Benjamin Nevarez es un consultor independiente con sede en Los Ángeles, California, que se especializa en el ajuste y la optimización de consultas de SQL Server. Es autor de "SQL Server 2014 Query Tuning &Optimization" y "Inside the SQL Server Query Optimizer" y coautor de "SQL Server 2012 Internals". Con más de 20 años de experiencia en bases de datos relacionales, Benjamin también ha sido ponente en muchas conferencias de SQL Server, incluidas PASS Summit, SQL Server Connections y SQLBits. El blog de Benjamin se puede encontrar en http://www.benjaminnevarez.com y también se le puede contactar por correo electrónico en admin en benjaminnevarez punto com y en twitter en @BenjaminNevarez.
Si bien la mayor parte de la información, los blogs y la documentación sobre SQL Server 2014 se han centrado en Hekaton y otras funciones nuevas, no se han proporcionado muchos detalles sobre el nuevo estimador de cardinalidad. Actualmente, BOL solo habla indirectamente sobre esto en la sección Novedades (Motor de base de datos), diciendo que SQL Server 2014 "incluye mejoras sustanciales en el componente que crea y optimiza los planes de consulta" y el ALTER DATABASE instrucción muestra cómo habilitar o deshabilitar su comportamiento. Afortunadamente, podemos obtener información adicional leyendo el artículo de investigación Testing Cardinality Estimation Models in SQL Server de Campbell Fraser et al. Aunque el enfoque del documento es el proceso de control de calidad del nuevo modelo de estimación, también ofrece una introducción básica al nuevo estimador de cardinalidad y la motivación de su rediseño.
Entonces, ¿qué es un estimador de cardinalidad? Un estimador de cardinalidad es el componente del procesador de consultas cuyo trabajo es estimar el número de filas devueltas por operaciones relacionales en una consulta. El optimizador de consultas utiliza esta información, junto con algunos otros datos, para seleccionar un plan de ejecución eficiente. La estimación de cardinalidad es intrínsecamente inexacta, ya que es un modelo matemático que se basa en información estadística. También se basa en varios supuestos que, aunque no están documentados, se han conocido a lo largo de los años, algunos de ellos incluyen los supuestos de uniformidad, independencia, contención e inclusión. A continuación se ofrece una breve descripción de estas suposiciones.
- Uniformidad . Se usa cuando se desconoce la distribución de un atributo, por ejemplo, dentro de filas de rango en un paso de histograma o cuando no hay un histograma disponible.
- Independencia . Se utiliza cuando los atributos de una relación son independientes, a menos que se conozca una correlación entre ellos.
- Contención . Se usa cuando dos atributos pueden ser iguales, se supone que son iguales.
- Inclusión . Se usa cuando se compara un atributo con una constante, se supone que siempre hay una coincidencia.
Es interesante que recientemente hablé sobre algunas de las limitaciones de estas suposiciones en mi última charla en la cumbre PASS, llamada Cómo vencer las limitaciones del optimizador de consultas. Sin embargo, me sorprendió leer en el artículo que los autores admiten que, según su experiencia en la práctica, estas suposiciones son "frecuentemente incorrectas".
El estimador de cardinalidad actual se escribió junto con todo el procesador de consultas para SQL Server 7.0, que se lanzó en diciembre de 1998. Obviamente, este componente ha enfrentado múltiples cambios durante varios años y múltiples versiones de SQL Server, incluidas correcciones, ajustes y extensiones para acomodar la estimación de cardinalidad para las nuevas características de T-SQL. Entonces puede estar pensando, ¿por qué reemplazar un componente que se ha utilizado con éxito durante aproximadamente 15 años?
Por qué un nuevo estimador de cardinalidad
El documento explica algunas de las razones del rediseño, que incluyen:
- Para adaptar el estimador de cardinalidad a los nuevos patrones de carga de trabajo.
- Los cambios realizados en el estimador de cardinalidad a lo largo de los años dificultaron la "depuración, predicción y comprensión" del componente.
- Tratar de mejorar el modelo actual fue difícil con la arquitectura actual, por lo que se creó un nuevo diseño, centrado en la separación de tareas de (a) decidir cómo calcular una estimación particular y (b) realizar realmente el cálculo .
No estoy seguro de si Microsoft publicará más detalles sobre el nuevo estimador de cardinalidad. Después de todo, no se publicaron tantos detalles sobre el antiguo estimador de cardinalidad en 15 años; por ejemplo, cómo se calcula alguna estimación de cardinalidad específica. Por otro lado, hay nuevos eventos extendidos que podemos usar para solucionar problemas con la estimación de cardinalidad, o simplemente para explorar cómo funciona. Estos eventos incluyen query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors y query_rpc_set_cardinality .
Planificar regresiones
Una preocupación importante que viene a la mente con un cambio tan grande dentro del optimizador de consultas son las regresiones del plan. El miedo a las regresiones del plan se ha considerado el mayor obstáculo para las mejoras del optimizador de consultas. Las regresiones son problemas que se presentan después de aplicar una solución al optimizador de consultas y, a veces, se denominan los clásicos "dos errores hacen un acierto". Esto puede suceder cuando dos malas estimaciones, por ejemplo una que sobreestima un valor y la segunda que lo subestima, se anulan entre sí, dando afortunadamente una buena estimación. Corregir solo uno de estos valores ahora puede conducir a una mala estimación que puede afectar negativamente la elección del plan y provocar una regresión.
Para ayudar a evitar regresiones relacionadas con el nuevo estimador de cardinalidad, SQL Server proporciona una forma de habilitarlo o deshabilitarlo, ya que depende del nivel de compatibilidad de la base de datos. Esto se puede cambiar usando ALTER DATABASE declaración, como se indicó anteriormente. Establecer una base de datos en el nivel de compatibilidad 120 utilizará el nuevo estimador de cardinalidad, mientras que un nivel de compatibilidad inferior a 120 utilizará el antiguo estimador de cardinalidad. Además, una vez que esté usando un estimador de cardinalidad específico, hay dos indicadores de seguimiento que puede usar para cambiar al otro. Aunque por el momento no veo las marcas de seguimiento documentadas en ninguna parte, se mencionan como parte de la descripción de query_optimizer_force_both_cardinality_estimation_behaviors evento extendido. El indicador de rastreo 2312 se puede usar para habilitar el nuevo estimador de cardinalidad, mientras que el indicador de rastreo 9481 se puede usar para deshabilitarlo. Incluso puede usar las marcas de rastreo para una consulta específica usando QUERYTRACEON sugerencia (aunque aún no está documentado si esto será compatible).
Ejemplos
Finalmente, el documento también menciona algunos escenarios probados, como la clave principal superpoblada, la unión simple o el problema de la clave ascendente. También muestra cómo los autores experimentaron con múltiples escenarios (o variaciones del modelo) y en algunos casos “relajaron” algunas de las suposiciones hechas por el estimador de cardinalidad, por ejemplo, en el caso de la suposición de independencia, pasando de independencia completa a correlación completa. y algo intermedio hasta que se encontraron buenos resultados.
Aunque no se proporcionan detalles en el documento, decido comenzar a probar algunos de estos escenarios para tratar de comprender cómo funciona el nuevo estimador de cardinalidad. Por ahora, le mostraré un ejemplo usando la suposición de independencia y las teclas ascendentes. También probé la suposición de uniformidad, pero hasta ahora no pude encontrar ninguna diferencia en la estimación.
Comencemos con el ejemplo de la suposición de independencia. Primero veamos el comportamiento actual. Para eso, asegúrese de estar usando el antiguo estimador de cardinalidad ejecutando la siguiente instrucción en la base de datos AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Luego ejecuta:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Obtenemos un estimado de 196 registros como se muestra a continuación:

De manera similar, la siguiente declaración obtendrá un estimado de 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Si usamos ambos predicados, tenemos la siguiente consulta, que tendrá un número estimado de filas de 1.93862 (redondeado a 2 filas si usa SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Este valor se calcula asumiendo total independencia de ambos predicados, para lo cual se utiliza la fórmula (196 * 194) / 19614.0 (donde 19614 es el número total de filas de la tabla). El uso de una correlación total debería darnos una estimación de 194, ya que todos los registros con el código postal 91502 pertenecen a Burbank. El nuevo estimador de cardinalidad estima un valor que no asume independencia total o correlación total. Cambie al nuevo estimador de cardinalidad usando la siguiente instrucción:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Ejecutar la misma declaración nuevamente dará una estimación de 19.3931 filas, que puede ver que es un valor entre asumir independencia total y correlación total (redondeado a 19 filas en Plan Explorer). La fórmula utilizada es selectividad del filtro más selectivo * SQRT (selectividad del siguiente filtro más selectivo) o (194/19614.0) * SQRT (196/19614.0) * 19614 que da 19.393:

Si ha habilitado el nuevo estimador de cardinalidad en el nivel de la base de datos y desea deshabilitarlo para una consulta específica para evitar una regresión del plan, puede usar el indicador de seguimiento 9481 como se explicó anteriormente:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Nota:la sugerencia de consulta QUERYTRACEON se utiliza para aplicar un indicador de seguimiento en el nivel de consulta y actualmente solo se admite en una cantidad limitada de escenarios. Para obtener más información sobre la sugerencia de consulta QUERYTRACEON, puede consultar http://support.microsoft.com/kb/2801413.
Ahora veamos el problema de la clave ascendente, un tema que he explicado con más detalle en esta publicación. La recomendación tradicional de Microsoft para solucionar este problema es actualizar manualmente las estadísticas después de cargar los datos, como se explica aquí, que describe el problema de la siguiente manera:
Las estadísticas sobre columnas clave ascendentes o descendentes, como IDENTIDAD o columnas de marca de tiempo en tiempo real, pueden requerir actualizaciones de estadísticas más frecuentes que las que realiza el optimizador de consultas. Las operaciones de inserción agregan nuevos valores a las columnas ascendentes o descendentes. La cantidad de filas agregadas puede ser demasiado pequeña para activar una actualización de estadísticas. Si las estadísticas no están actualizadas y las consultas se seleccionan de las filas agregadas más recientemente, las estadísticas actuales no tendrán estimaciones de cardinalidad para estos nuevos valores. Esto puede dar como resultado estimaciones de cardinalidad imprecisas y un rendimiento lento de las consultas. Por ejemplo, una consulta que selecciona de las fechas de pedidos de ventas más recientes tendrá estimaciones de cardinalidad inexactas si las estadísticas no se actualizan para incluir estimaciones de cardinalidad para las fechas de pedidos de ventas más recientes.
La recomendación de mi artículo era utilizar las marcas de seguimiento 2389 y 2390, que fueron publicadas por primera vez por Ian Jose en su artículo Teclas ascendentes y estadísticas de corrección rápida automática. Puede leer mi artículo para obtener una explicación y un ejemplo sobre cómo usar estas marcas de seguimiento para evitar este problema. Estos indicadores de rastreo aún funcionan en SQL Server 2014 CTP2. Pero aún mejor, ya no son necesarios si está utilizando el nuevo estimador de cardinalidad.
Usando el mismo ejemplo en mi publicación:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Inserte algunos datos:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Desde que creamos un índice, solo tenemos nuevas estadísticas. Ejecutar la siguiente consulta creará una buena estimación de 35 filas:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Si insertamos nuevos datos:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Puede ver la estimación con el antiguo estimador de cardinalidad como se muestra a continuación:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Dado que la pequeña cantidad de registros insertados no fue suficiente para desencadenar una actualización automática del objeto de estadísticas, el histograma actual no tiene en cuenta los nuevos registros agregados y el optimizador de consultas usa un estimado de 1 fila. Opcionalmente, puede usar las marcas de rastreo 2389 y 2390 para ayudar a obtener una mejor estimación. Pero si intenta la misma consulta con el nuevo estimador de cardinalidad, obtiene la siguiente estimación:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
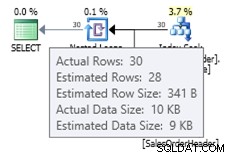
En este caso, obtenemos una mejor estimación que el antiguo estimador de cardinalidad (o obtenemos la misma estimación que usando las marcas de seguimiento 2389 o 2390). El valor estimado de 27,9631 (nuevamente, redondeado a 28 por Plan Explorer) se calcula utilizando la información de densidad del objeto de estadísticas multiplicada por el número de filas de la tabla; es decir, 0.0008992806 * 31095. El valor de densidad se puede obtener usando:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Finalmente, tenga en cuenta que nada de lo mencionado en este artículo está documentado, y este es el comportamiento que he observado hasta ahora en SQL Server 2014 CTP2. Cualquiera de esto podría cambiar en una versión posterior de CTP o RTM del producto.