En este artículo, discutiremos los errores típicos que pueden enfrentar los desarrolladores novatos al diseñar el código T-SQL. Además, veremos las mejores prácticas y algunos consejos útiles que pueden ayudarlo cuando trabaje con SQL Server, así como soluciones alternativas para mejorar el rendimiento.
Contenido:
1. Tipos de datos
2. *
3. Alias
4. Orden de las columnas
5. NO EN VS NULO
6. Formato de fecha
7. Filtro de fecha
8. Cálculo
9. Convertir implícito
10. LIKE &Índice suprimido
11. Unicode frente a ANSI
12. COLABORAR
13. COLABORACIÓN BINARIA
14. Estilo de código
15. [var]char
16. Longitud de datos
17. ISNULL vs COALESCE
18. Matemáticas
19. UNIÓN vs UNIÓN TODOS
20. Vuelve a leer
21. Subconsulta
22. CASO CUANDO
23. Función escalar
24. VISTAS
25. CURSORES
26. STRING_CONCAT
27. Inyección SQL
Tipos de datos
El principal problema al que nos enfrentamos cuando trabajamos con SQL Server es una elección incorrecta de los tipos de datos.
Supongamos que tenemos dos tablas idénticas:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')
DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01') Ejecutemos una consulta para comprobar cuál es la diferencia:
DECLARE @BirthDate DATE = '2012-09-01' SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
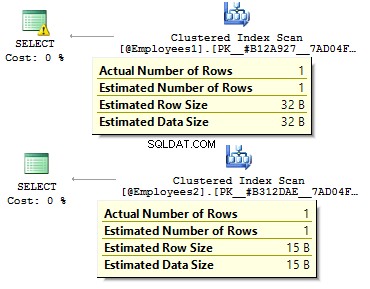
En el primer caso, los tipos de datos son más redundantes de lo que podrían ser. ¿Por qué deberíamos almacenar un valor de bit como SÍ/NO? ¿hilera? ¿Por qué debemos almacenar una fecha como una fila? ¿Por qué deberíamos usar BIGINT ? para empleados en la tabla, en lugar de INT ?
Conduce a los siguientes inconvenientes:
- Las tablas pueden ocupar mucho espacio en el disco;
- Necesitamos leer más páginas y poner más datos en BufferPool para manejar datos.
- Bajo rendimiento.
*
Me he enfrentado a una situación en la que los desarrolladores recuperan todos los datos de una tabla y luego, en el lado del cliente, usan DataReader para seleccionar solo los campos obligatorios. No recomiendo usar este enfoque:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFF Habrá una diferencia significativa en el tiempo de ejecución de la consulta. Además, el índice de cobertura puede reducir una cantidad de lecturas lógicas.
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ... SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1235 ms. Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 227 ms.
Alias
Vamos a crear una tabla:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD') Supongamos que tenemos una consulta que devuelve la cantidad de filas idénticas en ambas tablas:
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
) Todo funcionará como se esperaba, hasta que alguien cambie el nombre de una columna en Sales.UserCurrency tabla:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
A continuación, ejecutaremos una consulta y veremos que obtenemos todas las filas en Sales.Currency tabla, en lugar de 1 fila. Al crear un plan de ejecución, en la etapa de vinculación, SQL Server verificaría las columnas de Sales.UserCurrency, no encontrará CurrencyCode allí y decide que esta columna pertenece a Sales.Currency mesa. Después de eso, un optimizador eliminará el CurrencyCode =CurrencyCode condición.
Por lo tanto, recomiendo usar alias:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
) Orden de las columnas
Supongamos que tenemos una tabla:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
) Siempre insertamos datos allí según la información sobre el orden de las columnas.
INSERT INTO dbo.DatePeriod SELECT '2015-01-01', '2015-01-31'
Supongamos que alguien cambia el orden de las columnas:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
) Los datos se insertarán en un orden diferente. En este caso, es una buena idea especificar explícitamente las columnas en la instrucción INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate) SELECT '2015-01-01', '2015-01-31'
Aquí hay otro ejemplo:
SELECT TOP(1) * FROM dbo.DatePeriod ORDER BY 2 DESC
¿Sobre qué columna vamos a ordenar los datos? Dependerá del orden de las columnas en una tabla. En caso de que uno cambie el orden, obtendremos resultados incorrectos.
NO DENTRO vs NULO
Hablemos del NO EN declaración.
Por ejemplo, debe escribir un par de consultas:devolver los registros de la primera tabla, que no existen en la segunda tabla y viceversa. Por lo general, los desarrolladores junior usan IN y NO EN :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE t1 NOT IN (SELECT t2 FROM @t2) SELECT * FROM @t1 WHERE t1 IN (SELECT t2 FROM @t2)
La primera consulta devolvió 2, la segunda, 1. Además, agregaremos otro valor en la segunda tabla:NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Al ejecutar la consulta con NOT IN , no obtendremos ningún resultado. ¿Por qué IN funciona y NO IN no? La razón es que SQL Server usa TRUE , FALSO y DESCONOCIDO lógica al comparar datos.
Al ejecutar una consulta, SQL Server interpreta la condición IN de la siguiente manera:
a IN (1, NULL) == a=1 OR a=NULL
NO EN :
a NOT IN (1, NULL) == a<>1 AND a<>NULL
Al comparar cualquier valor con NULL, SQL Server devuelve DESCONOCIDO. Cualquiera 1=NULO o NULL=NULL – ambos resultan en DESCONOCIDO. Si tenemos AND en la expresión, ambos lados devuelven UNKNOWN.
Me gustaría señalar que este caso no es raro. Por ejemplo, marca una columna como NO NULO. Después de un tiempo, otro desarrollador decide permitir NULL para esa columna Esto puede conducir a la situación, cuando un informe de cliente deja de funcionar una vez que se inserta cualquier valor NULL en la tabla.
En este caso, recomendaría excluir valores NULL:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
) Además, es posible utilizar EXCEPTO :
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
Alternativamente, puede usar NO EXISTS :
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
) ¿Qué opción es más preferible? La última opción con NO EXISTE parece ser el más productivo, ya que genera el desplazamiento de predicado más óptimo operador para acceder a los datos de la segunda tabla.
En realidad, los valores NULL pueden devolver un resultado inesperado.
Considérelo en este ejemplo particular:
USE AdventureWorks2014 GO SELECT COUNT_BIG(*) FROM Production.Product SELECT COUNT_BIG(*) FROM Production.Product WHERE Color = 'Grey' SELECT COUNT_BIG(*) FROM Production.Product WHERE Color <> 'Grey'
Como puede ver, no obtuvo el resultado esperado porque los valores NULL tienen operadores de comparación separados:
SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NULL SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NOT NULL
Aquí hay otro ejemplo con CHECK restricciones:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
) Creamos una tabla con permiso para insertar solo colores blanco y negro:
INSERT INTO #temp VALUES ('Black')
(1 row(s) affected) Todo funciona como se esperaba.
INSERT INTO #temp VALUES ('Red')
The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated. Ahora, agreguemos NULL:
INSERT INTO #temp VALUES (NULL) (1 row(s) affected)
¿Por qué la restricción CHECK pasó el valor NULL? Bueno, la razón es que hay bastantes NO FALSO condición para hacer un registro. La solución consiste en definir explícitamente una columna como NOT NULL o use NULL en la restricción.
Formato de fecha
Muy a menudo, puede tener dificultades con los tipos de datos.
Por ejemplo, necesita obtener la fecha actual. Para hacer esto, puede usar la función GETDATE:
SELECT GETDATE()
Luego simplemente copie el resultado devuelto en una consulta requerida y elimine la hora:
SELECT * FROM sys.objects WHERE create_date < '2016-11-14'
¿Es eso correcto?
La fecha se especifica mediante una constante de cadena:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 Todos los valores tienen una interpretación de un solo valor:
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
No causará ningún problema hasta que la consulta con esta lógica empresarial se ejecute en otro servidor donde la configuración puede diferir:
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 Sin embargo, estas opciones pueden dar lugar a una interpretación incorrecta de la fecha:
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
Además, este código puede generar un error tanto visible como latente.
Considere el siguiente ejemplo. Necesitamos insertar datos en una tabla de prueba. En un servidor de prueba todo funciona perfecto:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016') Aún así, en el lado del cliente, esta consulta tendrá problemas ya que la configuración de nuestro servidor es diferente:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
Entonces, ¿qué formato debemos usar para declarar constantes de fecha? Para responder a esta pregunta, ejecute esta consulta:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
La interpretación de las constantes puede diferir según el idioma instalado:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12 Por lo tanto, es mejor usar las dos últimas opciones. Además, me gustaría agregar que especificar explícitamente la fecha no es una buena idea:
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016' Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Por lo tanto, si desea que las constantes con las fechas se interpreten correctamente, debe especificarlas en el siguiente formato YYYYMMDD.
Además, me gustaría llamar su atención sobre el comportamiento de algunos tipos de datos:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2 A diferencia de DATETIME, DATE type se interpreta correctamente con varias configuraciones en un servidor:
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
Filtro de fecha
Para continuar, consideraremos cómo filtrar datos de manera efectiva. Empecemos por ellos DATETIME/DATE:
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
Ahora, intentaremos averiguar cuántas filas devuelve la consulta para un día específico:
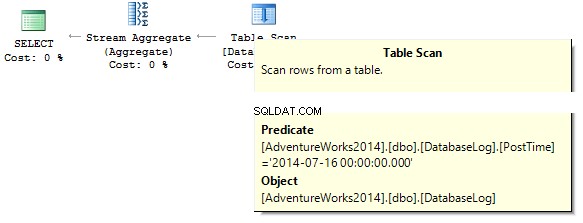
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
La consulta devolverá 0. Al crear un plan de ejecución, el servidor SQL intenta convertir una constante de cadena al tipo de datos de la columna que necesitamos filtrar:
Crear un índice:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
Hay opciones correctas e incorrectas para generar datos. Por ejemplo, debe eliminar la columna de tiempo:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
O necesitamos especificar un rango:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140716' AND PostTime < '20140717'
Teniendo en cuenta la optimización, puedo decir que estas dos consultas son las más correctas. El punto es que todas las conversiones y los cálculos de las columnas de índice que se filtran pueden disminuir el rendimiento drásticamente y aumentar el tiempo de las lecturas lógicas:
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 2, ...
La hora de la publicación El campo no se había incluido en el índice antes, y no pudimos ver ninguna eficiencia en el uso de este enfoque correcto en el filtrado. Otra cosa es cuando necesitamos generar datos para un mes:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801' Una vez más, la última opción es más preferible:
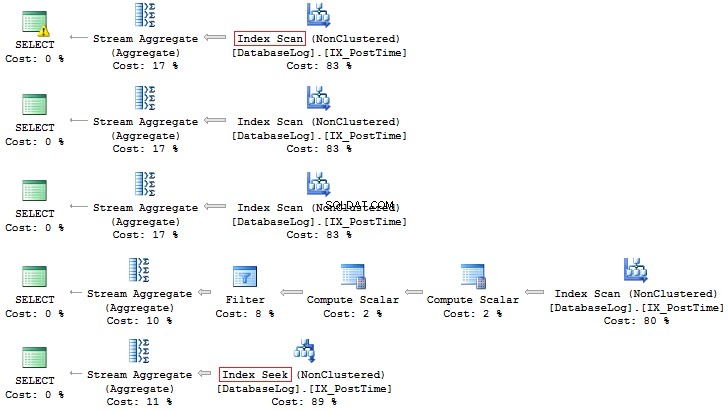
Además, siempre puede crear un índice basado en un campo calculado:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) En comparación con la consulta anterior, la diferencia en las lecturas lógicas puede ser significativa (si se trata de tablas grandes):
SET STATISTICS IO ON SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731' SET STATISTICS IO OFF Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 3, ...
Cálculo
Como ya se ha discutido, cualquier cálculo en las columnas de índice disminuye el rendimiento y aumenta el tiempo de las lecturas lógicas:
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 2500 * 2 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 5000 Table 'Person'. Scan count 1, logical reads 67, ... Table 'Person'. Scan count 0, logical reads 3, ...
Si observamos los planes de ejecución, en el primero, SQL Server ejecuta IndexScan :
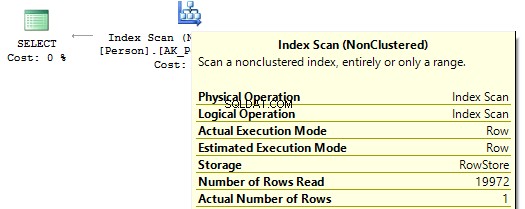
Luego, cuando no haya cálculos en las columnas de índice, veremos IndexSeek :

Convertir implícito
Echemos un vistazo a estas dos consultas que filtran por el mismo valor:
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
Los planes de ejecución proporcionan la siguiente información:
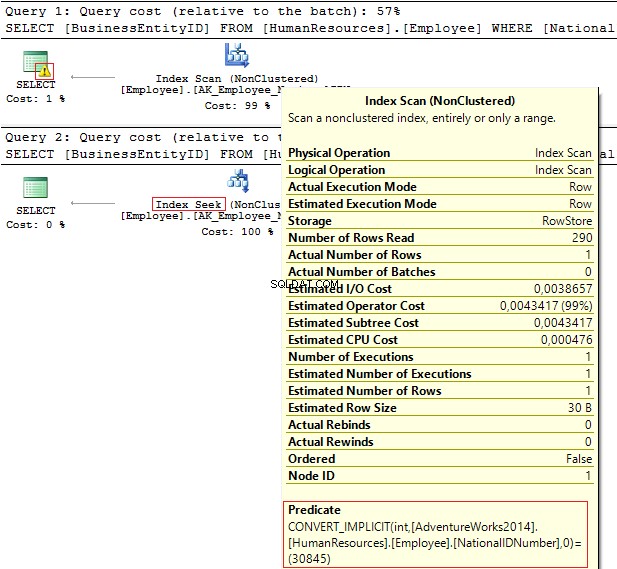
- Advertencia y IndexScan en el primer plan
- Buscar índices: en el segundo.
Table 'Employee'. Scan count 1, logical reads 4, ... Table 'Employee'. Scan count 0, logical reads 2, ...
El número de identificación nacional columna tiene el NVARCHAR(15) tipo de datos. La constante que usamos para filtrar datos se establece como INT lo que nos lleva a una conversión de tipo de datos implícita. A su vez, puede disminuir el rendimiento. Puede monitorearlo cuando alguien modifica el tipo de datos en la columna, sin embargo, las consultas no se modifican.
Es importante comprender que una conversión de tipo de datos implícita puede generar errores en tiempo de ejecución. Por ejemplo, antes de que el campo PostalCode fuera numérico, resultó que un código postal podía contener letras. Por lo tanto, se actualizó el tipo de datos. Aún así, si insertamos un código postal alfabético, la consulta anterior ya no funcionará:
SELECT AddressID FROM Person.[Address] WHERE PostalCode = 92700 SELECT AddressID FROM Person.[Address] WHERE PostalCode = '92700' Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
Otro ejemplo es cuando necesita usar EntityFramework en el proyecto, que por defecto interpreta todos los campos de fila como Unicode:
SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = N'AW00000009' SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = 'AW00000009'
Por lo tanto, se generan consultas incorrectas:

Para resolver este problema, asegúrese de que los tipos de datos coincidan.
LIKE &Índice suprimido
De hecho, tener un índice de cobertura no significa que lo usará de manera efectiva.
Vamos a comprobarlo en este ejemplo en particular. Supongamos que necesitamos mostrar todas las filas que comienzan con…
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
Obtendremos las siguientes lecturas lógicas y planes de ejecución:
Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 4, ...
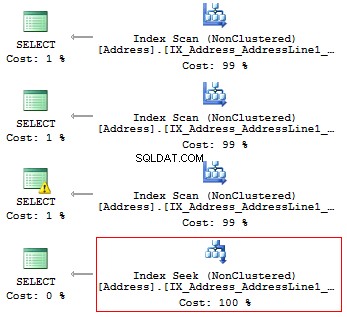
Por lo tanto, si hay un índice, no debe contener ningún cálculo o conversión de tipos, funciones, etc.
Pero, ¿qué hace si necesita encontrar la aparición de una subcadena en una cadena?
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'v
Volveremos a esta pregunta más tarde.
Unicode frente a ANSI
Es importante recordar que existen los UNICODE y ANSI instrumentos de cuerda. El tipo UNICODE incluye NVARCHAR/NCHAR (2 bytes a un símbolo). Para almacenar ANSI cadenas, es posible usar VARCHAR/CHAR (1 byte a 1 símbolo). También hay TEXT/NTEXT , pero no recomiendo usarlos ya que pueden disminuir el rendimiento.
Si especifica una constante Unicode en una consulta, es necesario precederla con el símbolo N. Para comprobarlo, ejecute la siguiente consulta:
SELECT '文本 ANSI'
, N'文本 UNICODE'
------- ------------
?? ANSI 文本 UNICODE Si N no precede a la constante, SQL Server intentará encontrar un símbolo adecuado en la codificación ANSI. Si no lo encuentra, mostrará un signo de interrogación.
COLOCAR
Muy a menudo, cuando se lo entrevista para el puesto de Desarrollador de base de datos intermedio/superior, un entrevistador suele hacer la siguiente pregunta:¿Esta consulta devolverá los datos?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b Depende. En primer lugar, el símbolo N no precede a una constante de cadena, por lo que se interpretará como ANSI. En segundo lugar, mucho depende del valor COLLATE actual, que es un conjunto de reglas, al seleccionar y comparar datos de cadena.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b Esta instrucción COLLATE devolverá signos de interrogación ya que sus símbolos son iguales:
---- ---- ? ?
Si cambiamos la sentencia COLLATE por otra sentencia:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
En este caso, la consulta no devolverá nada, ya que los caracteres cirílicos se interpretarán correctamente.
Por lo tanto, si una constante de cadena ocupa UNICODE, entonces es necesario establecer N antes de una constante de cadena. Aún así, no recomendaría configurarlo en todas partes por las razones que hemos discutido anteriormente.
Otra pregunta que se hará en la entrevista se refiere a la comparación de filas.
Considere el siguiente ejemplo:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE') ¿Estas filas son iguales? Para verificar esto, necesitamos especificar explícitamente COLLATE:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE') Como hay COLLATE que distingue entre mayúsculas y minúsculas (CS) y no distingue entre mayúsculas y minúsculas (CI) al comparar y seleccionar filas, no podemos decir con certeza si son iguales. Además, hay varios COLLATE tanto en un servidor de prueba como en el lado del cliente.
Existe un caso en el que COLLATE de una base de destino y tempdb no coinciden.
Cree una base de datos con COLLATE:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t Al crear una tabla, hereda COLLATE de una base de datos. La única diferencia para la primera tabla temporal, para la cual determinamos una estructura explícitamente sin COLLATE, es que hereda COLLATE de tempdb base de datos.
------ -------------------------- tempdb Cyrillic_General_CI_AS test Albanian_100_CS_AS t Albanian_100_CS_AS #t1 Cyrillic_General_CI_AS #t2 Albanian_100_CS_AS #t3 Albanian_100_CS_AS @t Albanian_100_CS_AS
Describiré el caso en el que COLLATE no coincide en el ejemplo particular con #t1.
Por ejemplo, los datos no se filtran correctamente, ya que COLLATE puede no tener en cuenta un caso:
SELECT * FROM #t1 WHERE c = 'A'
Alternativamente, podemos tener un conflicto para conectar tablas con COLLATE diferentes:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c
Todo parece funcionar perfectamente en un servidor de prueba, mientras que en un servidor cliente obtenemos un error:
Msg 468, Level 16, State 9, Line 93 Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
Para evitarlo, tenemos que establecer hacks en todas partes:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c COLLATE database_default
CLASIFICACIÓN BINARIA
Ahora, descubriremos cómo usar COLLATE para su beneficio.
Considere el ejemplo con la aparición de una subcadena en una cadena:
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
Es posible optimizar esta consulta y reducir su tiempo de ejecución.
Primero, necesitamos generar una tabla grande:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) t Cree columnas calculadas con COLLATE binarios e índices:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin) Ejecutar el proceso de filtración:
SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFF
Como puede ver, esta consulta devuelve el siguiente resultado:
SQL Server Execution Times: CPU time = 350 ms, elapsed time = 354 ms. SQL Server Execution Times: CPU time = 335 ms, elapsed time = 355 ms. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 17 ms, elapsed time = 18 ms.
El punto es que el filtro basado en la comparación binaria toma menos tiempo. Por lo tanto, si necesita filtrar la ocurrencia de cadenas con frecuencia y rapidez, entonces es posible almacenar datos con COLLATE que termina en BIN. Sin embargo, se debe tener en cuenta que todos los COLLATE binarios distinguen entre mayúsculas y minúsculas.
Estilo de código
Un estilo de codificación es estrictamente individual. Aún así, este código debe ser mantenido simplemente por otros desarrolladores y cumplir con ciertas reglas.
Cree una base de datos separada y una tabla dentro:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)
Luego, escribe la consulta:
select employeeid from employee
Ahora, cambie COLLATE a cualquiera que distinga entre mayúsculas y minúsculas:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Luego, intente ejecutar la consulta nuevamente:
Msg 208, Level 16, State 1, Line 19 Invalid object name 'employee'.
Un optimizador usa reglas para COLLATE actual en el paso de vinculación cuando verifica tablas, columnas y otros objetos y compara cada objeto del árbol de sintaxis con un objeto real de un catálogo del sistema.
Si desea generar consultas manualmente, debe usar siempre el caso correcto en los nombres de los objetos.
En cuanto a las variables, COLLATE se heredan de la base de datos maestra. Por lo tanto, también debe usar el caso correcto para trabajar con ellos:
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empid En este caso, no obtendrá un error:
----------------------- Cyrillic_General_CI_AS ----------- 1
Aún así, un caso de error puede aparecer en otro servidor:
-------------------------- Latin1_General_CS_AS Msg 137, Level 15, State 2, Line 4 Must declare the scalar variable "@empid".
[var]carácter
Como sabes, hay fijos (CHAR , NCHAR ) y variable (VARCHAR , NVARCHAR ) tipos de datos:
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE') Si una fila tiene una longitud fija, digamos 20 símbolos, pero ha escrito solo 4 símbolos, SQL Server agregará 16 espacios en blanco a la derecha de manera predeterminada:
--- --- ---- ---- ---------------------- ---------------------- 4 4 20 4 "text " "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a = b b = a a LIKE b b LIKE a ----- ----- -------- -------- TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1 WHERE 'a ' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a ' -- !!! SELECT 1 WHERE 'a' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale') As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- ----- 0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ---- 40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ---- N NULL ---- ---- 7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3 SELECT 1.0 / 3
Sin embargo, no lo es. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
----------- 0 ----------- 0.333333
Also, let’s consider this particular example:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val) This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id] FROM sys.system_objects UNION SELECT [object_id] FROM sys.objects SELECT [object_id] FROM sys.system_objects UNION ALL SELECT [object_id] FROM sys.objects
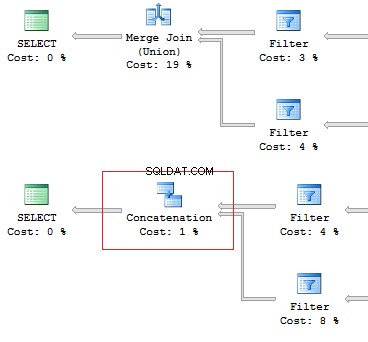
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLine As we have OR in the statement, we will receive IndexScan:
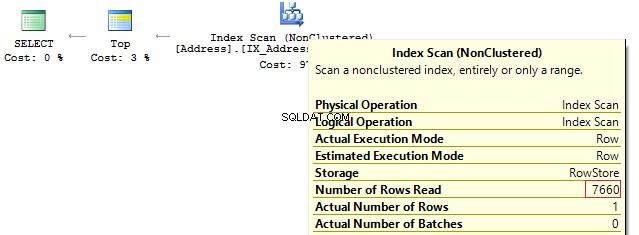
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) t When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
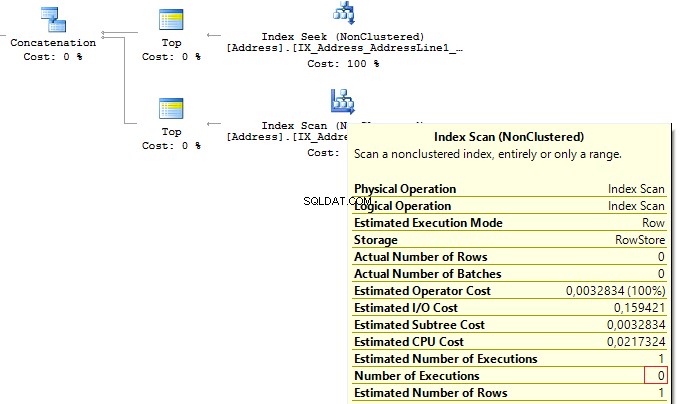
Table 'Worktable'. Scan count 0, logical reads 0, ... Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ... Table 'Employee'. Scan count 1, logical reads 2, ... Table 'Person'. Scan count 0, logical reads 888, ... Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT p.BusinessEntityID
, (
SELECT s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
)
FROM Person.Person p However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID
, (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
)
FROM Person.Person p
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
OUTER APPLY (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
) t When executing these queries, we will get the same issue – multiple IndexSeek operators:
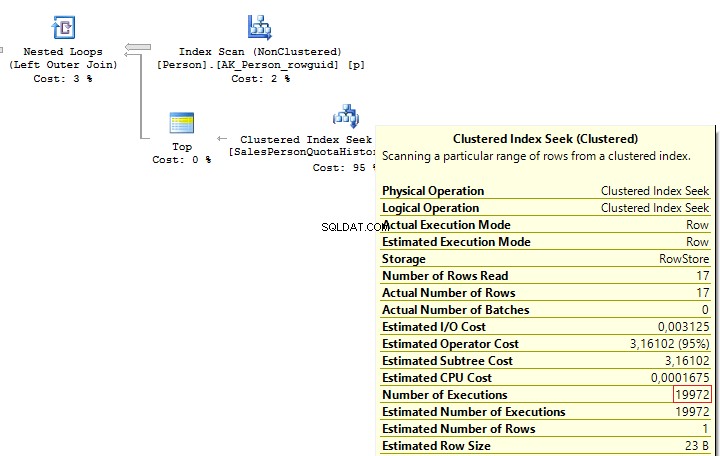
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ... Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
LEFT JOIN (
SELECT s.BusinessEntityID
, s.SalesQuota
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC)
FROM Sales.SalesPersonQuotaHistory s
) t ON p.BusinessEntityID = t.BusinessEntityID
AND t.RowNum = 1 We get the following result:
Table 'Person'. Scan count 1, logical reads 67, ... Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014
GO
SELECT BusinessEntityID
, Gender
, Gender =
CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee SQL Server will decompose the statement to the following:
SELECT BusinessEntityID
, Gender
, Gender =
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL
DROP FUNCTION dbo.GetMailUrl
GO
CREATE FUNCTION dbo.GetMailUrl
(
@Email NVARCHAR(50)
)
RETURNS NVARCHAR(50)
AS BEGIN
RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))
END Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
--WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID
, EmailAddress
, CASE MailUrl
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM (
SELECT TOP(10) EmailAddressID
, EmailAddress
, MailUrl = dbo.GetMailUrl(EmailAddress)
FROM Person.EmailAddress
) t In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'M' THEN '...'
WHEN Gender = 'M' THEN '......'
WHEN Gender = 'F' THEN 'Female'
WHEN Gender = 'F' THEN '...'
ELSE 'Unknown'
END
FROM HumanResources.Employee Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE 1/0
END
GO
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE MIN(1/0)
END Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
END The queries return the identical data:
SET STATISTICS TIME ON
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL)
OR AddressLine1 = AddressLine2
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFF However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times: CPU time = 63 ms, elapsed time = 57 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL
DROP FUNCTION dbo.GetPI
GO
CREATE FUNCTION dbo.GetPI ()
RETURNS FLOAT
WITH SCHEMABINDING
AS BEGIN
RETURN PI()
END
GO
SELECT dbo.GetPI()
FROM Sales.Currency In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (a INT, b INT)
GO
INSERT INTO dbo.tbl VALUES (0, 1)
GO
IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL
DROP VIEW dbo.vw_tbl
GO
CREATE VIEW dbo.vw_tbl
AS
SELECT * FROM dbo.tbl
GO
SELECT * FROM dbo.vw_tbl As you can see, we get the correct result:
a b ----------- ----------- 0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl
ADD c INT NOT NULL DEFAULT 2
GO
SELECT * FROM dbo.vw_tbl We receive the same result:
a b ----------- ----------- 0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl' GO SELECT * FROM dbo.vw_tbl
Result:
a b c ----------- ----------- ----------- 0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployee
AS
SELECT e.BusinessEntityID
, p.Title
, p.FirstName
, p.MiddleName
, p.LastName
, p.Suffix
, e.JobTitle
, pp.PhoneNumber
, pnt.[Name] AS PhoneNumberType
, ea.EmailAddress
, p.EmailPromotion
, a.AddressLine1
, a.AddressLine2
, a.City
, sp.[Name] AS StateProvinceName
, a.PostalCode
, cr.[Name] AS CountryRegionName
, p.AdditionalContactInfo
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID
JOIN Person.[Address] a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID
LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID
, FirstName
, LastName
FROM HumanResources.vEmployee
SELECT p.BusinessEntityID
, p.FirstName
, p.LastName
FROM Person.Person p
WHERE p.BusinessEntityID IN (
SELECT e.BusinessEntityID
FROM HumanResources.Employee e
) Look at the execution plan in the case of using a view:
Table 'EmailAddress'. Scan count 290, logical reads 640, ... Table 'PersonPhone'. Scan count 290, logical reads 636, ... Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ... Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INT
DECLARE cur CURSOR FOR
SELECT BusinessEntityID
FROM HumanResources.Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE cur Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT puede ser usado. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (i CHAR(1))
INSERT INTO #t
VALUES ('1'), ('2'), ('3') Then, assign values to the variable:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t SELECT @txt -------- 123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t ORDER BY LEN(i) SELECT @txt -------- 3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] = i
FROM #t
FOR XML PATH('')
--------
123 It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
------------------------ ------------------------------------
ScrapReason ScrapReasonID, Name, ModifiedDate
Shift ShiftID, Name, StartTime, EndTime In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name
, STUFF((
SELECT ', ' + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
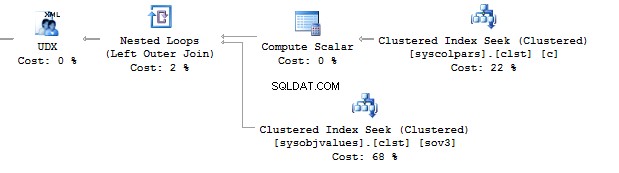
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name
, STUFF((
SELECT ', ' + CHAR(13) + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX) SET @param = 1 DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param PRINT @SQL EXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1
If we add any additional value to the property,
SET @param = '1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn);
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read()) {}
}
} When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)
SET @param = '1; select ''hack'''
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id'
PRINT @SQL
EXEC sys.sp_executesql @SQL
, N'@schema_id INT'
, @schema_id = @param It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
"SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn);
command.Parameters.Add(new SqlParameter("schema_id", value));
...
} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.