¿Utiliza subconsultas SQL o evita usarlas?
Supongamos que el director de créditos y cobros le pide que enumere los nombres de las personas, sus saldos impagos por mes y el saldo actual y quiere que importe esta matriz de datos a Excel. El propósito es analizar los datos y presentar una oferta que aligere los pagos para mitigar los efectos de la pandemia de COVID19.
¿Opta por usar una consulta y una subconsulta anidada o una combinación? ¿Qué decisión tomarás?
Subconsultas SQL:¿Qué son?
Antes de profundizar en la sintaxis, el impacto en el rendimiento y las advertencias, ¿por qué no definir primero una subconsulta?
En los términos más simples, una subconsulta es una consulta dentro de una consulta. Mientras que una consulta que incorpora una subconsulta es la consulta externa, nos referimos a una subconsulta como consulta interna o selección interna. Y los paréntesis encierran una subconsulta similar a la estructura siguiente:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)Vamos a ver los siguientes puntos en esta publicación:
- Sintaxis de subconsultas SQL según diferentes tipos de subconsultas y operadores.
- Cuándo y en qué tipo de declaraciones se puede usar una subconsulta.
- Implicaciones de rendimiento frente a JOINs .
- Advertencias comunes al usar subconsultas SQL.
Como es costumbre, proporcionamos ejemplos e ilustraciones para mejorar la comprensión. Pero tenga en cuenta que el enfoque principal de esta publicación son las subconsultas en SQL Server.
Ahora, comencemos.
Hacer subconsultas SQL que sean independientes o correlacionadas
Por un lado, las subconsultas se clasifican en función de su dependencia de la consulta externa.
Permítanme describir qué es una subconsulta independiente.
Las subconsultas independientes (o, a veces, denominadas subconsultas simples o no correlacionadas) son independientes de las tablas de la consulta externa. Permítanme ilustrar esto:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Como se demuestra en el código anterior, la subconsulta (entre paréntesis a continuación) no tiene referencias a ninguna columna en la consulta externa. Además, puede resaltar la subconsulta en SQL Server Management Studio y ejecutarla sin obtener ningún error de tiempo de ejecución.
Lo que, a su vez, facilita la depuración de subconsultas independientes.
Lo siguiente a considerar son las subconsultas correlacionadas. En comparación con su contraparte independiente, esta tiene al menos una columna a la que se hace referencia desde la consulta externa. Para aclarar, daré un ejemplo:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)¿Estuvo lo suficientemente atento como para notar la referencia a BusinessEntityID? de la Persona ¿mesa? ¡Bien hecho!
Una vez que se hace referencia a una columna de la consulta externa en la subconsulta, se convierte en una subconsulta correlacionada. Un punto más a considerar:si resalta una subconsulta y la ejecuta, se producirá un error.
Y sí, tiene toda la razón:esto hace que las subconsultas correlacionadas sean bastante más difíciles de depurar.
Para hacer posible la depuración, siga estos pasos:
- aislar la subconsulta.
- reemplace la referencia a la consulta externa con un valor constante.
Aislar la subconsulta para la depuración hará que se vea así:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Ahora, profundicemos un poco más en el resultado de las subconsultas.
Hacer subconsultas SQL con 3 posibles valores devueltos
Bueno, primero, pensemos qué valores devueltos podemos esperar de las subconsultas SQL.
De hecho, hay 3 resultados posibles:
- Un solo valor
- Valores múltiples
- Mesas completas
Valor único
Comencemos con la salida de un solo valor. Este tipo de subconsulta puede aparecer en cualquier parte de la consulta externa donde se espera una expresión, como DÓNDE cláusula.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Cuando usas un MAX (), recupera un solo valor. Eso es exactamente lo que sucedió con nuestra subconsulta anterior. Usando el igual (= ) le dice a SQL Server que espera un valor único. Otra cosa:si la subconsulta devuelve múltiples valores usando los iguales (= ), obtendrá un error, similar al siguiente:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Valores múltiples
A continuación, examinamos la salida de valores múltiples. Este tipo de subconsulta devuelve una lista de valores con una sola columna. Además, operadores como IN y NO EN esperará uno o más valores.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Valores de tabla completa
Y por último, pero no menos importante, ¿por qué no profundizar en los resultados de toda la tabla?
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]¿Has notado el DE cláusula?
En lugar de usar una tabla, usó una subconsulta. Esto se denomina tabla derivada o subconsulta de tabla.
Y ahora, déjame presentarte algunas reglas básicas al usar este tipo de consulta:
- Todas las columnas de la subconsulta deben tener nombres únicos. Al igual que una tabla física, una tabla derivada debe tener nombres de columna únicos.
- ORDENAR POR no está permitido a menos que ARRIBA también se especifica. Eso es porque la tabla derivada representa una tabla relacional donde las filas no tienen un orden definido.
En este caso, una tabla derivada tiene los beneficios de una tabla física. Por eso, en nuestro ejemplo, podemos usar COUNT () en una de las columnas de la tabla derivada.
Eso es todo lo relacionado con las salidas de subconsultas. Pero antes de continuar, es posible que haya notado que la lógica detrás del ejemplo para valores múltiples y otros también se puede hacer usando JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'De hecho, la salida será la misma. Pero, ¿cuál funciona mejor?
Antes de entrar en eso, déjame decirte que he dedicado una sección a este tema candente. Lo examinaremos con planes de ejecución completos y echaremos un vistazo a las ilustraciones.
Así que tengan paciencia conmigo por un momento. Analicemos otra forma de colocar sus subconsultas.
Otras declaraciones en las que puede usar subconsultas SQL
Hasta ahora, hemos estado usando subconsultas SQL en SELECT declaraciones. Y es que puedes disfrutar de los beneficios de las subconsultas en INSERT , ACTUALIZAR y ELIMINAR sentencias o en cualquier sentencia T-SQL que forme una expresión.
Entonces, echemos un vistazo a una serie de algunos ejemplos más.
Uso de subconsultas SQL en instrucciones UPDATE
Es lo suficientemente simple como para incluir subconsultas en ACTUALIZAR declaraciones. ¿Por qué no echas un vistazo a este ejemplo?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GO¿Te diste cuenta de lo que hicimos allí?
La cosa es que puedes poner subconsultas en el DÓNDE cláusula de una ACTUALIZACIÓN declaración.
Como no lo tenemos en el ejemplo, también puede usar una subconsulta para SET cláusula como SET columna =(subconsulta) . Pero tenga cuidado:debe generar un solo valor porque, de lo contrario, se produce un error.
¿Qué hacemos ahora?
Uso de subconsultas SQL en declaraciones INSERT
Como ya sabe, puede insertar registros en una tabla usando un SELECCIONAR declaración. Estoy seguro de que tiene una idea de cuál será la estructura de la subconsulta, pero demostremos esto con un ejemplo:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Entonces, ¿qué estamos viendo aquí?
- La primera subconsulta recupera la última tasa de salario de un empleado antes de agregar los 10 adicionales.
- La segunda subconsulta obtiene el último registro de salario del empleado.
- Por último, el resultado de SELECT se inserta en el EmployeePayHistory mesa.
En otras declaraciones T-SQL
Además de SELECCIONAR , INSERTAR , ACTUALIZAR y ELIMINAR , también puede usar subconsultas SQL en lo siguiente:
Declaraciones de variables o instrucciones SET en funciones y procedimientos almacenados
Permítanme aclarar usando este ejemplo:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Alternativamente, puede hacerlo de la siguiente manera:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)En expresiones condicionales
¿Por qué no le echas un vistazo a este ejemplo?
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDAparte de eso, podemos hacerlo así:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDRealizar Subconsultas SQL con Comparación u Operadores Lógicos
Hasta ahora, hemos visto los iguales (= ) y el operador IN. Pero hay mucho más por explorar.
Uso de operadores de comparación
Cuando se usa un operador de comparación como =, <,>, <>,>=o <=con una subconsulta, la subconsulta debe devolver un único valor. Además, se produce un error si la subconsulta devuelve varios valores.
El siguiente ejemplo generará un error de tiempo de ejecución.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)¿Sabes qué está mal en el código anterior?
En primer lugar, el código usa el operador igual (=) con la subconsulta. Además, la subconsulta devuelve una lista de fechas de inicio.
Para solucionar el problema, haga que la subconsulta use una función como MAX () en la columna de fecha de inicio para devolver un solo valor.
Uso de operadores lógicos
Usando EXISTE o NO EXISTE
EXISTE devuelve VERDADERO si la subconsulta devuelve alguna fila. De lo contrario, devuelve FALSO . Mientras tanto, usando NO EXISTE devolverá VERDADERO si no hay filas y FALSO , de lo contrario.
Considere el siguiente ejemplo:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDPrimero, permítanme explicar. El código anterior soltará el token de la tabla si se encuentra en sys.tables , es decir, si existe en la base de datos. Otro punto:la referencia al nombre de la columna es irrelevante.
¿Por qué es eso?
Resulta que el motor de la base de datos solo necesita obtener al menos 1 fila usando EXISTS . En nuestro ejemplo, si la subconsulta devuelve una fila, la tabla se eliminará. Por otro lado, si la subconsulta no devolvió una sola fila, las declaraciones posteriores no se ejecutarán.
Así, la preocupación de EXISTE son solo filas y no columnas.
Además, EXISTE utiliza una lógica de dos valores:VERDADERO o FALSO . No hay casos en los que devuelva NULL . Lo mismo sucede cuando niegas EXISTS usando NO .
Usando EN o NO EN
Una subconsulta introducida con IN o NO EN devolverá una lista de cero o más valores. Y a diferencia de EXISTE , se requiere una columna válida con el tipo de datos adecuado.
Permítanme aclarar esto con otro ejemplo:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Como puede ver en el código anterior, tanto IN y NO EN Se introducen los operadores. Y en ambos casos, se devolverán filas. Cada fila de la consulta externa se comparará con el resultado de cada subconsulta para obtener un producto disponible y un producto que no sea del proveedor 1676.
Anidamiento de Subconsultas SQL
Puede anidar subconsultas incluso hasta 32 niveles. No obstante, esta capacidad depende de la memoria disponible del servidor y de la complejidad de otras expresiones en la consulta.
¿Cuál es tu opinión sobre esto?
En mi experiencia, no recuerdo anidar hasta 4. Rara vez uso 2 o 3 niveles. Pero eso es solo yo y mis requisitos.
¿Qué tal un buen ejemplo para resolver esto:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Como podemos ver en este ejemplo, el anidamiento alcanzó 2 niveles.
¿Las subconsultas SQL son malas para el rendimiento?
En pocas palabras:sí y no. En otras palabras, depende.
Y no olvide, esto es en el contexto de SQL Server.
Para empezar, muchas declaraciones T-SQL que usan subconsultas se pueden reescribir alternativamente usando JOIN s. Y el rendimiento para ambos suele ser el mismo. A pesar de eso, hay casos particulares en los que una combinación es más rápida. Y hay casos en que la subconsulta funciona más rápido.
Ejemplo 1
Examinemos un ejemplo de subconsulta. Antes de ejecutarlos, presiona Control-M o habilite Incluir plan de ejecución real desde la barra de herramientas de SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternativamente, la consulta anterior se puede reescribir usando una combinación que produzca el mismo resultado.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Al final, el resultado de ambas consultas es de 200 filas.
Además de eso, puede consultar el plan de ejecución para ambas declaraciones.
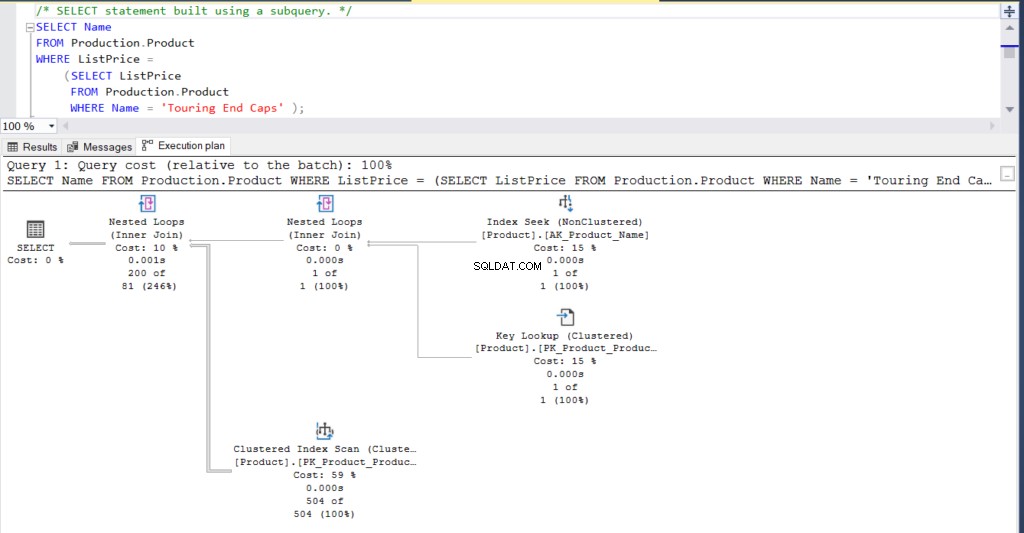
Figura 1:Plan de ejecución usando una subconsulta
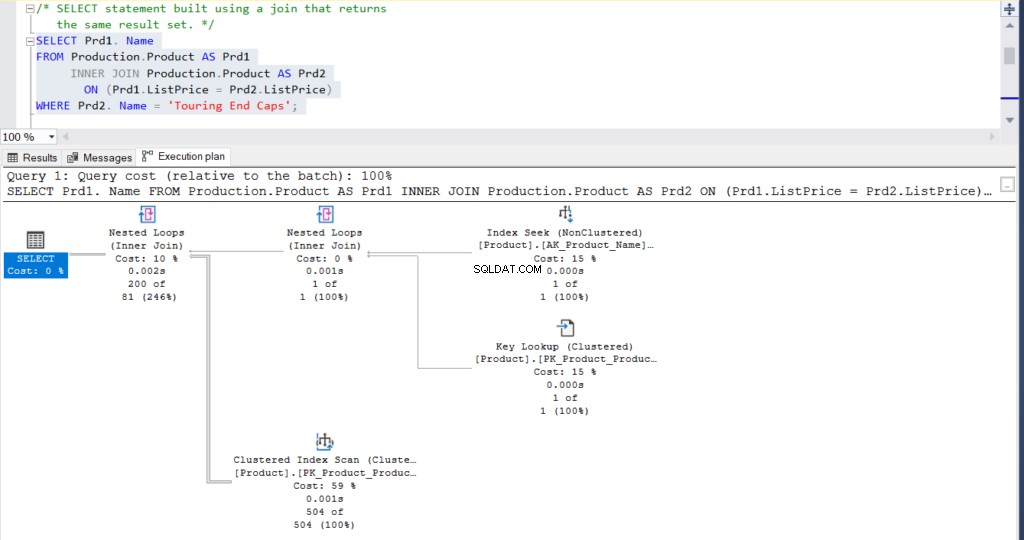
Figura 2:Plan de ejecución usando una combinación
¿Qué piensas? ¿Son prácticamente iguales? Excepto por el tiempo real transcurrido de cada nodo, todo lo demás es básicamente igual.
Pero aquí hay otra forma de compararlo además de las diferencias visuales. Sugiero usar el Comparar Showplan .
Para realizarlo, sigue estos pasos:
- Haga clic con el botón derecho en el plan de ejecución de la declaración utilizando la subconsulta.
- Seleccione Guardar plan de ejecución como .
- Nombre el archivo subquery-execution-plan.sqlplan .
- Vaya al plan de ejecución de la instrucción usando una combinación y haga clic con el botón derecho.
- Seleccione Comparar plan de presentación .
- Seleccione el nombre de archivo que guardó en el #3.
Ahora, echa un vistazo a esto para obtener más información sobre Comparar Showplan .
Debería poder ver algo similar a esto:
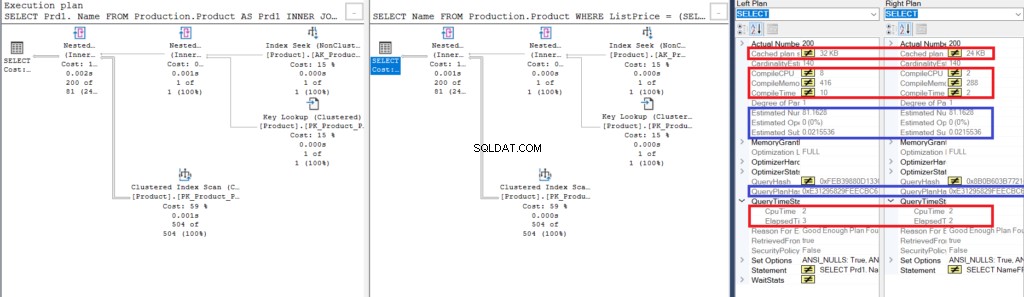
Figura 3:Compare Showplan para usar una unión versus usar una subconsulta
Note las similitudes:
- Las filas y los costos estimados son los mismos.
- Hash del plan de consulta también es lo mismo, lo que significa que tienen planes de ejecución similares.
No obstante, fíjate en las diferencias:
- El tamaño del plan de caché es mayor usando la unión que usando la subconsulta
- La CPU y el tiempo de compilación (en ms), incluida la memoria en KB, utilizada para analizar, enlazar y optimizar el plan de ejecución es mayor usando la combinación que usando la subconsulta
- El tiempo de CPU y el tiempo transcurrido (en ms) para ejecutar el plan es ligeramente mayor usando la combinación que la subconsulta
En este ejemplo, la subconsulta es un tic más rápida que la unión, aunque las filas resultantes sean las mismas.
Ejemplo 2
En el ejemplo anterior, usamos solo una tabla. En el ejemplo que sigue, vamos a utilizar 3 tablas diferentes.
Hagamos que esto suceda:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Ambas consultas generan las mismas 3806 filas.
A continuación, echemos un vistazo a sus planes de ejecución:
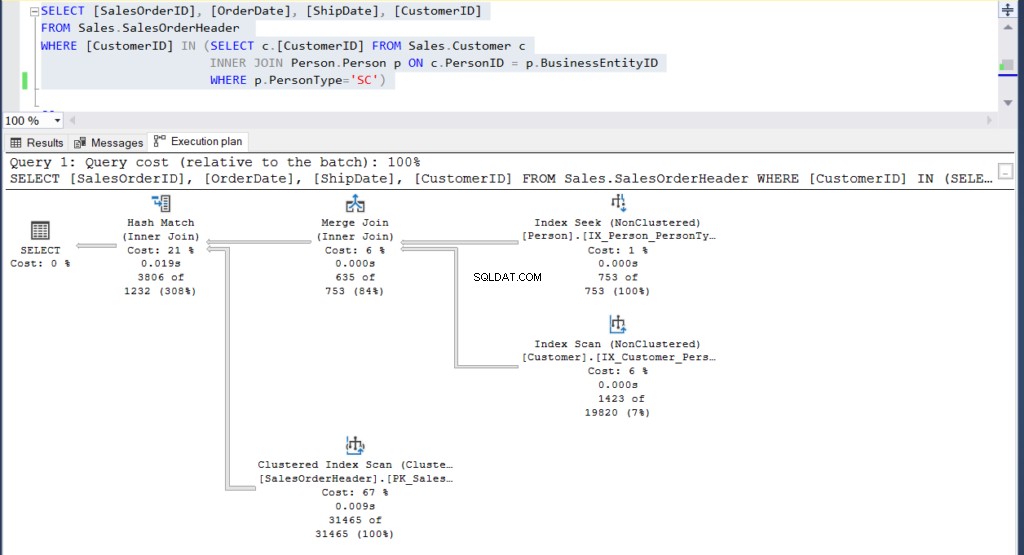
Figura 4:Plan de ejecución para nuestro segundo ejemplo utilizando una subconsulta
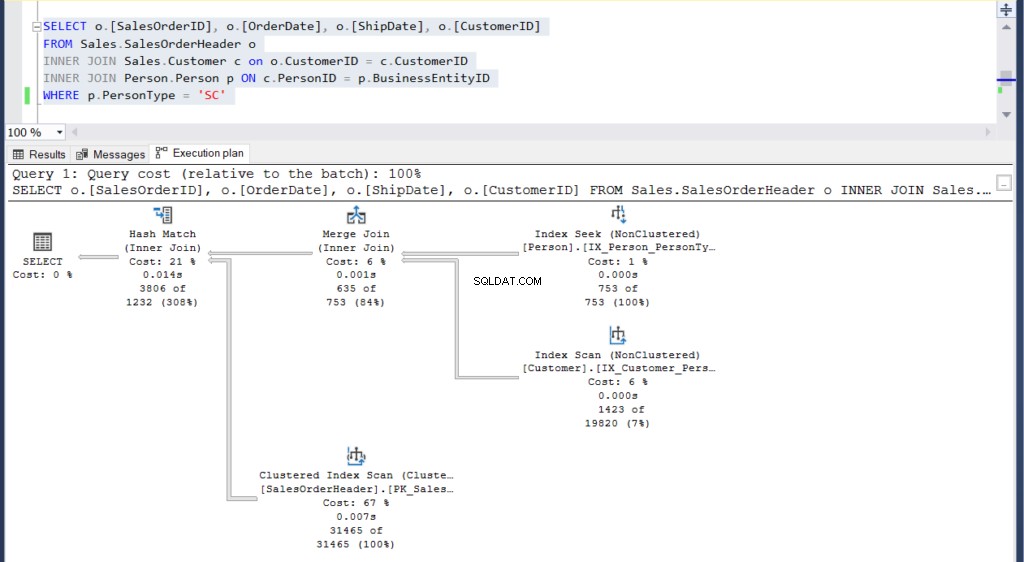
Figura 5:Plan de ejecución para nuestro segundo ejemplo usando una unión
¿Puedes ver los 2 planes de ejecución y encontrar alguna diferencia entre ellos? De un vistazo se ven iguales.
Pero un examen más cuidadoso con Compare Showplan revela lo que realmente hay dentro.
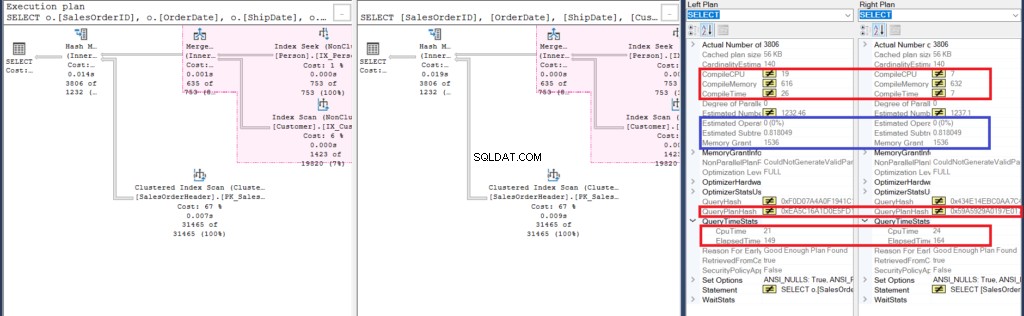
Figura 6:Detalles de Compare Showplan para el segundo ejemplo
Comencemos analizando algunas similitudes:
- El resaltado rosa en el plan de ejecución revela operaciones similares para ambas consultas. Dado que la consulta interna utiliza una unión en lugar de anidar subconsultas, esto es bastante comprensible.
- Los costos estimados del operador y del subárbol son los mismos.
A continuación, echemos un vistazo a las diferencias:
- Primero, la compilación tomó más tiempo cuando usamos uniones. Puede verificar eso en Compile CPU y Compile Time. Sin embargo, la consulta con una subconsulta tomó una memoria de compilación más alta en KB.
- Entonces, el QueryPlanHash de ambas consultas es diferente, lo que significa que tienen un plan de ejecución diferente.
- Por último, el tiempo transcurrido y el tiempo de CPU para ejecutar el plan son más rápidos usando la combinación que usar una subconsulta.
Conclusión sobre el rendimiento de la subconsulta frente a la combinación
Es probable que se enfrente a muchos otros problemas relacionados con las consultas que se pueden resolver mediante una combinación o una subconsulta.
Pero la conclusión es que una subconsulta no es inherentemente mala en comparación con las uniones. Y no existe una regla general que indique que, en una situación particular, una combinación es mejor que una subconsulta o viceversa.
Entonces, para asegurarse de que tiene la mejor opción, verifique los planes de ejecución. El propósito de eso es obtener información sobre cómo SQL Server procesará una consulta en particular.
Sin embargo, si elige utilizar una subconsulta, tenga en cuenta que pueden surgir problemas que pondrán a prueba su habilidad.
Advertencias comunes al usar subconsultas SQL
Hay 2 problemas comunes que pueden hacer que sus consultas se comporten de manera descontrolada cuando se usan subconsultas SQL.
El dolor de la resolución de nombres de columnas
Este problema introduce errores lógicos en sus consultas y pueden ser muy difíciles de encontrar. Un ejemplo puede aclarar aún más este problema.
Comencemos por crear una tabla con fines de demostración y llenarla con datos.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GOAhora que la tabla está configurada, activemos algunas subconsultas usándola. Pero antes de ejecutar la consulta a continuación, recuerde que los ID de proveedor que usamos del código anterior comienzan con '14'.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)El código anterior se ejecuta sin errores, como puede ver a continuación. De todos modos, preste atención a la lista de BusinessEntityIDs .
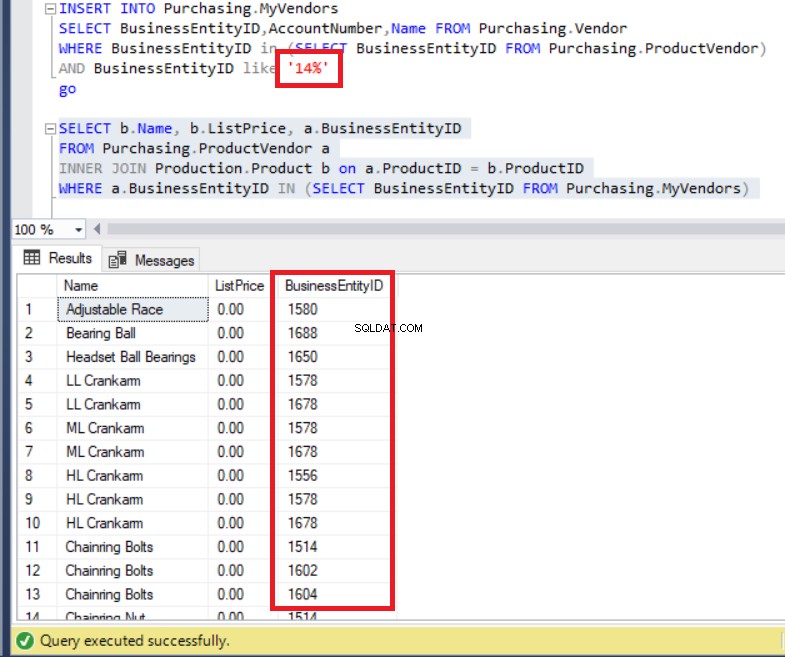
Figura 7:Los BusinessEntityIDs del conjunto de resultados son inconsistentes con los registros de la tabla MyVendors
¿No insertamos datos con BusinessEntityID? comenzando con '14'? Entonces, ¿cuál es el problema? De hecho, podemos ver BusinessEntityIDs que comienzan con '15' y '16'. ¿De dónde vienen estos?
En realidad, la consulta enumeró todos los datos de ProductVendor mesa.
En ese caso, puede pensar que un alias resolverá este problema para que se refiera a MyVendors tabla como la siguiente:
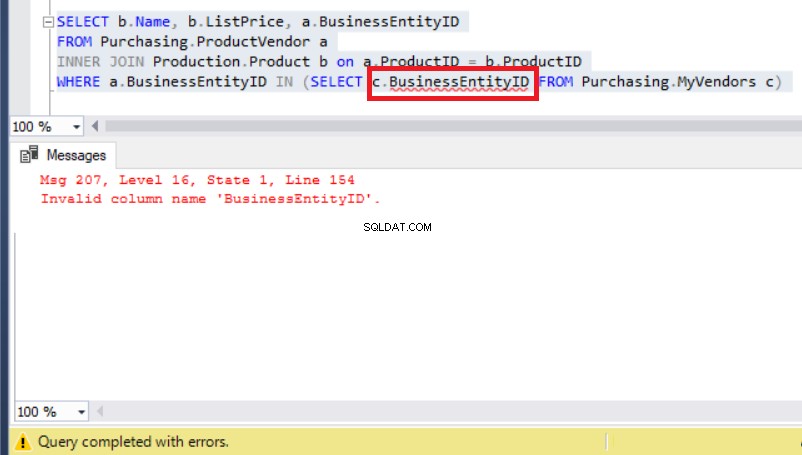
Figura 8:Agregar un alias a BusinessEntityID da como resultado un error
Excepto que ahora el problema real apareció debido a un error de tiempo de ejecución.
Consulte Mis proveedores tabla de nuevo y verá que en lugar de BusinessEntityID , el nombre de la columna debe ser BusinessEntity_id (con un guión bajo).
Por lo tanto, usar el nombre de columna correcto finalmente solucionará este problema, como puede ver a continuación:
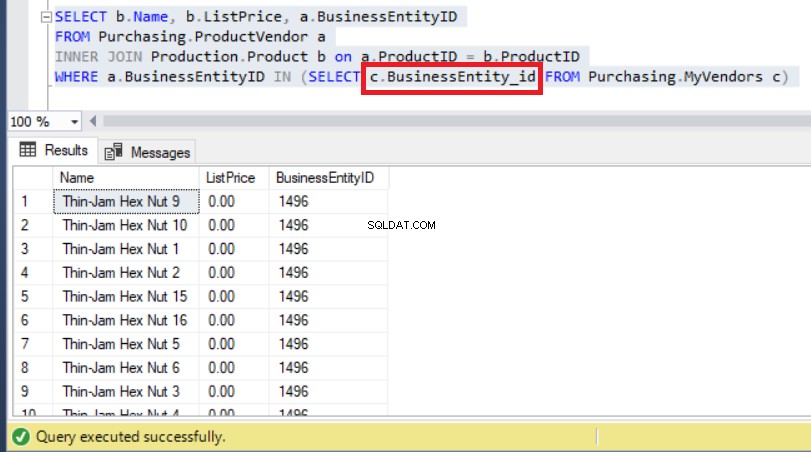
Figura 9:cambiar la subconsulta con el nombre de columna correcto resolvió el problema
Como puede ver arriba, ahora podemos observar BusinessEntityIDs comenzando con '14' tal como esperábamos anteriormente.
Pero puede preguntarse: ¿por qué diablos SQL Server permitió ejecutar la consulta con éxito en primer lugar?
Aquí está el truco:la resolución de los nombres de columna sin alias funciona en el contexto de la subconsulta desde que en sí misma sale a la consulta externa. Por eso la referencia a BusinessEntityID dentro de la subconsulta no provocó un error porque se encuentra fuera de la subconsulta, en el ProductVendor mesa.
En otras palabras, SQL Server busca la columna sin alias BusinessEntityID en Mis proveedores mesa. Como no está, miró afuera y lo encontró en el ProductVendor mesa. Loco, ¿no?
Se podría decir que es un error en SQL Server, pero, en realidad, es por diseño en el estándar SQL y Microsoft lo siguió.
Está bien, está claro, no podemos hacer nada con respecto al estándar, pero ¿cómo podemos evitar encontrarnos con un error?
- Primero, prefije los nombres de las columnas con el nombre de la tabla o use un alias. En otras palabras, evite nombres de tablas sin prefijo o sin alias.
- Segundo, tenga una nomenclatura coherente de las columnas. Evite tener ambos BusinessEntityID y BusinessEntity_id , por ejemplo.
¿Suena bien? Sí, esto aporta algo de cordura a la situación.
Pero este no es el final.
NULL locos
Como mencioné, hay más para cubrir. T-SQL usa una lógica de 3 valores debido a su compatibilidad con NULL . Y NULO casi puede volvernos locos cuando usamos subconsultas SQL con NOT IN .
Permítanme comenzar presentando este ejemplo:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)El resultado de la consulta nos lleva a una lista de productos que no están en MyVendors table., como se ve a continuación:
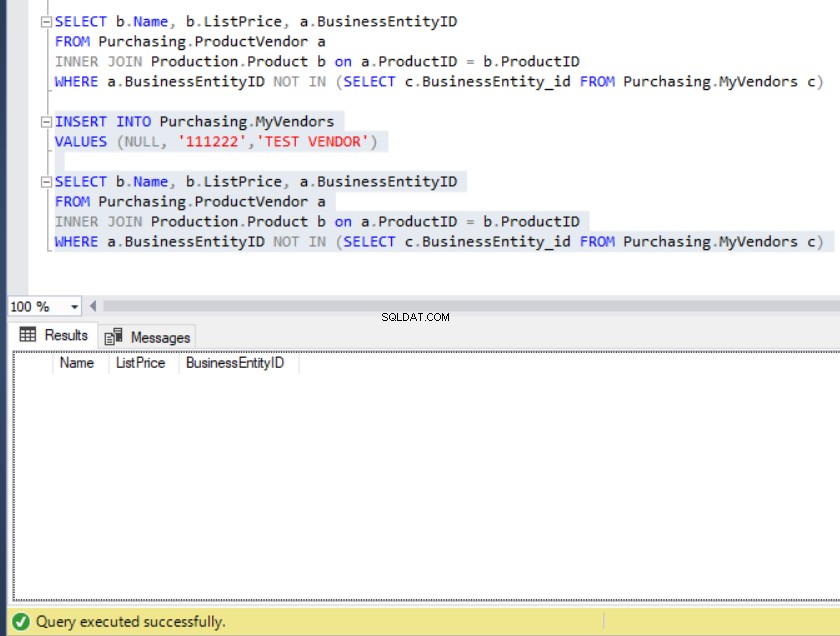
Figura 10:El resultado de la consulta de muestra usando NOT IN
Ahora, suponga que alguien insertó involuntariamente un registro en MyVendors tabla con un NULL NegocioEntidad_id . ¿Qué vamos a hacer al respecto?
Figura 11:el conjunto de resultados se vacía cuando se inserta un NULL BusinessEntity_id en MyVendors
¿Adónde fueron todos los datos?
Verás, el NO el operador negó el IN predicado. Entonces, NO ES CIERTO ahora se convertirá en FALSO . Pero NO NULO es desconocido. Eso hizo que el filtro descartara las filas que son DESCONOCIDAS, y este es el culpable.
Para asegurarse de que esto no le suceda a usted:
- Haga que la columna de la tabla no permita NULLs si los datos no deberían ser así.
- O agregue column_name NO ES NULO a tu DÓNDE cláusula. En nuestro caso, la subconsulta es la siguiente:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Puntos para llevar
Hemos hablado mucho sobre las subconsultas y ha llegado el momento de proporcionar las principales conclusiones de esta publicación en forma de una lista resumida:
Una subconsulta:
- es una consulta dentro de una consulta.
- está entre paréntesis.
- puede sustituir una expresión en cualquier lugar.
- se puede usar en SELECT , INSERTAR , ACTUALIZAR , ELIMINAR, u otras declaraciones T-SQL.
- puede ser autónomo o correlacionado.
- produce valores únicos, múltiples o de tabla.
- funciona con operadores de comparación como =, <>,>, <,>=, <=y operadores lógicos como IN /NO EN y EXISTE /NO EXISTE .
- no es malo ni perverso. Puede funcionar mejor o peor que JOIN s dependiendo de una situación. Así que sigue mi consejo y siempre revisa los planes de ejecución.
- puede tener un comportamiento desagradable en NULL s cuando se usa con NOT IN y cuando una columna no se identifica explícitamente con una tabla o un alias de tabla.
Familiarícese con varias referencias adicionales para su placer de lectura:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators