Esto es parte de una serie de operadores problemáticos internos de SQL Server. Asegúrese de leer la primera publicación y la segunda publicación de Kalen sobre este tema.
SQL Server existe desde hace más de 30 años y yo he estado trabajando con SQL Server durante casi el mismo tiempo. He visto muchos cambios a lo largo de los años (¡y décadas!) y versiones de este increíble producto. En estas publicaciones, compartiré con ustedes cómo veo algunas de las características o aspectos de SQL Server, a veces junto con un poco de perspectiva histórica.
La última vez hablé sobre el hash en un plan de consulta de SQL Server como un operador potencialmente problemático en el diagnóstico del servidor SQL. Hashing se usa con frecuencia para uniones y agregaciones cuando no hay un índice útil. Y al igual que los escaneos (de los que hablé en la primera publicación de esta serie), hay momentos en los que el hashing es en realidad una mejor opción que las alternativas. Para hash joins, una de las alternativas es LOOP JOIN, de la que también les hablé la última vez.
En este post, te hablaré de otra alternativa para el hashing. La mayoría de las alternativas al hash requieren que los datos estén ordenados, por lo que el plan debe incluir un operador SORT o los datos requeridos ya deben estar ordenados debido a los índices existentes.
Diferentes tipos de uniones para diagnósticos de SQL Server
Para las operaciones JOIN, el tipo de JOIN más común y útil es LOOP JOIN. Describí el algoritmo para un LOOP JOIN en la publicación anterior. Aunque no es necesario ordenar los datos en sí mismos para un LOOP JOIN, la presencia de un índice en la tabla interna hace que la combinación sea mucho más eficiente y, como debe saber, la presencia de un índice implica cierta clasificación. Mientras que un índice agrupado ordena los datos en sí mismo, un índice no agrupado ordena las columnas clave del índice. De hecho, en la mayoría de los casos, sin el índice, el optimizador de SQL Server optará por utilizar el algoritmo HASH JOIN. Vimos esto en el ejemplo la última vez, que sin índices, se eligió HASH JOIN, y con índices, obtuvimos LOOP JOIN.
El tercer tipo de combinación es MERGE JOIN. Este algoritmo funciona en dos conjuntos de datos ya ordenados. Si estamos tratando de combinar (o UNIR) dos conjuntos de datos que ya están ordenados, solo se necesita una sola pasada por cada conjunto para encontrar las filas coincidentes. Aquí está el pseudocódigo para el algoritmo de combinación de combinación:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Aunque MERGE JOIN es un algoritmo muy eficiente, requiere que ambos conjuntos de datos de entrada estén ordenados por la clave de unión, lo que generalmente significa tener un índice agrupado en la clave de unión para ambas tablas. Dado que solo obtiene un índice agrupado por tabla, elegir la columna de clave agrupada solo para permitir que ocurran MERGE JOINS podría no ser la mejor opción general para la clave de agrupamiento.
Por lo general, no recomiendo que intente crear índices solo con el propósito de MERGE JOINS, pero si termina obteniendo un MERGE JOIN debido a índices ya existentes, generalmente es algo bueno. Además de requerir que ambos conjuntos de datos de entrada estén ordenados, MERGE JOIN también requiere que al menos uno de los conjuntos de datos tenga valores únicos para la clave de combinación.
Veamos un ejemplo. Primero, recrearemos los Encabezados y Detalles tablas:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
A continuación, mire el plan para unir estas tablas:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Este es el plan:

Tenga en cuenta que incluso con un índice agrupado en ambas tablas, obtenemos un HASH JOIN. Podemos reconstruir uno de los índices para que sea ÚNICO. En este caso, tiene que ser el índice de los Encabezados porque es la única que tiene valores únicos para SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Ahora, vuelva a ejecutar la consulta y observe que el plan funciona como MERGE JOIN.

Estos planes se benefician de tener los datos ya ordenados en un índice, ya que el plan de ejecución puede aprovechar la clasificación. Pero a veces, SQL Server tiene que ordenar como parte de la ejecución de su consulta. Ocasionalmente, puede ver aparecer un operador ORDENAR en un plan, incluso si no solicita una salida ordenada. Si SQL Server cree que MERGE JOIN podría ser una buena opción, pero una de las tablas no tiene el índice agrupado adecuado y es lo suficientemente pequeña como para que la clasificación sea muy económica, se podría realizar una ORDENACIÓN para permitir que MERGE JOIN sea usado.
Pero, por lo general, el operador SORT aparece en las consultas en las que solicitamos datos ordenados con ORDER BY, como en el siguiente ejemplo.
SELECT * FROM Details
ORDER BY ProductID;
GO

El índice agrupado se escanea (que es lo mismo que escanear la tabla) y luego las filas se ordenan según lo solicitado.
Tratar con el índice agrupado ya ordenado
Pero, ¿qué sucede si los datos ya están ordenados en un índice agrupado y la consulta incluye un ORDEN POR en la columna de clave agrupada? En el ejemplo anterior, creamos un índice agrupado en SalesOrderID en la tabla Detalles. Mire las siguientes dos consultas:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
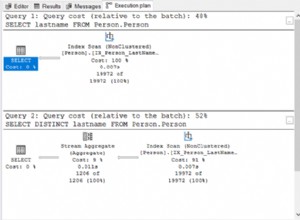
Si ejecutamos estas consultas juntas, la ventana de análisis del paquete de ajuste de Quest Spotlight indica que los dos planes tienen el mismo costo; cada uno es el 50% del total. Entonces, ¿cuál es realmente la diferencia entre ellos?
Ambas consultas están escaneando el índice agrupado y SQL Server sabe que si las páginas del nivel hoja se siguen en orden, los datos volverán en orden de clave agrupada. No es necesario realizar una clasificación adicional, por lo que no se agrega ningún operador SORT al plan. Pero hay una diferencia. Podemos hacer clic en el operador de escaneo de índice agrupado y obtendremos información detallada.
Primero, mire la información detallada para el primer plan, para la consulta sin ORDER BY.

Los detalles nos dicen que la propiedad "Ordenado" es Falsa. Aquí no se exige que los datos se devuelvan ordenados. Resulta que, en la mayoría de los casos, la forma más fácil de recuperar los datos es seguir las páginas del índice agrupado, por lo que los datos terminarán devolviéndose en orden, pero no hay garantía. Lo que significa la propiedad False es que no hay ningún requisito de que SQL Server siga las páginas ordenadas para devolver el resultado. En realidad, hay otras formas en que SQL Server puede obtener todas las filas de la tabla, sin seguir el índice agrupado. Si durante la ejecución, SQL Server elige usar un método diferente para obtener las filas, no veríamos resultados ordenados.
Para la segunda consulta, los detalles se ven así:
 Debido a que la consulta incluía ORDER BY, EXISTE el requisito de que los datos se devuelvan ordenados y SQL Server seguirá las páginas del índice agrupado, en orden.
Debido a que la consulta incluía ORDER BY, EXISTE el requisito de que los datos se devuelvan ordenados y SQL Server seguirá las páginas del índice agrupado, en orden.
Lo más importante que debe recordar aquí es que NO hay garantía de datos ordenados si no incluye ORDER BY en su consulta. ¡Solo porque tiene un índice agrupado, todavía no hay garantía! Incluso si cada vez que ejecutó la consulta durante el año pasado, obtuvo los datos nuevamente en orden sin el ORDEN POR, no hay garantía de que continuará recuperando los datos en orden. El uso de ORDER BY es la única forma de garantizar el orden en que se devuelven los resultados.
Sugerencias para usar operaciones de ordenación
Entonces, ¿se debe evitar una SORT en los diagnósticos del servidor SQL? Al igual que los escaneos y las operaciones hash, la respuesta es, por supuesto, "depende". La clasificación puede ser muy costosa, especialmente en grandes conjuntos de datos. La indexación adecuada ayuda a SQL Server a evitar realizar operaciones SORT porque un índice básicamente significa que sus datos están preordenados. Pero la indexación tiene un costo. Hay un costo de almacenamiento, además del costo de mantenimiento, para cada índice. Si sus datos están muy actualizados, debe mantener la cantidad de índices al mínimo.
Si encuentra que algunas de sus consultas de ejecución lenta muestran operaciones SORT en sus planes, y si esos SORT se encuentran entre los operadores más costosos del plan, puede considerar la creación de índices que permitan a SQL Server evitar la clasificación. Pero deberá realizar pruebas exhaustivas para asegurarse de que los índices adicionales no ralenticen otras consultas que son cruciales para el rendimiento general de su aplicación.