El principio de "No te repitas" sugiere que debes reducir la repetición. Esta semana me encontré con un caso en el que DRY debería tirarse por la ventana. También hay otros casos (por ejemplo, funciones escalares), pero este era interesante y tenía que ver con la lógica bit a bit.
Imaginemos la siguiente tabla:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Los bits "WheelFlag" representan las siguientes opciones:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Así que las combinaciones posibles son:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Dejemos de lado los argumentos, al menos por ahora, sobre si esto debe empaquetarse en un solo TINYINT en primer lugar, o almacenarse como columnas separadas, o usar un modelo EAV... arreglar el diseño es un tema aparte. Se trata de trabajar con lo que tienes.
Para que los ejemplos sean útiles, llenemos esta tabla con un montón de datos aleatorios. (Y supondremos, para simplificar, que esta tabla contiene solo pedidos que aún no se han enviado). Esto insertará 50 000 filas de distribución aproximadamente igual entre las seis combinaciones de opciones:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Si miramos el desglose, podemos ver esta distribución. Tenga en cuenta que sus resultados pueden diferir ligeramente de los míos dependiendo de los objetos en su sistema:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Resultados:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Ahora, digamos que es martes y acabamos de recibir un envío de ruedas de 18", que anteriormente estaban agotadas. Esto significa que podemos satisfacer todos los pedidos que requieren ruedas de 18", tanto las que tienen llantas mejoradas (6), y los que no (2). Así que *podríamos* escribir una consulta como la siguiente:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); En la vida real, por supuesto, realmente no puedes hacer eso; ¿Qué sucede si se agregan más opciones más adelante, como bloqueos de ruedas, garantía de por vida para las ruedas o múltiples opciones de llantas? No desea tener que escribir una serie de valores IN() para cada combinación posible. En su lugar, podemos escribir una operación BITWISE AND, para encontrar todas las filas donde se establece el segundo bit, como:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Esto me da los mismos resultados que la consulta IN(), pero si los comparo usando SQL Sentry Plan Explorer, el rendimiento es bastante diferente:

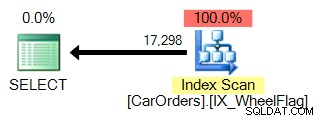
Es fácil ver por qué. El primero utiliza una búsqueda de índice para aislar las filas que satisfacen la consulta, con un filtro en la columna WheelFlag:
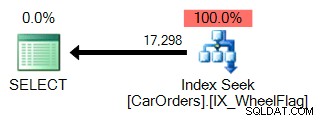

El segundo usa un escaneo, junto con una conversión implícita y estadísticas terriblemente inexactas. Todo debido al operador BITWISE AND:


Entonces, ¿qué significa esto? En el fondo, esto nos dice que la operación BITWISE AND no es sargable .
Pero no se pierde toda esperanza.
Si ignoramos el principio DRY por un momento, podemos escribir una consulta un poco más eficiente siendo un poco redundante para aprovechar el índice en la columna WheelFlag. Suponiendo que buscamos cualquier opción de WheelFlag por encima de 0 (sin ninguna actualización), podemos volver a escribir la consulta de esta manera, diciéndole a SQL Server que el valor de WheelFlag debe ser al menos el mismo valor que flag (lo que elimina 0 y 1 ), y luego agregar la información complementaria que también debe contener esa bandera (eliminando así 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
La parte>=de esta cláusula obviamente está cubierta por la parte BITWISE, por lo que aquí es donde violamos DRY. Pero debido a que esta cláusula que hemos agregado es sargable, relegar la operación BITWISE AND a una condición de búsqueda secundaria todavía produce el mismo resultado y la consulta general produce un mejor rendimiento. Vemos una búsqueda de índice similar a la versión codificada de la consulta anterior, y aunque las estimaciones están aún más alejadas (algo que puede abordarse como un problema separado), las lecturas siguen siendo más bajas que con la operación BITWISE AND sola:

También podemos ver que se usa un filtro contra el índice, que no vimos cuando usamos la operación BITWISE AND solo:

Conclusión
No tengas miedo de repetirte. Hay momentos en que esta información puede ayudar al optimizador; aunque puede que no sea completamente intuitivo *agregar* criterios para mejorar el rendimiento, es importante comprender cuándo las cláusulas adicionales ayudan a reducir los datos para el resultado final en lugar de hacer que sea "fácil" para el optimizador encontrar las filas exactas solo.