¿Qué hace que la consulta de aplicación cruzada tenga un rendimiento tan bajo en este documento XML simple y un rendimiento exponencialmente más lento a medida que crece el conjunto de datos?
Es el uso del eje principal para obtener el ID de atributo del nodo del elemento.
Es esta parte del plan de consulta la que es problemática.

Observe las 423 filas que salen de la función con valores de tabla inferior.
Agregar solo un nodo de elemento más con tres nodos de campo le da esto.
732 filas devueltas.
¿Qué sucede si duplicamos los nodos de la primera consulta a un total de 6 nodos de elementos?
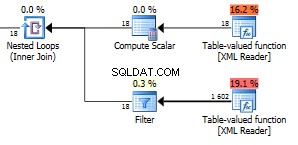
Hemos devuelto la friolera de 1602 filas.
La figura 18 en la función superior son todos los nodos de campo en su XML. Tenemos aquí 6 artículos con tres campos en cada artículo. Esos 18 nodos se usan en una unión de bucles anidados contra la otra función, por lo que 18 ejecuciones que devuelven 1602 filas dan como resultado 89 filas por iteración. Resulta que ese es el número exacto de nodos en todo el XML. Bueno, en realidad es uno más que todos los nodos visibles. no sé por qué Puede utilizar esta consulta para verificar el número total de nodos en su XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Entonces, el algoritmo utilizado por SQL Server para obtener el valor cuando usa el eje principal .. en una función de valores es que primero encuentra todos los nodos en los que está triturando, 18 en el último caso. Para cada uno de esos nodos, tritura y devuelve el documento XML completo y verifica en el operador de filtro el nodo que realmente desea. Ahí tiene su crecimiento exponencial. En lugar de usar el eje principal, debe usar una aplicación cruzada adicional. Primero triture en el artículo y luego en el campo.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
También cambié la forma de acceder al valor de texto del campo. Usando . hará que SQL Server busque nodos secundarios en field y concatenar esos valores en el resultado. No tiene valores secundarios, por lo que el resultado es el mismo, pero es bueno evitar tener esa parte en el plan de consulta (el operador UDX).
El plan de consulta no tiene el problema con el eje principal si está utilizando un índice XML, pero aún se beneficiará al cambiar la forma en que obtiene el valor del campo.



