Hay un error de regresión en SQL Server 2012 y SQL Server 2014 donde, si reconstruye un índice en línea en paralelo y también experimenta un error fatal, como un tiempo de espera de bloqueo, podría experimentar pérdida o corrupción de datos . Este debería ser un escenario relativamente raro (Phil Brammer tiene una reproducción simple en Connect #795134), pero la pérdida de datos es la pérdida de datos, y no estoy preparado para apostar. La corrección se describe en KB n.º 2969896:CORRECCIÓN:la pérdida de datos en el índice agrupado se produce cuando ejecuta el índice de compilación en línea en SQL Server 2012.
No todos deben preocuparse por este tema. Si no está ejecutando la edición Enterprise (o una equivalente), no puede realizar reconstrucciones paralelas o en línea en primer lugar (y probablemente haya algunas personas en Enterprise que no reconstruyan o no reconstruyan en línea). Si tiene MAXDOP en toda la instancia establecido en 1, no pueden ir en paralelo a menos que lo anule en el nivel de declaración. Pero, si está en 2012 o 2014, ejecuta una edición adecuada y sus reconstrucciones en línea podrían ir en paralelo, es vulnerable a este problema.
Como mencioné anteriormente, este problema podría manifestarse en SQL Server 2012 RTM, Service Pack 1 e incluso Service Pack 2, que se lanzó el 10 de junio. no incluye esta corrección ni ninguna de las correcciones de SP1 CU #10 o #11. Hice un blog sobre esto aquí. La rama RTM está oficialmente fuera de soporte, por lo que no verá una solución allí. El problema también puede ocurrir en SQL Server 2014.
Ahora hay actualizaciones acumulativas disponibles para SQL Server 2012 Service Pack 1 y 2, así como para SQL Server 2014. Un breve resumen de las opciones que recomiendo:
Si su rama / @@VERSION es...
| …deberías… | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| No hacer nada; ya tienes la solución. | |||||
| |||||
| No hacer nada; ya tienes la solución. | |||||
| SQL Server 2014 RTM |
| ||||
| No hacer nada; ya tienes la solución. | |||||
| * Si instala la revisión del SP1 o la actualización acumulativa n.° 11 y luego instala el SP2, deshará esos cambios, incluidos esta corrección. | |||||
Soluciones para el hotfix/CU averse
Dado que todas las sucursales afectadas (bueno, excepto 2012 RTM) tienen una revisión bajo demanda y/o una actualización acumulativa que soluciona el problema, la respuesta fácil es simplemente instalar la actualización correspondiente. Sin embargo, es posible que se encuentre en un escenario en el que la política de su empresa o los ciclos de prueba le impidan implementar estas actualizaciones rápidamente, o tal vez nunca. Entonces, ¿qué otras opciones tienes?
- Puede dejar de realizar reconstrucciones hasta que haya un nuevo paquete de servicio disponible para su sucursal (tal vez pueda quedarse con
REORGANIZE) por ahora). Desafortunadamente, si está en una empresa de "solo paquete de servicio", sus opciones son muy limitadas:puede esforzarse más para cambiar esa política o puede esperar a SQL Server 2012 Service Pack 3 (que puede llevar mucho tiempo o puede simplemente nunca venga (consulte la pregunta frecuente n.º 21 aquí) o SQL Server 2014 Service Pack 1 (que probablemente no veremos antes de que llegue el 2015). - Puede establecer el
max degree of parallelismen toda la instancia a 1, sin embargo, esto puede tener un efecto negativo en el resto de su carga de trabajo:piense en cosas como DBCC de subprocesos múltiples, consultas paralelas contra o entre tablas particionadas y otras operaciones en las que puede querer reducir el paralelismo pero no eliminarlo por completo. Además, esta configuración no afectará una reconstrucción en línea con, digamos, unMAXDOP = 8explícito codificado en el comando, ya que esto anulará elsp_configureentorno.
- Puede agregar el
WITH (MAXDOP = 1)opción manualmente a todos sus comandos de reconstrucción. (Nota:no tiene que hacer esto para los índices XML, ya que inherentemente se ejecutan en un solo subproceso, pero lo aplicaría a todas las reconstrucciones para mantener la coherencia y evitar cualquier lógica condicional innecesaria).
- Puede configurar sus trabajos de mantenimiento de índices para que se ejecuten como un inicio de sesión específico y luego usar el regulador de recursos para crear un grupo de carga de trabajo que limite el
MAX_DOPde ese inicio de sesión a 1, independientemente de lo que estén haciendo. Tengo un ejemplo de esto en el documento técnico de 2008 que escribí con Boris Baryshnikov, Uso del gobernador de recursos, en la sección titulada "Limitación del paralelismo para trabajos intensivos en segundo plano".
- Si está utilizando la solución de mantenimiento de índices de Ola Hallengren, puede agregar
@MaxDopparámetro a sus llamadas adbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Si está utilizando SQL Sentry Fragmentation Manager, puede dictar el nivel de
MAXDOPpara usar en Configuración, y puede hacerlo en toda la empresa, por instancia, por base de datos o incluso por índice individual (en este caso, probablemente desee configurar esto por instancia, para todas las instancias sin una solución disponible):
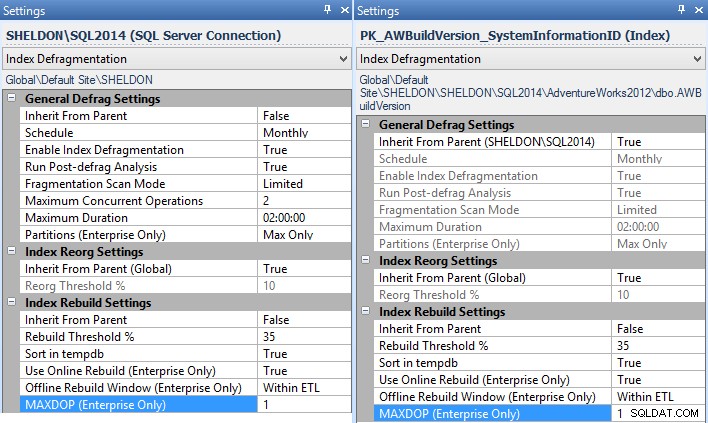
Configuración de Fragmentation Manager para la instancia (izquierda) y un índice individual (derecha). - Si usa Planes de mantenimiento para la reconstrucción de sus índices, tendrá que cambiarlos para usar Ejecutar tareas de declaración T-SQL y escribir su
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);comandos manualmente (así que también puede cambiar a una solución automatizada). Vea, la tarea de reconstrucción del índice no tiene una propiedad expuesta paraMAXDOP, aunque ha sido solicitado en múltiples ocasiones (la más reciente en 2012, por Alberto Morillo, y ya en 2006, por Linchi Shea). Y mire todas estas otras propiedades útiles que exponen, comoAdvSortInTempdb,ObjectTypeSelectionyTaskAllowesDatbaseSelection[¡sic!]:
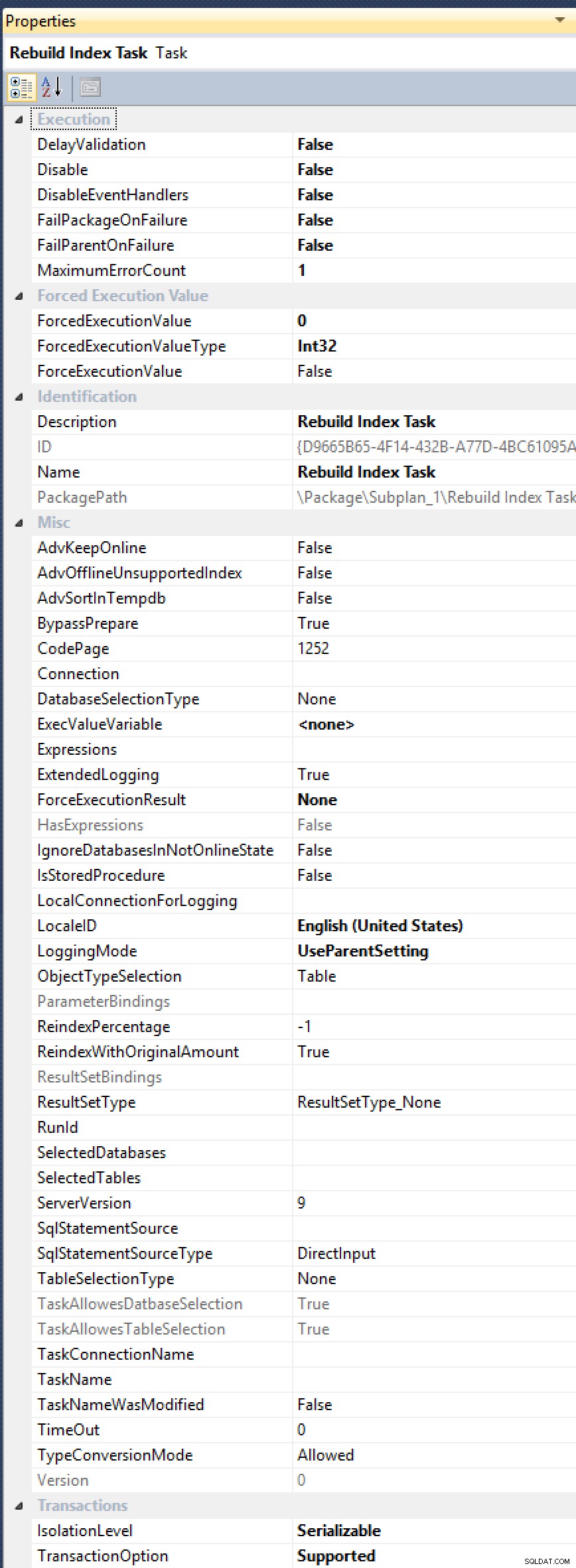
Todas esas opciones, pero aún no hay cura para MAXDOP.