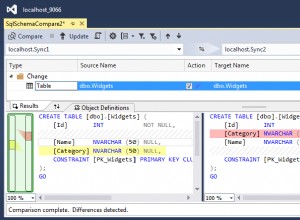
En lo que respecta a los planes de ejecución gráfica, solo hay un icono para una ordenación física en SQL Server:

Este mismo ícono se usa para los tres operadores de ordenación lógica:Ordenar, Ordenar N principales y Ordenar distinto:
Yendo un nivel más profundo, hay cuatro implementaciones diferentes de Ordenar en el motor de ejecución (sin contar la ordenación por lotes para uniones de bucle optimizadas, que no es una ordenación completa y, de todos modos, no es visible en los planes). Si está utilizando SQL Server 2014, el número de implementaciones de clasificación del motor de ejecución aumenta a siete:
- CQScanSortNuevo
- CQScanTopSortNuevo
- CQScanIndexSortNuevo
- CQScanPartitionSortNew (solo SQL Server 2014)
- CQScanInMemSortNuevo
- In-Memory OLTP (Hekaton) procedimiento compilado de forma nativa Top N Sort (solo SQL Server 2014)
- In-Memory OLTP (Hekaton) procedimiento compilado de forma nativa Ordenación general (solo SQL Server 2014)
Este artículo analiza estas implementaciones de clasificación y cuándo se usa cada una en SQL Server. La primera parte cubre los primeros cuatro elementos de la lista.
1. CQScanSortNuevo
Esta es la clase de clasificación más general, utilizada cuando ninguna de las otras opciones disponibles es aplicable. La ordenación general utiliza una concesión de memoria del espacio de trabajo reservada justo antes de que comience la ejecución de la consulta. Esta concesión es proporcional a las estimaciones de cardinalidad y las expectativas de tamaño promedio de fila, y no se puede aumentar después de que comience la ejecución de la consulta.
La implementación actual parece usar una variedad de clasificación de combinación interna (quizás clasificación de combinación binaria), pasando a la clasificación de combinación externa (con múltiples pases si es necesario) si la memoria reservada resulta ser insuficiente. La ordenación por combinación externa usa tempdb físico espacio para ejecuciones de ordenación que no caben en la memoria (comúnmente conocido como derrame de ordenación). La clasificación general también se puede configurar para aplicar la distinción durante la operación de clasificación.
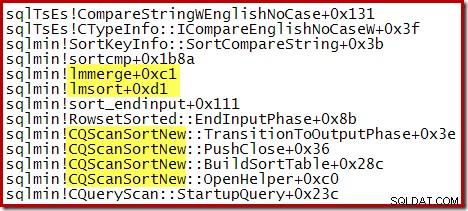
El siguiente seguimiento de pila parcial muestra un ejemplo de CQScanSortNew clases de clasificación de cadenas mediante una clasificación de combinación interna:
En los planes de ejecución, Sort proporciona información sobre la fracción de la asignación de memoria del espacio de trabajo de consulta general que está disponible para Sort cuando lee registros (la fase de entrada) y la fracción disponible cuando los operadores del plan principal consumen la salida ordenada (la fase de salida). ).
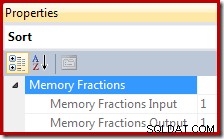
La fracción de concesión de memoria es un número entre 0 y 1 (donde 1 =100 % de la memoria concedida) y es visible en SSMS al resaltar Ordenar y buscar en la ventana Propiedades. El siguiente ejemplo se tomó de una consulta con un solo operador Ordenar, por lo que tiene la asignación de memoria de espacio de trabajo de consulta completa disponible durante las fases de entrada y salida:
Las fracciones de memoria reflejan el hecho de que durante su fase de entrada, Sort tiene que compartir la asignación de memoria de consulta general con los operadores que consumen memoria de ejecución simultánea debajo de él en el plan de ejecución. De manera similar, durante la fase de salida, Sort tiene que compartir la memoria otorgada con los operadores que consumen memoria que se ejecutan simultáneamente y que se encuentran por encima de él en el plan de ejecución.
El procesador de consultas es lo suficientemente inteligente como para saber que algunos operadores están bloqueando (stop-and-go), marcando efectivamente los límites donde la concesión de memoria se puede reciclar y reutilizar. En planes paralelos, la fracción de concesión de memoria disponible para una ordenación general se divide equitativamente entre subprocesos y no se puede volver a equilibrar en tiempo de ejecución en caso de sesgo (una causa común de derrame en planes de ordenación paralelos).
SQL Server 2012 y versiones posteriores incluyen información adicional sobre la concesión de memoria de espacio de trabajo mínima requerida para inicializar operadores de plan que consumen memoria y el deseado concesión de memoria (la cantidad "ideal" de memoria que se estima necesaria para completar toda la operación en la memoria). En un plan de ejecución posterior a la ejecución ("real"), también hay nueva información sobre cualquier retraso en la adquisición de la concesión de memoria, la cantidad máxima de memoria realmente utilizada y cómo se distribuyó la reserva de memoria entre los nodos NUMA.
Los siguientes ejemplos de AdventureWorks usan un CQScanSortNew clasificación general:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; La primera consulta (una ordenación no distinta) produce el siguiente plan de ejecución:
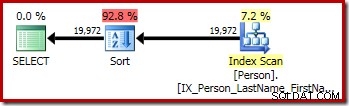
Las consultas segunda y tercera (equivalentes) producen este plan:
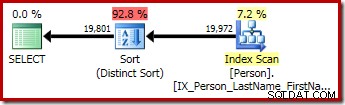
CQScanSortNuevo se puede utilizar tanto para la clasificación general lógica como para la clasificación distinta lógica.
2. CQScanTopSortNuevo
CQScanTopSortNuevo es una subclase de CQScanSortNew se utiliza para implementar un Top N Sort (como sugiere el nombre). CQScanTopSortNuevo delega gran parte del trabajo principal a CQScanSortNew , pero modifica el comportamiento detallado de diferentes maneras, según el valor de N.
Para N> 100, CQScanTopSortNew es esencialmente solo un CQScanSortNew regular sort que automáticamente deja de producir filas ordenadas después de N filas. Para N <=100, CQScanTopSortNew retiene solo los N mejores resultados actuales durante la operación de clasificación y realiza un seguimiento del valor clave más bajo que califica actualmente.
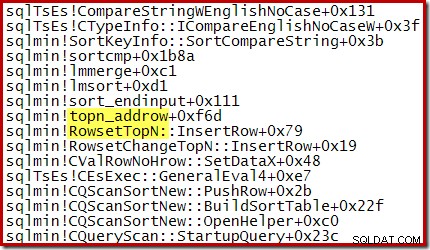
Por ejemplo, durante una clasificación Top N optimizada (donde N <=100), la pila de llamadas presenta RowsetTopN mientras que con la ordenación general en la sección 1 vimos RowsetSorted :
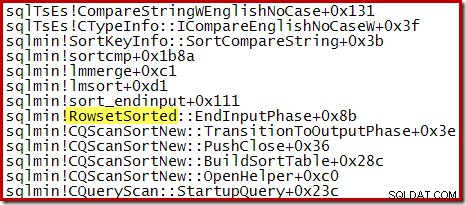
Para una ordenación Top N donde N> 100, la pila de llamadas en la misma etapa de ejecución es la misma que la ordenación general vista anteriormente:
Observe que CQScanTopSortNew el nombre de la clase no aparece en ninguno de esos seguimientos de pila. Esto se debe simplemente a la forma en que funciona la subclasificación. En otros puntos durante la ejecución de estas consultas, CQScanTopSortNew (por ejemplo, Open, GetRow y CreateTopNTable) aparecen explícitamente en la pila de llamadas. Como ejemplo, lo siguiente se tomó en un punto posterior de la ejecución de la consulta y muestra el CQScanTopSortNew nombre de la clase:
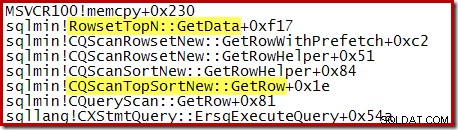
Top N Sort y el Optimizador de consultas
El optimizador de consultas no sabe nada sobre Top N Sort, que es solo un operador de motor de ejecución. Cuando el optimizador produce un árbol de salida con un operador Top físico inmediatamente encima de una ordenación física (no distinta), una reescritura posterior a la optimización puede colapsar las dos operaciones físicas en un solo operador Top N Sort. Incluso en el caso de N> 100, esto representa un ahorro al pasar filas iterativamente entre una salida Ordenar y una entrada Superior.
La siguiente consulta utiliza un par de indicadores de seguimiento no documentados para mostrar el resultado del optimizador y la reescritura posterior a la optimización en acción:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
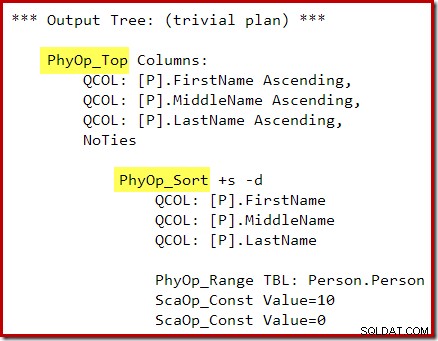
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); El árbol de resultados del optimizador muestra operadores físicos Separados de Clasificación y Clasificación:
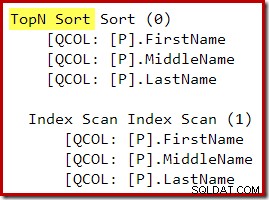
Después de la reescritura posterior a la optimización, Top y Sort se han colapsado en un solo Top N Sort:
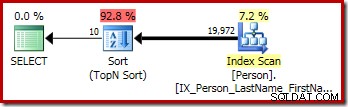
El plan de ejecución gráfico para la consulta T-SQL anterior muestra el único operador Top N Sort:
Rompiendo la reescritura Top N Sort
La reescritura posterior a la optimización de Top N Sort solo puede colapsar una clasificación Top y no distinta adyacente en una clasificación Top N. Agregar DISTINCT (o la cláusula GROUP BY equivalente) a la consulta anterior evitará la reescritura de Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; El plan de ejecución final para esta consulta incluye operadores separados Superior y Ordenar (Distinct Sort):
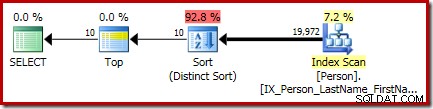
El Ordenar allí es el general CQScanSortNew clase ejecutándose en modo distinto como se vio en la sección 1 anterior.
Una segunda forma de evitar la reescritura en Top N Sort es introducir uno o más operadores adicionales entre Top y Sort. Por ejemplo:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; La salida del optimizador de consultas ahora tiene una operación entre Top y Sort, por lo que no se genera Top N Sort durante la fase de reescritura posterior a la optimización:
El plan de ejecución es:

La secuencia de cómputo (implementada como dos segmentos y un proyecto de secuencia) entre Top y Sort evita el colapso de Top y Sort en un solo operador Top N Sort. Por supuesto, aún se obtendrán resultados correctos de este plan, pero la ejecución puede ser un poco menos eficiente de lo que podría haber sido con el operador combinado Top N Sort.
3. CQScanIndexOrdenarNuevo
CQScanIndexSortNuevo se usa solo para ordenar en los planes de construcción del índice DDL. Reutiliza algunas de las funciones generales de clasificación que ya hemos visto, pero agrega optimizaciones específicas para las inserciones de índices. También es la única clase de clasificación que puede solicitar dinámicamente más memoria después de que haya comenzado la ejecución.
La estimación de la cardinalidad suele ser precisa para un plan de creación de índices porque el número total de filas de la tabla suele ser una cantidad conocida. Eso no quiere decir que las concesiones de memoria para las clasificaciones de planes de creación de índices siempre sean precisas; simplemente hace que sea un poco menos fácil de demostrar. Por lo tanto, el siguiente ejemplo utiliza una extensión no documentada, pero razonablemente conocida, del comando ACTUALIZAR ESTADÍSTICAS para engañar al optimizador haciéndole creer que la tabla en la que estamos creando un índice solo tiene una fila:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; El plan de ejecución posterior a la ejecución ("real") para la creación del índice no muestra una advertencia de clasificación derramada (cuando se ejecuta en SQL Server 2012 o posterior) a pesar de la estimación de 1 fila y las 19 972 filas realmente ordenadas:
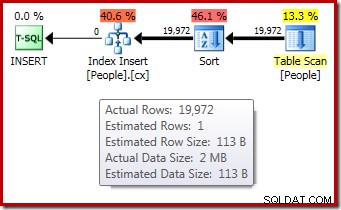
La confirmación de que la concesión de memoria inicial se expandió dinámicamente proviene de observar las propiedades del iterador raíz. Inicialmente, a la consulta se le otorgaron 1024 KB de memoria, pero finalmente consumió 1576 KB:
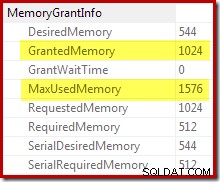
El aumento dinámico en la memoria otorgada también se puede rastrear utilizando el evento extendido del canal de depuración sort_memory_grant_adjustment. Este evento se genera cada vez que se aumenta dinámicamente la asignación de memoria. Si este evento está siendo monitoreado, podemos capturar un seguimiento de la pila cuando se publica, ya sea a través de eventos extendidos (con una configuración incómoda y un indicador de seguimiento) o desde un depurador adjunto, como se muestra a continuación:
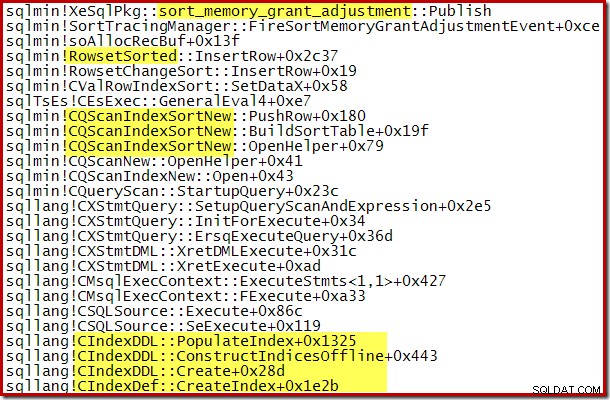
La expansión de concesión de memoria dinámica también puede ayudar con los planes de compilación de índices paralelos donde la distribución de filas entre subprocesos es desigual. Sin embargo, la cantidad de memoria que se puede consumir de esta manera no es ilimitada. SQL Server comprueba cada vez que se necesita una expansión para ver si la solicitud es razonable teniendo en cuenta los recursos disponibles en ese momento.
Se puede obtener información sobre este proceso habilitando el indicador de seguimiento no documentado 1504, junto con 3604 (para la salida de mensajes a la consola) o 3605 (salida al registro de errores de SQL Server). Si el plan de compilación del índice es paralelo, solo 3605 es efectivo porque los trabajadores paralelos no pueden enviar mensajes de seguimiento entre subprocesos a la consola.
La siguiente sección de resultados de seguimiento se capturó mientras se creaba un índice moderadamente grande en una instancia de SQL Server 2014 con memoria limitada:
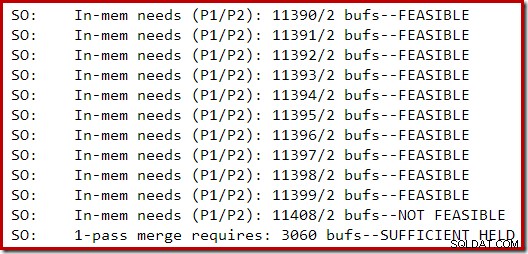
La expansión de la memoria para la ordenación continuó hasta que la solicitud se consideró inviable, momento en el que se determinó que ya había suficiente memoria para que se completara un derrame de ordenación de un solo paso.
4. CQScanPartitionSortNew
Este nombre de clase podría sugerir que este tipo de clasificación se usa para datos de tablas particionadas, o cuando se crean índices en tablas particionadas, pero ninguno de esos es realmente el caso. La clasificación de datos particionados utiliza CQScanSortNew o CQScanTopSortNew como normal; ordenar filas para insertarlas en un índice particionado generalmente usa CQScanIndexSortNew como se ve en la sección 3.
CQScanPartitionSortNew sort class solo está presente en SQL Server 2014. Solo se usa cuando se ordenan las filas por id de partición, antes de la inserción en un índice de almacén de columnas agrupado particionado . Tenga en cuenta que solo se usa para particionado almacén de columnas agrupado; Los planes de inserción de almacén de columnas agrupados regulares (no particionados) no se benefician de una ordenación.
Las inserciones en un índice de almacén de columnas agrupado con particiones no siempre incluirán una ordenación. Es una decisión basada en costos que depende del número estimado de filas a insertar. Si el optimizador estima que vale la pena ordenar las inserciones por partición para optimizar la E/S, el operador de inserción del almacén de columnas tendrá el DMLRequestSort propiedad establecida en verdadero, y un CQScanPartitionSortNew ordenar puede aparecer en el plan de ejecución.
La demostración en esta sección usa una tabla permanente de números secuenciales. Si no tiene uno de esos, puede usar el siguiente script para crear uno:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); La demostración en sí implica la creación de una tabla indexada de almacén de columnas agrupado con particiones e insertar suficientes filas (de la tabla de Números anterior) para convencer al optimizador de usar una ordenación de partición de inserción previa:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; El plan de ejecución para la inserción muestra la ordenación utilizada para garantizar que las filas lleguen al iterador de inserción del almacén de columnas agrupado en orden de ID de partición:

Una pila de llamadas capturada mientras CQScanPartitionSortNew la ordenación estaba en curso se muestra a continuación:
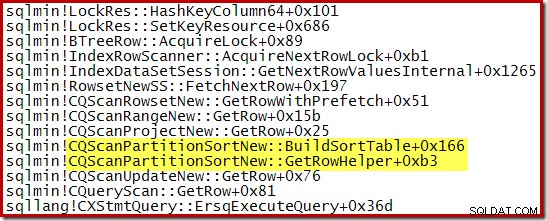
Hay algo más interesante acerca de esta clase de clasificación. Las ordenaciones normalmente consumen toda su entrada en su llamada al método Open. Después de clasificar, devuelven el control a su operador principal. Más tarde, la ordenación comienza a producir filas de salida ordenadas de una en una de la forma habitual a través de llamadas GetRow. CQScanPartitionSortNew es diferente, como puede ver en la pila de llamadas anterior:no consume su entrada durante su método Open; espera hasta que su padre llame a GetRow por primera vez.
No todas las clasificaciones en el ID de partición que aparecen en un plan de ejecución que inserta filas en un índice de almacén de columnas agrupado con particiones serán CQScanPartitionSortNew clasificar. Si la ordenación aparece inmediatamente a la derecha del operador de inserción del índice del almacén de columnas, es muy probable que sea una CQScanPartitionSortNew ordenar.
Finalmente, CQScanPartitionSortNew es una de las dos únicas clases de ordenación que establece la propiedad Ordenación suave expuesta cuando las propiedades del plan de ejecución del operador Ordenar se generan con el indicador de seguimiento no documentado 8666 habilitado:
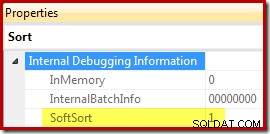
El significado de "clasificación suave" en este contexto no está claro. Se rastrea como una propiedad en el marco del optimizador de consultas y parece probable que esté relacionado con las inserciones de datos particionados optimizados, pero determinar exactamente lo que significa requiere más investigación. Mientras tanto, esta propiedad se puede usar para inferir que se implementa una ordenación con CQScanPartitionSortNew sin adjuntar un depurador. El significado del indicador de propiedad InMemory que se muestra arriba se cubrirá en la parte 2. no indicar si se realizó una ordenación regular en la memoria o no.
Resumen de la primera parte
- CQScanSortNuevo es la clase de clasificación general utilizada cuando no se aplica ninguna otra opción. Parece que usa una variedad de clasificación de combinación interna en la memoria, pasando a la clasificación de combinación externa usando tempdb si se concede espacio de trabajo de memoria resulta ser insuficiente. Esta clase se puede usar para Ordenación general y Ordenación distinta.
- CQScanTopSortNuevo implementa Top N Sort. Donde N <=100, se realiza una ordenación de combinación interna en memoria y nunca se derrama a tempdb . Solo los primeros n elementos actuales se conservan en la memoria durante la ordenación. Para N> 100 CQScanTopSortNew es equivalente a un CQScanSortNew clasificación que se detiene automáticamente después de que se hayan generado N filas. Una ordenación N> 100 puede pasar a tempdb si es necesario.
- La clasificación Top N que se ve en los planes de ejecución es una reescritura de optimización posterior a la consulta. Si el optimizador de consultas produce un árbol de salida con una Ordenación superior y no distinta adyacente, esta reescritura puede colapsar los dos operadores físicos en un solo operador Ordenar N superior.
- CQScanIndexSortNuevo se usa solo en planes DDL de creación de índices. Es la única clase de clasificación estándar que puede adquirir dinámicamente más memoria durante la ejecución. Las clasificaciones de creación de índices aún pueden pasar al disco en algunas circunstancias, incluso cuando SQL Server decide que un aumento de memoria solicitado no es compatible con la carga de trabajo actual.
- CQScanPartitionSortNuevo solo está presente en SQL Server 2014 y se usa solo para optimizar las inserciones en un índice de almacén de columnas agrupado con particiones. Ofrece una "clasificación suave".
La segunda parte de este artículo analizará CQScanInMemSortNew y las dos clasificaciones de procedimientos almacenados compilados de forma nativa de In-Memory OLTP.