menos índices:
CREATE TABLE dbo.Posts_Regular ( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0 ); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
También creé una versión In-Memory, porque tenía curiosidad por saber si algún enfoque funcionaría de manera diferente allí:
CREATE TABLE dbo.Posts_InMemory ( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 4000000), HitCount int NOT NULL DEFAULT 0 ) WITH (MEMORY_OPTIMIZED = ON);
Ahora, quería crear una aplicación de C# que pasara 10 000 valores únicos, ya sea como una cadena separada por comas (creada con un StringBuilder) o como un TVP (pasado desde un DataTable). El objetivo sería recuperar o actualizar una selección de filas en función de una coincidencia, ya sea con un elemento producido al dividir la lista o un valor explícito en un TVP. Entonces, el código se escribió para agregar cada 300 valores a la cadena o DataTable (el código C# se encuentra en un apéndice a continuación). Tomé las funciones que creé en la publicación original, las modifiqué para manejar varchar(max) y luego agregó dos funciones que aceptaban un TVP, una de ellas optimizada para memoria. Estos son los tipos de tablas (las funciones se encuentran en el apéndice a continuación):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY); GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE ( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000) ) WITH (MEMORY_OPTIMIZED = ON); GO
También tuve que agrandar la tabla de Números para manejar cadenas> 8K y con> 8K elementos (lo hice filas de 1MM). Luego creé siete procedimientos almacenados:cinco de ellos tomando un varchar(max) y unirse con la función de salida para actualizar la tabla base, y luego dos para aceptar el TVP y unirse directamente contra eso. El código C# llama a cada uno de estos siete procedimientos, con la lista de 10 000 publicaciones para seleccionar o actualizar, 1000 veces. Estos procedimientos también se encuentran en el apéndice a continuación. Entonces, solo para resumir, los métodos que se están probando son:
- Nativo (
STRING_SPLIT()) - XML
- CLR
- Tabla de números
- JSON (con
intexplícito salida) - Parámetro con valores de tabla
- Parámetro con valores de tabla optimizados para memoria
Probaremos la recuperación de los 10 000 valores, 1000 veces, usando un DataReader, pero no iterando sobre el DataReader, ya que eso solo haría que la prueba tomara más tiempo y sería la misma cantidad de trabajo para la aplicación C#, independientemente de cómo esté la base de datos. produjo el conjunto. También probaremos la actualización de las 10 000 filas, 1000 veces cada una, usando ExecuteNonQuery() . Y probaremos con las versiones normal y optimizada para memoria de la tabla Publicaciones, que podemos cambiar muy fácilmente sin tener que cambiar ninguna de las funciones o procedimientos, usando un sinónimo:
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- to test memory-optimized version: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- to test the disk-based version again: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Inicié la aplicación, la ejecuté varias veces para cada combinación para garantizar que la compilación, el almacenamiento en caché y otros factores no fueran injustos con el lote ejecutado primero, y luego analicé los resultados de la tabla de registro (también verifiqué sys. dm_exec_procedure_stats para asegurarse de que ninguno de los enfoques tuviera una sobrecarga significativa basada en la aplicación y no la tuvieran).
Resultados:tablas basadas en disco
A veces tengo problemas con la visualización de datos:realmente traté de encontrar una manera de representar estas métricas en un solo gráfico, pero creo que había demasiados puntos de datos para que los más destacados se destaquen.
Puede hacer clic para agrandar cualquiera de estos en una nueva pestaña/ventana, pero incluso si tiene una ventana pequeña, traté de aclarar el ganador mediante el uso del color (y el ganador fue el mismo en todos los casos). Y para ser claros, por "Duración promedio" me refiero a la cantidad de tiempo promedio que le tomó a la aplicación completar un ciclo de 1,000 operaciones.
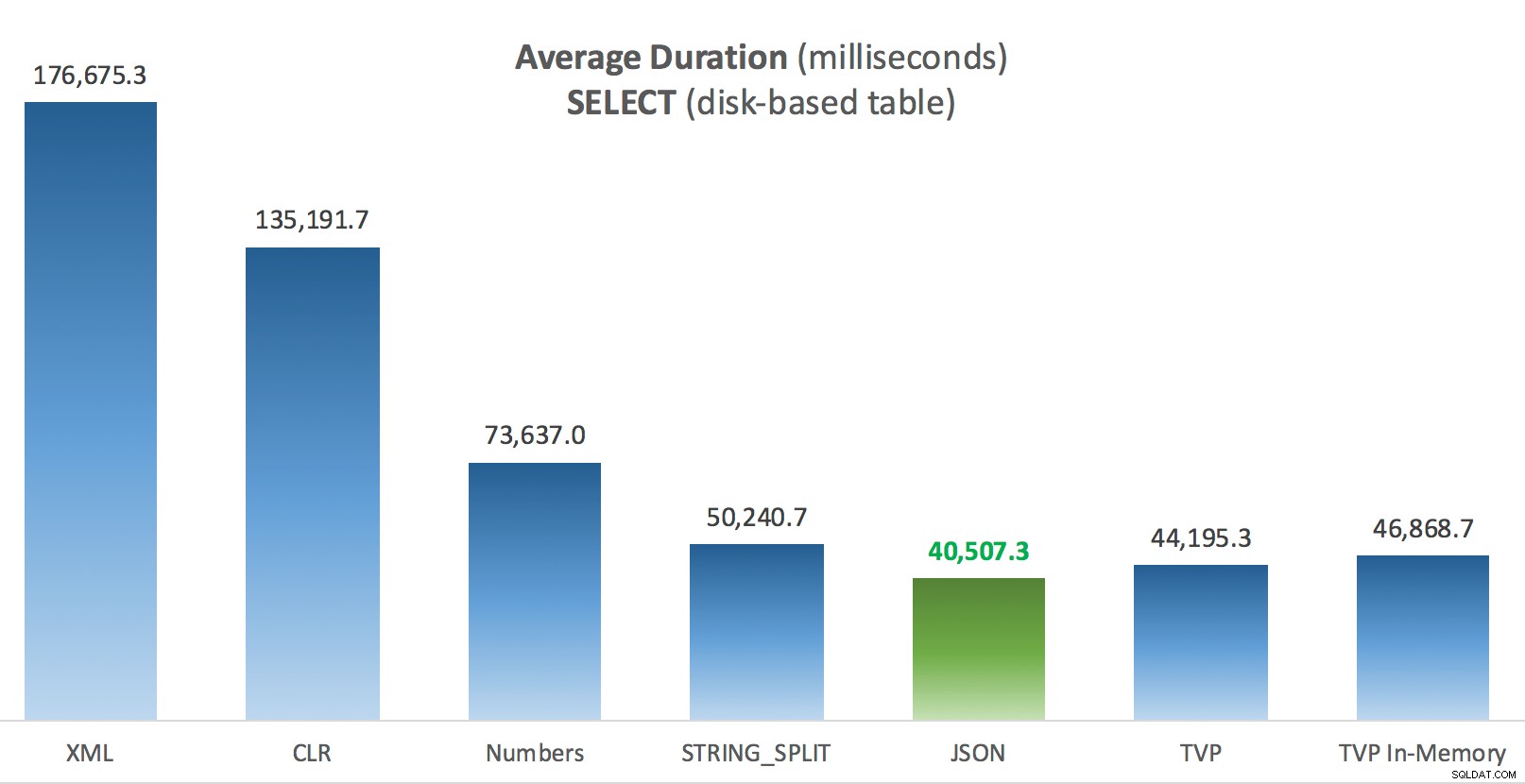 Duración promedio (milisegundos) para SELECT en la tabla de publicaciones basadas en disco
Duración promedio (milisegundos) para SELECT en la tabla de publicaciones basadas en disco
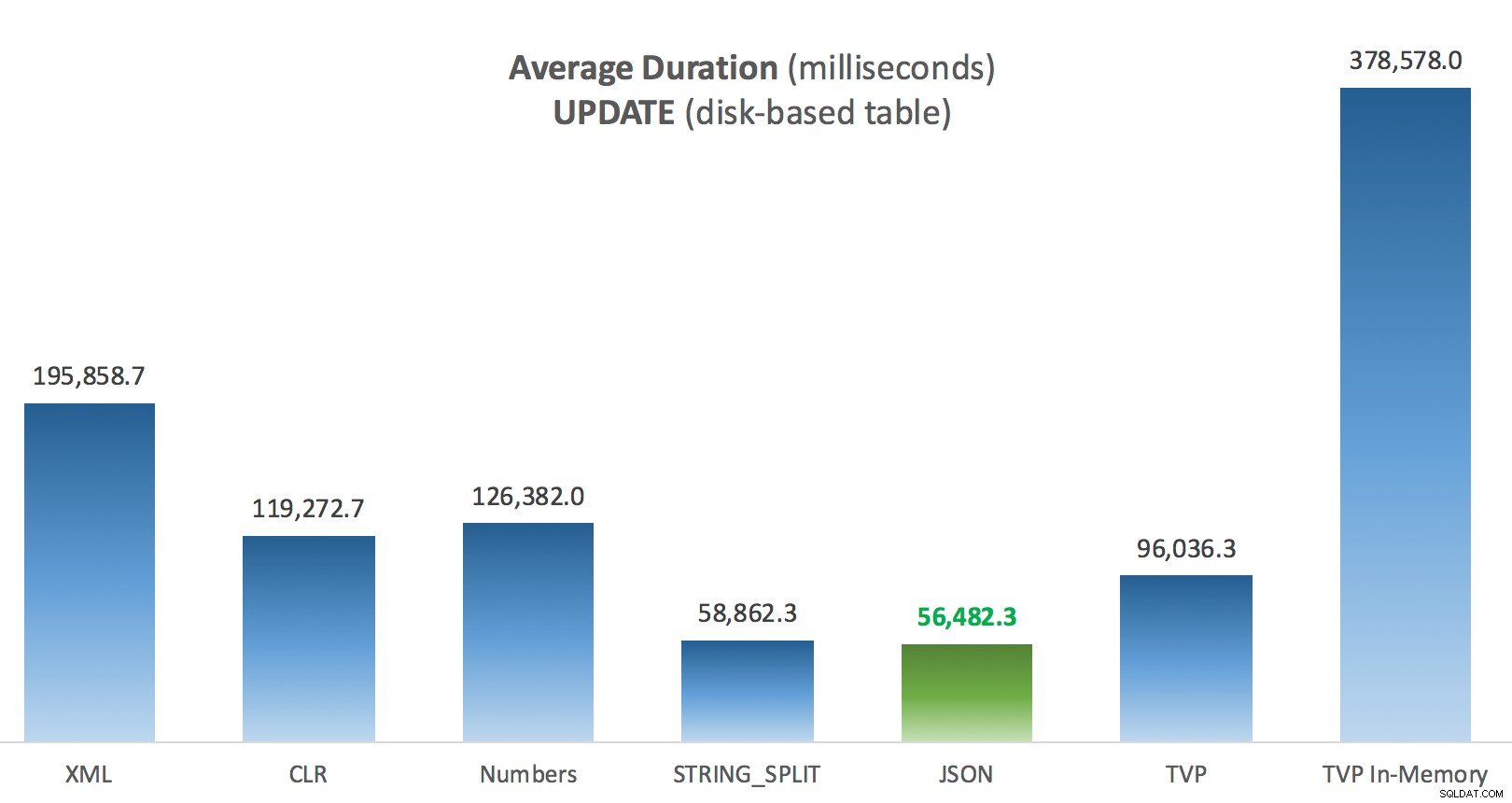 Duración promedio (milisegundos) para las ACTUALIZACIONES en la tabla de publicaciones basadas en disco
Duración promedio (milisegundos) para las ACTUALIZACIONES en la tabla de publicaciones basadas en disco
Lo más interesante aquí, para mí, es lo mal que lo hizo el TVP optimizado para memoria al ayudar con una UPDATE . Resulta que los escaneos paralelos actualmente se bloquean de manera demasiado agresiva cuando se trata de DML; Microsoft ha reconocido esto como una brecha de características y esperan solucionarlo pronto. Tenga en cuenta que actualmente es posible escanear en paralelo con SELECT pero está bloqueado para DML en este momento. (No se resolverá en SQL Server 2014, ya que estas operaciones de exploración paralelas específicas no están disponibles allí para ninguna operación). que los TVP optimizados para memoria funcionarán mejor (el patrón simplemente no funciona bien para este caso de uso particular de TVP relativamente grandes).
Para este caso específico, aquí están los planes para el SELECT (que podría obligar a ir en paralelo) y UPDATE (que no pude):
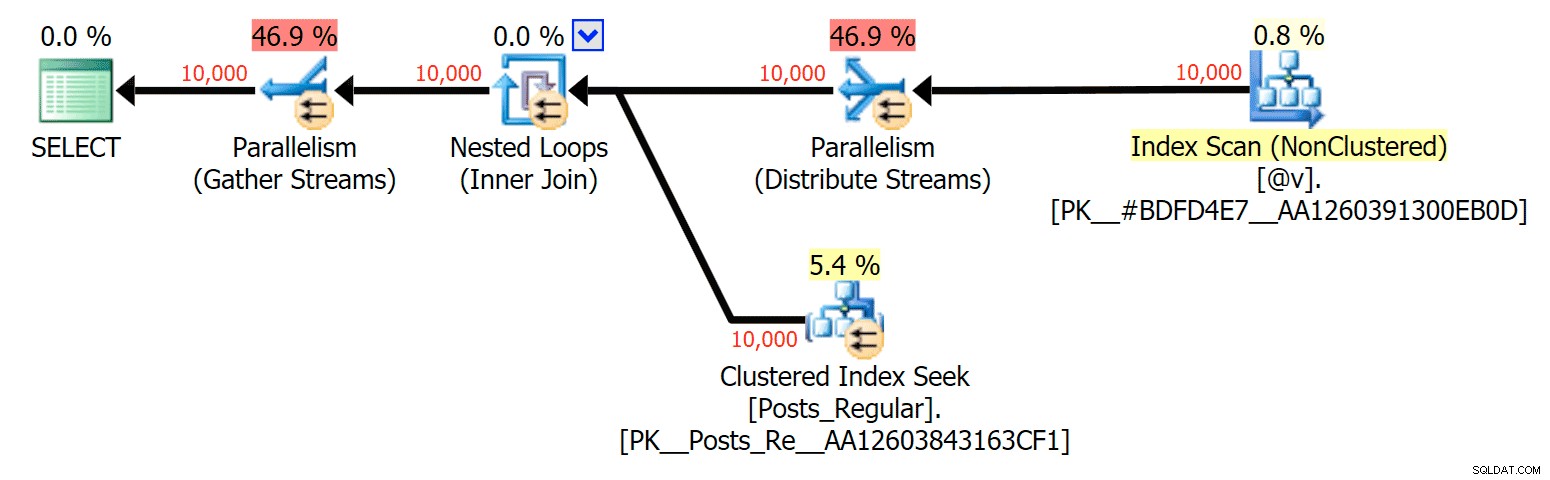 Paralelismo en un plan SELECT que une una tabla basada en disco a un TVP en memoria
Paralelismo en un plan SELECT que une una tabla basada en disco a un TVP en memoria
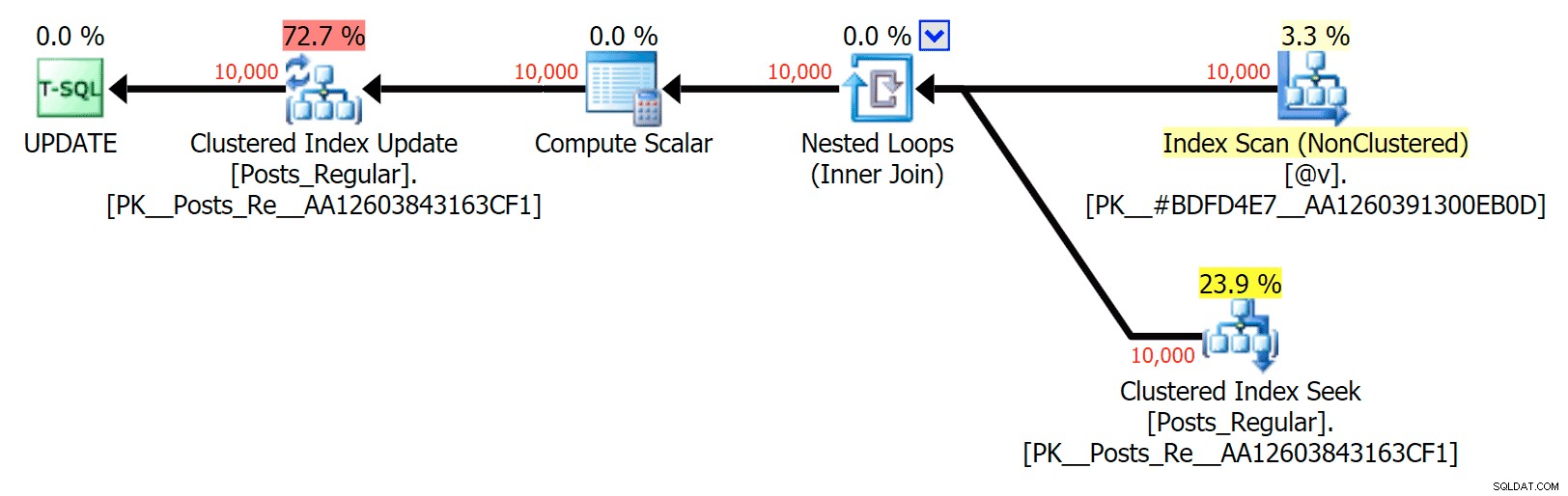 No hay paralelismo en un plan UPDATE que une una tabla basada en disco a una en memoria TVP
No hay paralelismo en un plan UPDATE que une una tabla basada en disco a una en memoria TVP
Resultados:tablas optimizadas para memoria
Un poco más de consistencia aquí:los cuatro métodos de la derecha son relativamente uniformes, mientras que los tres de la izquierda parecen muy indeseables por el contrario. También preste especial atención a la escala absoluta en comparación con las tablas basadas en disco:en su mayor parte, utilizando los mismos métodos e incluso sin paralelismo, termina con operaciones mucho más rápidas en tablas optimizadas para memoria, lo que lleva a un menor uso general de la CPU.
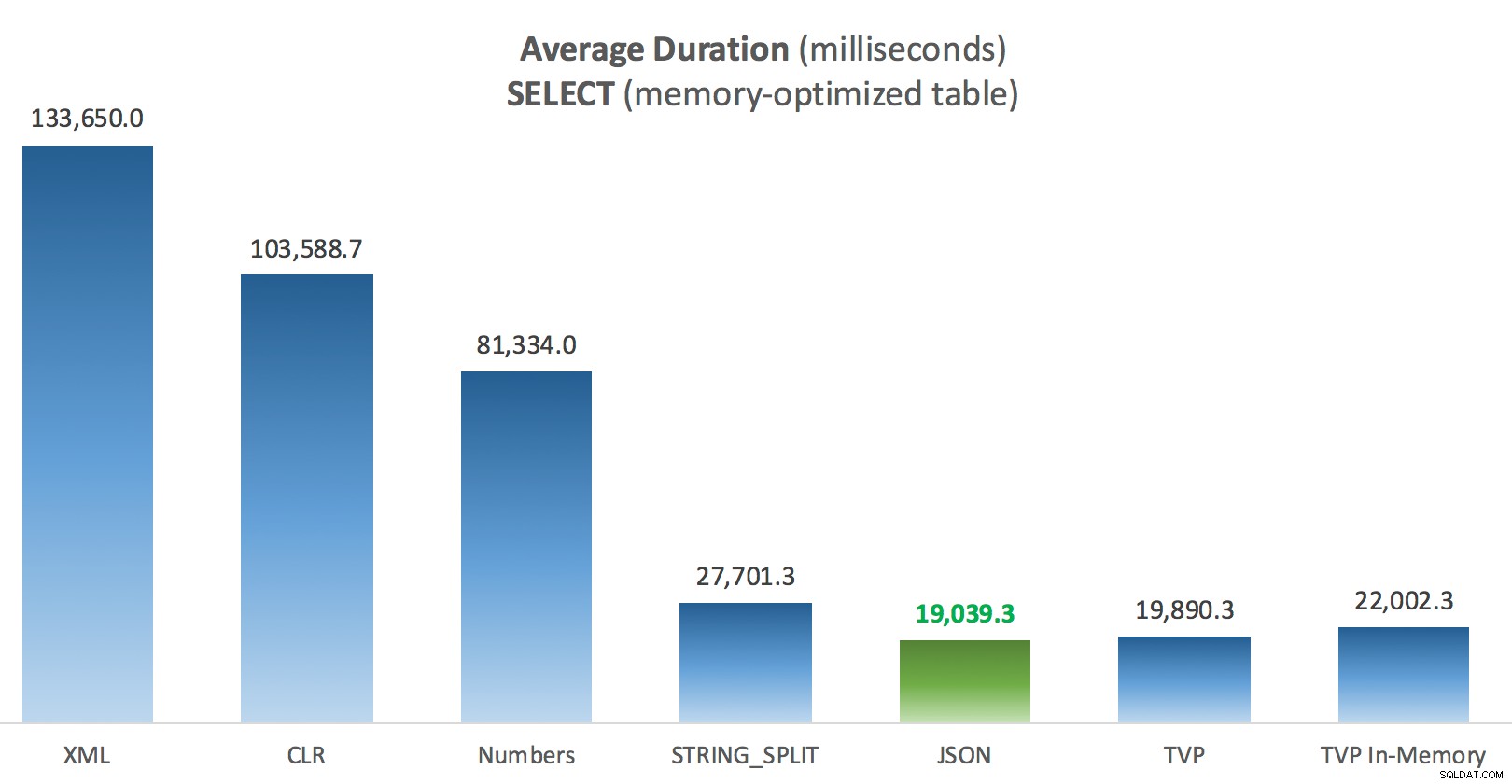 Duración promedio (milisegundos) para SELECT en comparación con la tabla de publicaciones optimizadas para memoria
Duración promedio (milisegundos) para SELECT en comparación con la tabla de publicaciones optimizadas para memoria
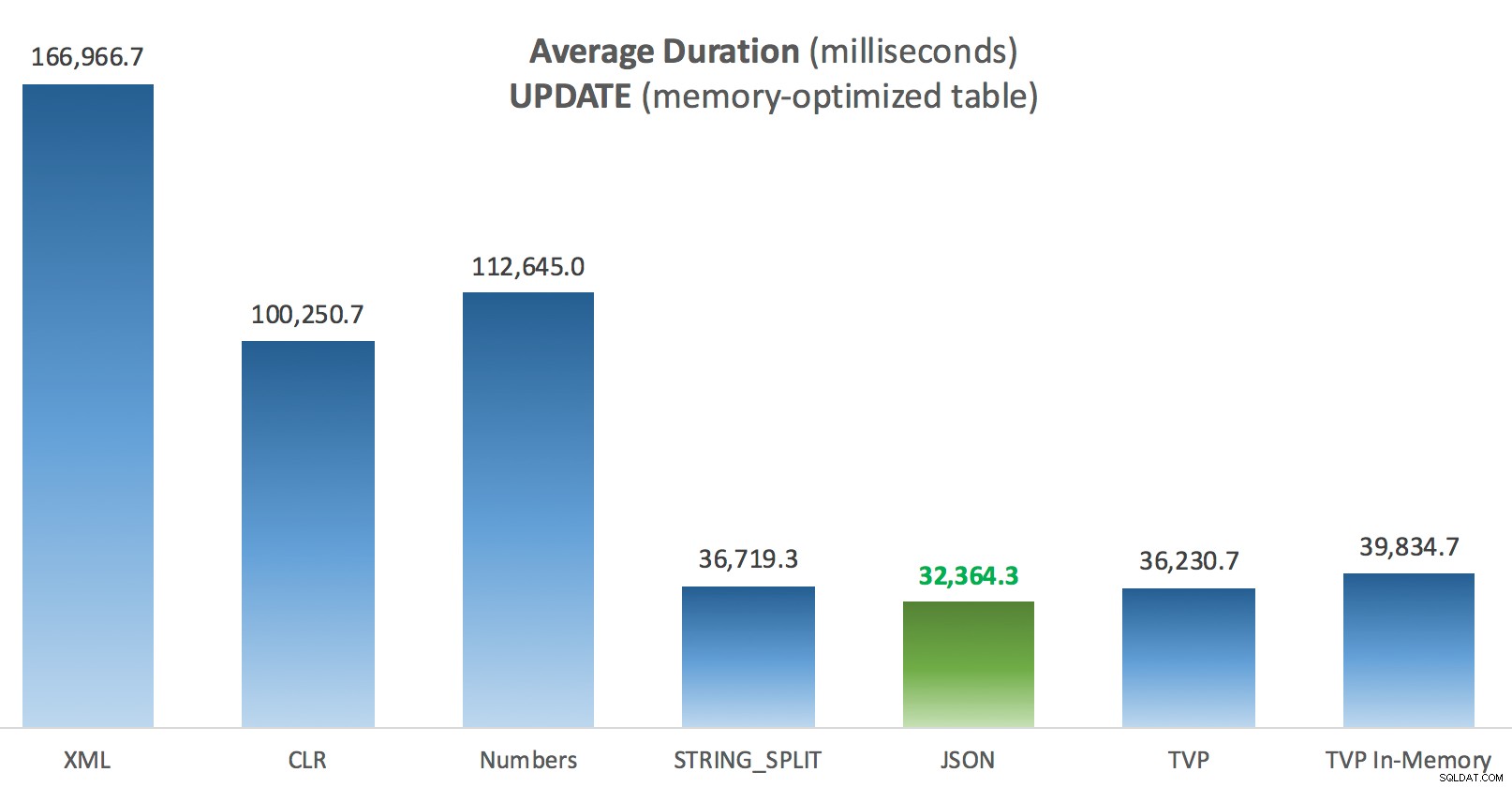 Duración promedio (milisegundos) para las ACTUALIZACIONES en comparación con la tabla de publicaciones optimizadas para memoria
Duración promedio (milisegundos) para las ACTUALIZACIONES en comparación con la tabla de publicaciones optimizadas para memoria
Conclusión
Para esta prueba específica, con un tamaño de datos, una distribución y una cantidad de parámetros específicos, y en mi hardware particular, JSON fue un ganador constante (aunque marginalmente). Sin embargo, para algunas de las otras pruebas en publicaciones anteriores, a otros enfoques les fue mejor. Solo un ejemplo de cómo lo que está haciendo y dónde lo está haciendo puede tener un impacto dramático en la eficiencia relativa de varias técnicas, aquí están las cosas que he probado en esta breve serie, con mi resumen de qué técnica usar. usar en ese caso, y cuál usar como segunda o tercera opción (por ejemplo, si no puede implementar CLR debido a una política corporativa o porque está usando Azure SQL Database, o no puede usar JSON o STRING_SPLIT() porque aún no está en SQL Server 2016). Tenga en cuenta que no volví y volví a probar la asignación de variables y SELECT INTO scripts que usan TVP:estas pruebas se configuraron asumiendo que ya tenía datos existentes en formato CSV que tendrían que dividirse primero de todos modos. Por lo general, si puede evitarlo, en primer lugar, no suavice sus conjuntos en cadenas separadas por comas, en mi humilde opinión.
| Objetivo | 1ra elección | Segunda elección (y tercera, según corresponda) |
|---|---|---|
| Asignación de variable simple | STRING_SPLIT() | CLR si <2016 XML si no hay CLR y <2016 |
| SELECCIONAR EN | CLR | XML si no hay CLR |
| SELECCIONAR EN (sin carrete) | CLR | Tabla de números si no hay CLR |
| SELECCIONAR EN (sin carrete + MAXDOP 1) | STRING_SPLIT() | CLR si <2016 Tabla de números si no hay CLR y <2016 |
| SELECCIONAR unirse a una lista grande (basada en disco) | JSON (int) | TVP si <2016 |
| SELECCIONAR unirse a una lista grande (optimizado para memoria) | JSON (int) | TVP si <2016 |
| ACTUALIZAR unirse a una lista grande (basada en disco) | JSON (int) | TVP si <2016 |
| ACTUALIZAR unirse a una lista grande (optimizado para memoria) | JSON (int) | TVP si <2016 |
Para la pregunta específica de Doug:JSON, STRING_SPLIT() , y los TVP se desempeñaron de manera bastante similar en estas pruebas en promedio, lo suficientemente cerca como para que los TVP sean la opción obvia si no está en SQL Server 2016. Si tiene diferentes casos de uso, estos resultados pueden diferir. Muy .
Lo que nos lleva a la moraleja de esto historia:yo y otros podemos realizar pruebas de rendimiento muy específicas, que giran en torno a cualquier característica o enfoque, y llegar a alguna conclusión sobre qué enfoque es el más rápido. Pero hay tantas variables que nunca tendré la confianza de decir "este enfoque es siempre el más rápido". En este escenario, me esforcé mucho por controlar la mayoría de los factores contribuyentes, y aunque JSON ganó en los cuatro casos, puede ver cómo esos diferentes factores afectaron los tiempos de ejecución (y drásticamente para algunos enfoques). Así que siempre vale la pena construir sus propias pruebas, y espero haber ayudado a ilustrar cómo hago ese tipo de cosas.
Apéndice A:Código de aplicación de consola
Por favor, no se preocupe por este código; literalmente se armó como una manera muy simple de ejecutar estos procedimientos almacenados 1000 veces con listas verdaderas y DataTables ensamblados en C#, y para registrar el tiempo que cada ciclo tardó en una tabla (para asegurarse de incluir cualquier sobrecarga relacionada con la aplicación con el manejo ya sea una cadena grande o una colección). Podría agregar el manejo de errores, hacer un ciclo diferente (por ejemplo, construir las listas dentro del ciclo en lugar de reutilizar una sola unidad de trabajo), y así sucesivamente.
using System;
using System.Text;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
namespace SplitTesting
{
class Program
{
static void Main(string[] args)
{
string operation = "Update";
if (args[0].ToString() == "-Select") { operation = "Select"; }
var csv = new StringBuilder();
DataTable elements = new DataTable();
elements.Columns.Add("value", typeof(int));
for (int i = 1; i <= 10000; i++)
{
csv.Append((i*300).ToString());
if (i < 10000) { csv.Append(","); }
elements.Rows.Add(i*300);
}
string[] methods = { "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" };
using (SqlConnection con = new SqlConnection())
{
con.ConnectionString = ConfigurationManager.ConnectionStrings["primary"].ToString();
con.Open();
SqlParameter p;
foreach (string method in methods)
{
SqlCommand cmd = new SqlCommand("dbo." + operation + "Posts_" + method, con);
cmd.CommandType = CommandType.StoredProcedure;
if (method == "TVP" || method == "TVP_InMemory")
{
cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value = elements;
}
else
{
cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value = csv.ToString();
}
var timer = System.Diagnostics.Stopwatch.StartNew();
for (int x = 1; x <= 1000; x++)
{
if (operation == "Update") { cmd.ExecuteNonQuery(); }
else { SqlDataReader rdr = cmd.ExecuteReader(); rdr.Close(); }
}
timer.Stop();
long this_time = timer.ElapsedMilliseconds;
// log time - the logging procedure adds clock time and
// records memory/disk-based (determined via synonym)
SqlCommand log = new SqlCommand("dbo.LogBatchTime", con);
log.CommandType = CommandType.StoredProcedure;
log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value = operation;
log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value = method;
log.Parameters.Add("@Timing", SqlDbType.Int).Value = this_time;
log.ExecuteNonQuery();
Console.WriteLine(method + " : " + this_time.ToString());
}
}
}
}
} Ejemplo de uso:
SplitTesting.exe -SeleccioneSplitTesting.exe -Actualizar
Apéndice B:funciones, procedimientos y tabla de registro
Aquí estaban las funciones editadas para admitir varchar(max) (la función CLR ya aceptó nvarchar(max) y aún me resistía a intentar cambiarlo):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));
GO
CREATE FUNCTION dbo.SplitStrings_XML( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)')
FROM (SELECT x = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));
GO
CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));
GO Y los procedimientos almacenados se veían así:
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max) AS BEGIN UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO CREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max) AS BEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO -- repeat for the 4 other varchar(max)-based methods CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO CREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO -- repeat for in-memory
Y finalmente, la tabla de registro y el procedimiento:
CREATE TABLE dbo.SplitLog
(
LogID int IDENTITY(1,1) PRIMARY KEY,
ClockTime datetime NOT NULL DEFAULT GETDATE(),
OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular
Operation varchar(32) NOT NULL DEFAULT 'Update', -- or select
Method varchar(32) NOT NULL DEFAULT 'Native', -- or TVP, JSON, etc.
Timing int NOT NULL DEFAULT 0
);
GO
CREATE PROCEDURE dbo.LogBatchTime
@Operation varchar(32),
@Method varchar(32),
@Timing int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing)
SELECT base_object_name, @Operation, @Method, @Timing
FROM sys.synonyms WHERE name = N'Posts';
END
GO
-- and the query to generate the graphs:
;WITH x AS
(
SELECT OperatingTable,Operation,Method,Timing,
Recency = ROW_NUMBER() OVER
(PARTITION BY OperatingTable,Operation,Method
ORDER BY ClockTime DESC)
FROM dbo.SplitLog
)
SELECT OperatingTable,Operation,Method,AverageDuration = AVG(1.0*Timing)
FROM x WHERE Recency <= 3
GROUP BY OperatingTable,Operation,Method;