Al equipo de SQLskills le encantan las estadísticas de espera. Si revisa las publicaciones de este blog (vea las publicaciones de Paul sobre estadísticas de espera instintivas) y en el sitio de SQLskills, verá publicaciones de todos nosotros discutiendo el valor de las estadísticas de espera, lo que buscamos y por qué una determinada esperar es un problema. Paul es el que más escribe sobre esto, pero todos nosotros normalmente comenzamos con las estadísticas de espera cuando solucionamos un problema de rendimiento. ¿Qué significa eso en términos de ser proactivo?
Para obtener una imagen completa de lo que significan las estadísticas de espera durante un problema de rendimiento, debe saber cuáles son sus esperas normales. Eso significa capturar proactivamente esta información y usar esa línea base como referencia. Si no tiene estos datos, cuando ocurra un problema de rendimiento, no sabrá si las esperas de PAGELATCH son típicas en su entorno (bastante posible) o si de repente tiene un problema relacionado con tempdb debido a algún código nuevo que se agregó. .
Los datos de las estadísticas de espera
Anteriormente publiqué un script que uso para capturar estadísticas de espera, y es un script que he estado usando durante mucho tiempo para los clientes. Sin embargo, recientemente hice cambios en mi script y modifiqué ligeramente mi método. Déjame explicarte por qué…
La premisa fundamental detrás de las estadísticas de espera es que SQL Server realiza un seguimiento cada vez que un subproceso tiene que esperar "algo". ¿Esperando para leer una página del disco? PAGEIOLATCH_XX esperar. ¿Está esperando a que le concedan un bloqueo para modificar los datos? LCX_M_XXX espera. ¿Esperando una concesión de memoria para que se pueda ejecutar una consulta? RESOURCE_SEMAPHORE espera. Todas estas esperas se rastrean en el DMV sys.dm_os_wait_stats, y los datos simplemente se acumulan con el tiempo... es un representante acumulativo de las esperas.
Por ejemplo, tengo una instancia de SQL Server 2014 en una de mis máquinas virtuales que ha estado funcionando desde aproximadamente las 9:30 de esta mañana:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 Hora de inicio de SQL Server
Hora de inicio de SQL Server
Ahora, si busco cómo se ven mis estadísticas de espera (recuerde, acumuladas hasta ahora) usando el script de Paul, veo que TRACEWRITE es mi espera "estándar" actual:
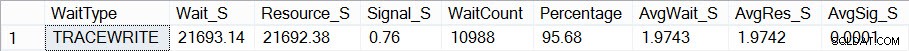 Esperas agregadas actuales
Esperas agregadas actuales
Bien, ahora introduzcamos cinco minutos de contención de tempdb y veamos cómo eso afecta mis estadísticas generales de espera. Tengo una secuencia de comandos que Jonathan usó anteriormente para crear la contención de tempdb y la configuré para que se ejecute durante 5 minutos:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Utilicé un símbolo del sistema para iniciar 10 sesiones que ejecutaron este script y, al mismo tiempo, ejecuté un script que capturó mis estadísticas generales de espera, una instantánea de las esperas durante un período de 5 minutos y luego las estadísticas generales de espera nuevamente. Primero, un pequeño secreto, dado que ignoramos las esperas benignas todo el tiempo, puede ser útil incluirlas en una tabla para que pueda hacer referencia a un objeto en lugar de tener que codificar constantemente una lista de cadenas de exclusión en una consulta. Entonces:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Ahora estamos listos para capturar nuestras esperas:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Si observamos el resultado, podemos ver que mientras se ejecutaban las 10 instancias del script para crear la contención de tempdb, SOS_SCHEDULER_YIELD fue nuestro tipo de espera más frecuente, y también tuvimos esperas PAGELATCH_XX, como se esperaba:
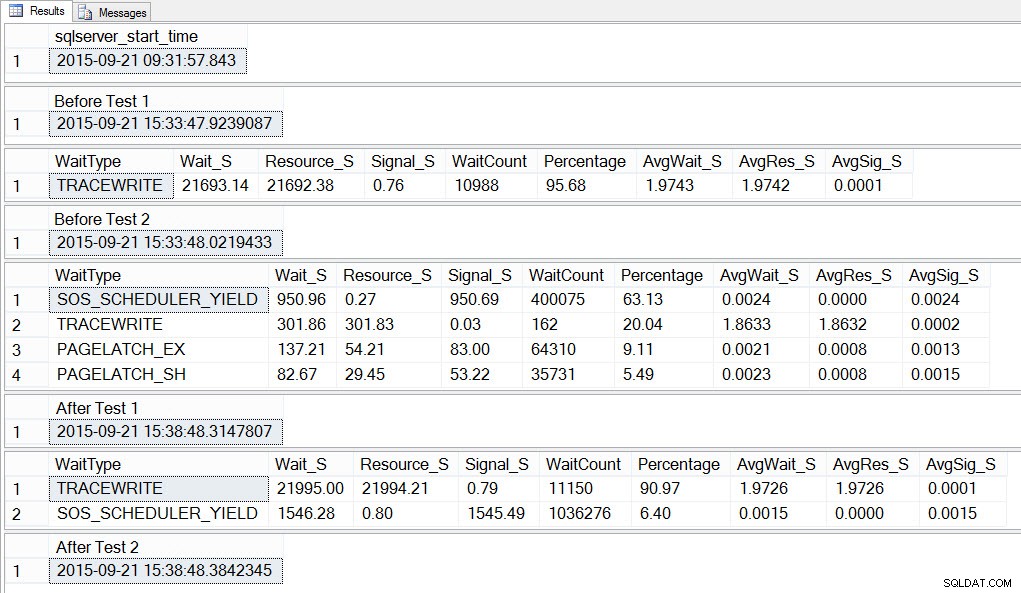
Si observamos las esperas promedio DESPUÉS de que se completó la prueba, nuevamente vemos TRACEWRITE como la espera más alta y vemos SOS_SCHEDULER_YIELD como una espera. Dependiendo de qué más se esté ejecutando en el entorno, esta espera puede persistir o no en nuestras esperas principales durante mucho tiempo, y puede surgir o no como un tipo de espera para investigar.
Captura proactiva de estadísticas de espera
De forma predeterminada, las estadísticas de espera son acumulativas . Sí, puede borrarlos en cualquier momento usando DBCC SQLPERF, pero creo que la mayoría de las personas no lo hacen regularmente, simplemente dejan que se acumulen. Y esto está bien, pero comprenda cómo eso afecta sus datos. Si solo reinicia su instancia cuando la parchea o cuando hay un problema (lo que, con suerte, sucede con poca frecuencia), entonces esos datos podrían acumularse durante meses. Cuantos más datos tenga, más difícil será ver pequeñas variaciones... cosas que podrían ser problemas de rendimiento. Incluso cuando tiene un "gran problema" que afecta a todo su servidor durante varios minutos, como hicimos aquí con tempdb, es posible que no genere un cambio suficiente en sus datos para ser detectado en los datos acumulados. Más bien, debe tomar una instantánea de los datos (capturarlos, esperar unos minutos, capturarlos nuevamente y luego compararlos) para ver qué está sucediendo realmente en este momento. .
Como tal, si solo toma una instantánea de las estadísticas de espera cada pocas horas, entonces los datos que ha recopilado solo muestran la agregación continua a lo largo del tiempo. Tu puedes diferencie esas instantáneas para comprender el rendimiento entre las instantáneas, pero puedo decirle que tener que escribir este código en un gran conjunto de datos es una molestia (pero no soy un desarrollador, así que tal vez sea fácil para usted ).
Mi método tradicional de capturar estadísticas de espera era simplemente tomar una instantánea de sys.dm_os_wait_stats cada pocas horas usando el script original de Paul:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); Luego revisaría y miraría la espera superior para cada instantánea, por ejemplo:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Mi nuevo método alternativo es diferenciar un par de instantáneas de las estadísticas de espera (con dos o tres minutos entre las instantáneas) cada hora más o menos. Esta información me dice exactamente qué estaba esperando el sistema en ese momento:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; ¿Es mejor mi nuevo método? Creo que sí, ya que es una mejor representación de cómo se ven las esperas justo en el momento de la captura, y todavía está muestreando en un intervalo regular. Para ambos métodos, normalmente busco cuál fue la espera más alta en el momento de la captura:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Resultados:
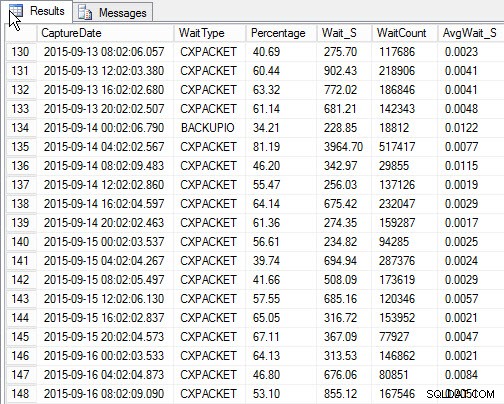 Espera superior para cada instantánea (resultado de muestra)
Espera superior para cada instantánea (resultado de muestra)
El inconveniente, que existía con mi guión original, es que sigue siendo solo una instantánea . Puedo generar la tendencia de las esperas más altas a lo largo del tiempo, pero si hay un problema que ocurre entre las instantáneas, no aparecerá. Entonces, ¿qué puedes hacer?
Podrías aumentar la frecuencia de tus capturas. Quizás en lugar de capturar estadísticas de espera cada hora, las capture cada 15 minutos. O tal vez cada 10. Cuanto más frecuentemente capture los datos, más posibilidades tendrá de detectar un problema de rendimiento.
Su otra opción sería usar una aplicación de terceros, como SQL Sentry Performance Advisor, para monitorear las esperas. Performance Advisor extrae exactamente la misma información del DMV sys.dm_os_wait_stats. Consulta sys.dm_os_wait_stats cada 10 segundos con una consulta muy simple:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
Detrás de escena, Performance Advisor luego toma estos datos y los agrega a su base de datos de monitoreo. Cuando ve los datos, se eliminan las esperas benignas y se calculan los deltas. Además, Performance Advisor tiene una pantalla fantástica (mirar el tablero es mucho mejor que la salida de texto anterior) y puede personalizar la colección si lo desea. Si observamos el Asesor de rendimiento y observamos los datos de todo el día, puedo ver fácilmente dónde tuve un problema en el panel Esperas de SQL Server:
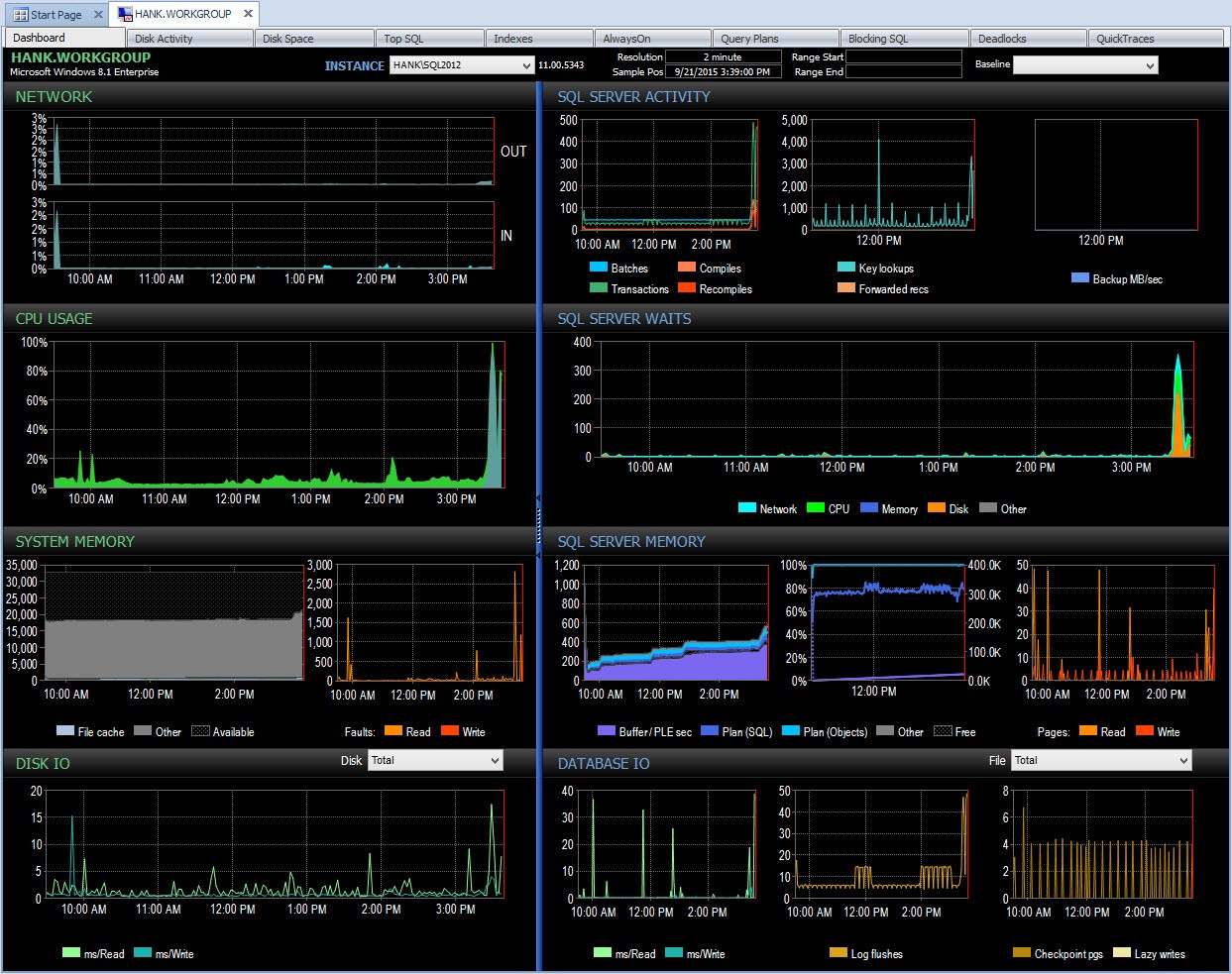 Panel de Performance Advisor del día
Panel de Performance Advisor del día
Y luego puedo profundizar en ese período de tiempo después de las 3:00 p. m. para investigar más a fondo lo que sucedió:
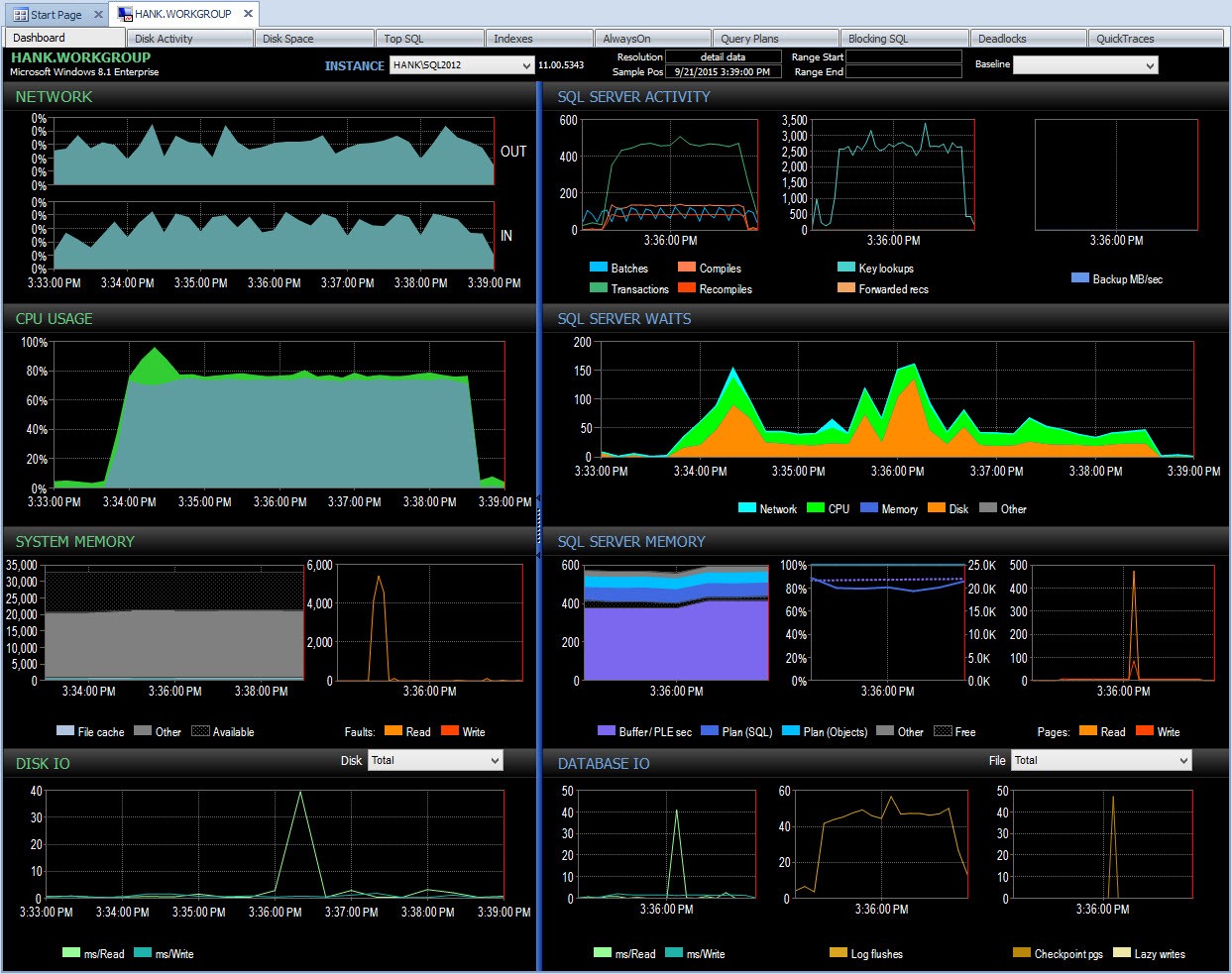 Profundizar en PA durante un problema de rendimiento
Profundizar en PA durante un problema de rendimiento
Monitoreo por mi cuenta, a menos que haya tomado instantáneas de las estadísticas de espera al mismo tiempo con una secuencia de comandos, habré perdido la captura de cualquier dato sobre ese problema de rendimiento. Debido a que Performance Advisor almacena la información durante un período de tiempo prolongado, si tiene un problema de rendimiento, lo hace. tenga los datos de estadísticas de espera (junto con mucha otra información) disponibles para ayudar a investigar el problema, y también tiene datos históricos para que comprenda qué esperas normales existen en su entorno.
Resumen
Cualquiera que sea el método que elija para monitorear las esperas, primero es importante entender cómo SQL Server almacena información de espera, para que comprenda los datos que está viendo si los captura regularmente. Si tiene que ejecutar sus propios scripts para capturar las esperas, tiene la limitación de que es posible que no capture las desviaciones tan fácilmente como lo haría con un software de terceros. Pero está bien:tener cierta cantidad de datos de referencia para que pueda comenzar a comprender qué es "normal" es mejor que no tener nada . A medida que crea su repositorio y comienza a familiarizarse con un entorno, puede adaptar sus scripts de captura según sea necesario para resolver cualquier problema que pueda existir. Si tiene el beneficio del software de terceros, use esa información al máximo y asegúrese de comprender cómo se recopilan y almacenan las esperas.



