Bueno, para responder a su pregunta de por qué SQL Server está haciendo esto, la respuesta es que la consulta no se compila en un orden lógico, cada declaración se compila por su propio mérito, por lo que cuando se genera el plan de consulta para su declaración de selección, el optimizador no sabe que @val1 y @Val2 se convertirán en 'val1' y 'val2' respectivamente.
Cuando SQL Server no conoce el valor, tiene que adivinar cuántas veces aparecerá esa variable en la tabla, lo que a veces puede conducir a planes subóptimos. Mi punto principal es que la misma consulta con diferentes valores puede generar diferentes planes. Imagina este sencillo ejemplo:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Todo lo que he hecho aquí es crear una tabla simple y agregar 1000 filas con valores del 1 al 10 para la columna val , sin embargo 1 aparece 991 veces, y los otros 9 solo aparecen una vez. La premisa es esta consulta:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Sería más eficiente simplemente escanear toda la tabla, que usar el índice para una búsqueda, luego hacer 991 búsquedas de marcadores para obtener el valor de Filler , sin embargo, con solo 1 fila, la siguiente consulta:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
será más eficiente hacer una búsqueda de índice y una búsqueda de un solo marcador para obtener el valor de Filler (y ejecutar estas dos consultas lo ratificará)
Estoy bastante seguro de que el límite para una búsqueda y una búsqueda de marcadores en realidad varía según la situación, pero es bastante bajo. Usando la tabla de ejemplo, con un poco de prueba y error, descubrí que necesitaba el Val columna para tener 38 filas con el valor 2 antes de que el optimizador realizara un escaneo completo de la tabla en una búsqueda de índice y búsqueda de marcadores:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Entonces, para este ejemplo, el límite es 3.7% de filas coincidentes.
Dado que la consulta no sabe cuántas filas coincidirán cuando usa una variable que tiene que adivinar, y la forma más sencilla es averiguar el número total de filas y dividirlo por el número total de valores distintos en la columna. entonces, en este ejemplo, el número estimado de filas para WHERE val = @Val es 1000/10 =100, el algoritmo real es más complejo que esto, pero por ejemplo, esto servirá. Entonces, cuando miramos el plan de ejecución para:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
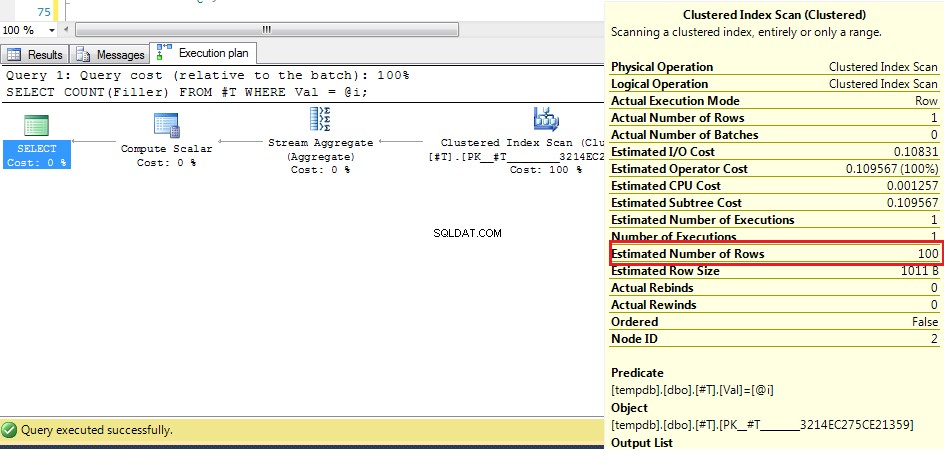
Podemos ver aquí (con los datos originales) que el número estimado de filas es 100, pero las filas reales son 1. De los pasos anteriores sabemos que con más de 38 filas, el optimizador optará por un análisis de índice agrupado en lugar de un índice. seek, por lo que dado que la mejor suposición para el número de filas es mayor que esto, el plan para una variable desconocida es un escaneo de índice agrupado.
Solo para probar aún más la teoría, si creamos la tabla con 1000 filas de números del 1 al 27 distribuidas uniformemente (por lo que el recuento estimado de filas será de aproximadamente 1000/27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Luego ejecute la consulta nuevamente, obtenemos un plan con una búsqueda de índice:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
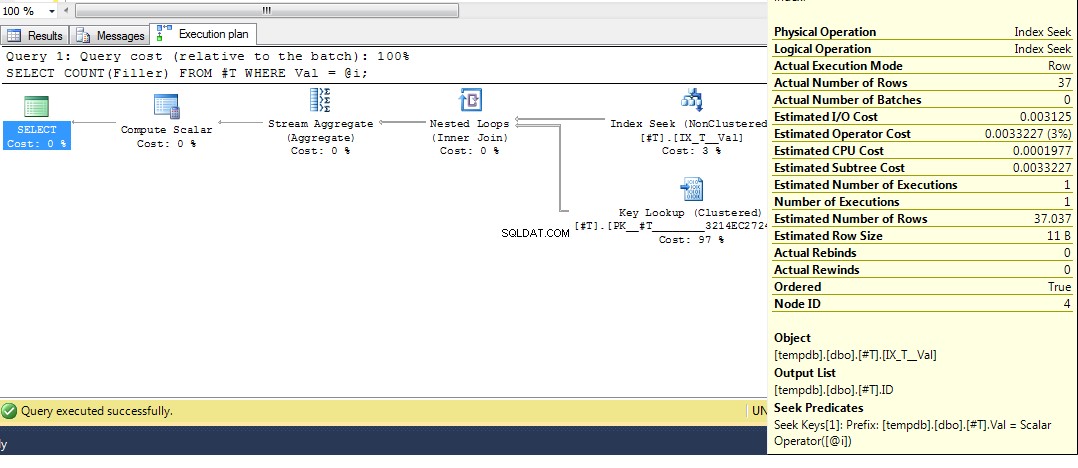
Entonces, con suerte, eso cubre de manera bastante completa por qué obtiene ese plan. Ahora supongo que la siguiente pregunta es cómo forzar un plan diferente, y la respuesta es usar la sugerencia de consulta OPTION (RECOMPILE) , para forzar la compilación de la consulta en tiempo de ejecución cuando se conoce el valor del parámetro. Volviendo a los datos originales, donde el mejor plan para Val = 2 es una búsqueda, pero el uso de una variable produce un plan con un escaneo de índice, podemos ejecutar:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
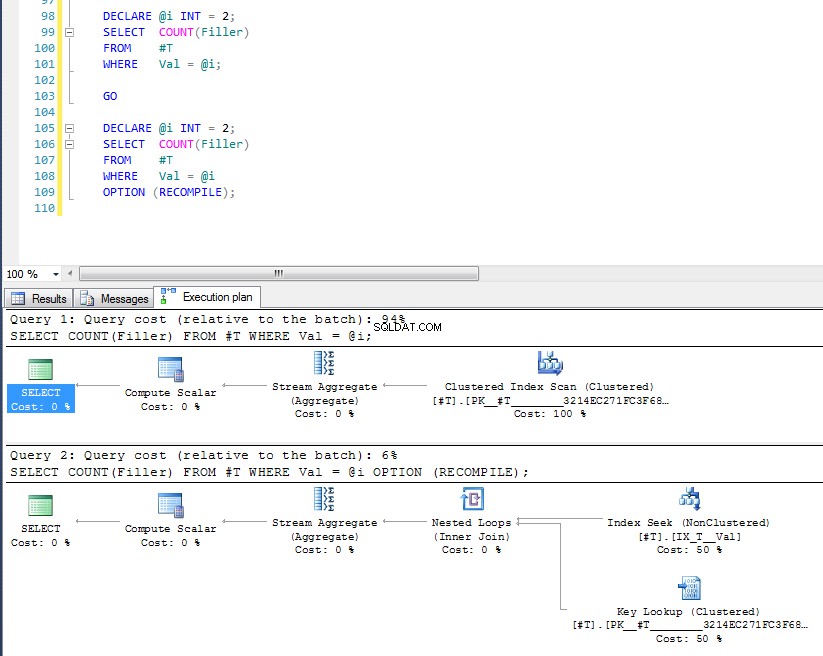
Podemos ver que este último utiliza la búsqueda de índice y la búsqueda de clave porque ha verificado el valor de la variable en el momento de la ejecución, y se elige el plan más apropiado para ese valor específico. El problema con OPTION (RECOMPILE) es que eso significa que no puede aprovechar los planes de consulta en caché, por lo que hay un costo adicional de compilar la consulta cada vez.