Comenzamos a hablar sobre los problemas de replicación transaccional de SQL Server anteriormente. Ahora, vamos a continuar con algunas demostraciones prácticas más para comprender los problemas de rendimiento de la replicación que se enfrentan con frecuencia y cómo solucionarlos correctamente.
Ya hemos discutido problemas como problemas de configuración, problemas de permisos, problemas de conectividad y problemas de integridad de datos junto con la resolución de problemas y su reparación. Ahora, nos vamos a centrar en varios problemas de rendimiento y problemas de corrupción que afectan la replicación de SQL Server.
Dado que los problemas de corrupción son un tema muy amplio, analizaremos su impacto solo en este artículo y no entraremos en detalles. He elegido varios escenarios que pueden incluir problemas de rendimiento y corrupción según mi experiencia:
- Problemas de rendimiento
- Transacciones activas de ejecución prolongada en la base de datos de Publisher
- Operaciones masivas de INSERCIÓN/ACTUALIZACIÓN/ELIMINACIÓN en artículos
- Grandes cambios de datos en una sola transacción
- Bloqueos en la base de datos de distribución
- Cuestiones relacionadas con la corrupción
- Corrupciones de la base de datos del editor
- Corrupciones en la base de datos de distribución
- Corrupciones en la base de datos de suscriptores
- Corrupciones de la base de datos MSDB
Problemas de rendimiento
La replicación transaccional de SQL Server es una arquitectura complicada que involucra varios parámetros, como la base de datos del publicador, la base de datos del distribuidor (distribución), la base de datos del suscriptor y varios agentes de replicación que se ejecutan como trabajos del Agente SQL Server.
Como hemos discutido todos estos elementos en detalle en nuestros artículos anteriores, sabemos la importancia de cada uno para la funcionalidad de replicación. Todo lo que afecte a estos componentes puede afectar al rendimiento de la replicación de SQL Server.
Por ejemplo, la instancia de la base de datos de Publisher contiene una base de datos crítica con muchas transacciones por segundo. Sin embargo, los recursos del servidor tienen un cuello de botella como el uso constante de la CPU por encima del 90 % o el uso de la memoria por encima del 90 %. Definitivamente tendrá un impacto en el rendimiento del trabajo del agente de lectura de registros que lee los datos de cambio de los registros de transacciones de la base de datos del editor.
Del mismo modo, cualquiera de estos escenarios en las instancias de bases de datos de Distribuidor o Suscriptor puede afectar al Agente de instantáneas o al Agente de distribución. Por lo tanto, como DBA, debe asegurarse de que los recursos del servidor, como la CPU, la memoria física y el ancho de banda de la red, estén configurados de manera eficiente para las instancias de la base de datos del publicador, el distribuidor y el suscriptor.
Suponiendo que los servidores de la base de datos del publicador, el suscriptor y el distribuidor estén configurados correctamente, aún podemos tener problemas de rendimiento de replicación cuando nos encontramos con los escenarios a continuación.
Transacciones activas de ejecución prolongada en la base de datos del editor
Como su nombre lo indica, las transacciones activas de ejecución prolongada muestran que hay una llamada de aplicación o una operación de usuario dentro del alcance de la transacción ejecutándose durante mucho tiempo.
Encontrar una transacción activa de ejecución prolongada significa que la transacción aún no se ha confirmado y la aplicación puede revertirla o confirmarla. Esto evitará que el registro de transacciones se trunque, lo que provocará que el tamaño del archivo del registro de transacciones aumente continuamente.
Log Reader Agent escanea todos los registros comprometidos que están marcados para la replicación desde los registros transaccionales en un orden serializado basado en el número de secuencia de registro (LSN), omitiendo todos los demás cambios que ocurren para los artículos que no se replican. Si los comandos de transacciones activas de ejecución prolongada aún no se han confirmado, la replicación omitirá el envío de esos comandos y enviará todas las demás transacciones confirmadas a la base de datos de distribución. Una vez que se confirma la transacción activa de ejecución prolongada, los registros se enviarán a la base de datos de distribución y, hasta ese momento, la parte inactiva del archivo de registro de transacciones de Publisher DB no se borrará, lo que provocará que el archivo de registro de transacciones de la base de datos de Publisher aumente.
Podemos probar el escenario de transacciones activas de larga duración realizando los siguientes pasos:
De forma predeterminada, el Agente de distribución limpia todos los cambios confirmados en la base de datos del Suscriptor, conservando el último registro para monitorear los nuevos cambios según el Número de secuencia de registro (LSN).
Podemos ejecutar las siguientes consultas para verificar el estado de los registros disponibles en MSRepl_Commands tablas o usando el sp_browsereplcmds procedimiento en la base de datos de distribución:
exec sp_browsereplcmds
GO
SELECT * FROM MSrepl_commands
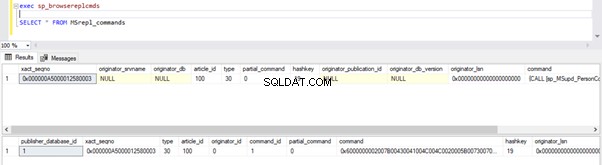
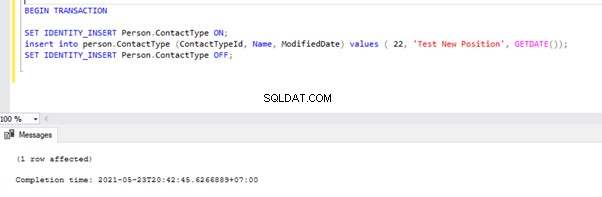
Ahora, abra una nueva ventana de consulta y ejecute el siguiente script para crear una transacción activa de larga duración en AdventureWorks base de datos. Tenga en cuenta que el siguiente script no incluye ningún comando ROLLBACK o COMMIT TRANSACTION. Por lo tanto, recomendamos no ejecutar este tipo de comandos en la base de datos de Producción.
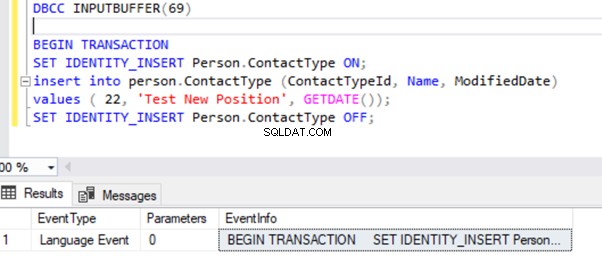
BEGIN TRANSACTION
SET IDENTITY_INSERT Person.ContactType ON;
insert into person.ContactType (ContactTypeId, Name, ModifiedDate) values ( 22, 'Test New Position', GETDATE());
SET IDENTITY_INSERT Person.ContactType OFF;
Podemos verificar que este nuevo registro no se ha replicado en la base de datos de suscriptores. Para eso, ejecutaremos la instrucción SELECT en Person.ContactType tabla en la base de datos de suscriptores:
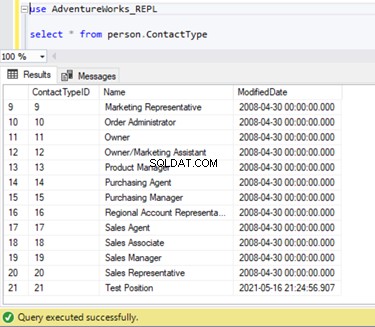
Verifiquemos si Log Reader Agent leyó el comando INSERT anterior y lo escribió en la base de datos de distribución.
Ejecute los scripts de la parte del Paso 1 nuevamente. Los resultados aún muestran el mismo estado anterior, lo que confirma que el registro no se leyó de los registros de transacciones de la base de datos del editor.
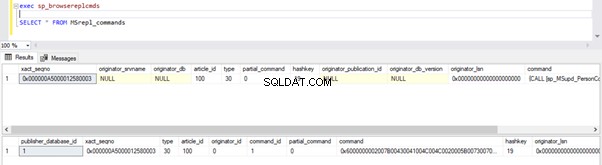
Ahora abra una Nueva Consulta y ejecute la siguiente secuencia de comandos UPDATE para ver si Log Reader Agent pudo omitir la transacción activa de ejecución prolongada y leer los cambios realizados por esta instrucción UPDATE.
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
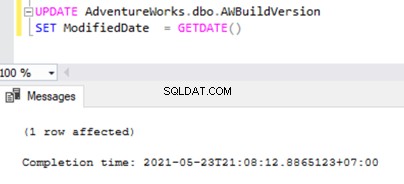
Compruebe en la base de datos de distribución si Log Reader Agent pudo capturar este cambio. Ejecute el script como parte del Paso 1:
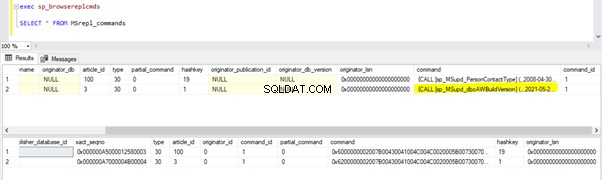
Dado que la instrucción UPDATE anterior se confirmó en la base de datos del publicador, Log Reader Agent podría escanear este cambio e insertarlo en la base de datos de distribución. Posteriormente, aplicó este cambio a la base de datos de suscriptores como se muestra a continuación:
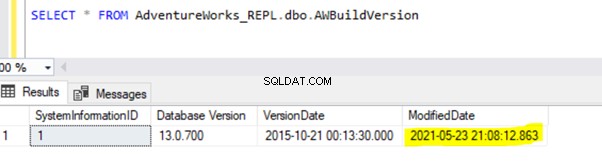
INSERTAR en Person.ContactType se replicará en la base de datos del suscriptor solo después de que la transacción INSERT se confirme en la base de datos del publicador. Antes de comprometernos, podemos verificar rápidamente cómo identificar una transacción activa de ejecución prolongada, comprenderla y manejarla de manera eficiente.
Identificar una transacción activa de larga duración
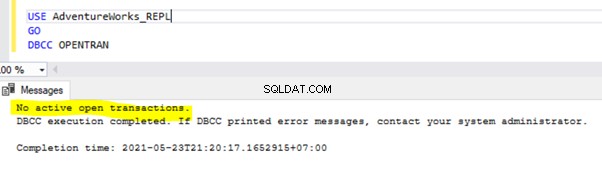
Para verificar transacciones activas de ejecución prolongada en cualquier base de datos, abra una nueva Ventana de consulta y conéctese a la base de datos respectiva que necesitamos verificar. Ejecute DBCC OPENTRAN comando de consola:es un comando de consola de base de datos para ver las transacciones abiertas en la base de datos en el momento de la ejecución.
USE AdventureWorks
GO
DBCC OPENTRAN
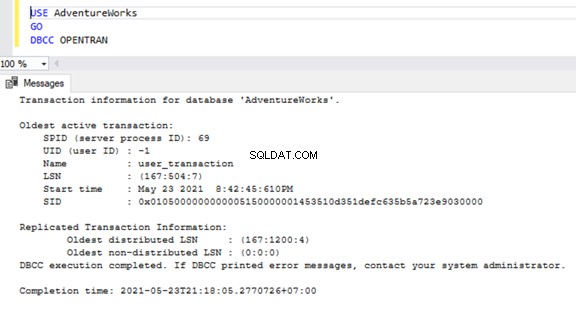
Ahora sabemos que había un SPID (ID de proceso del servidor ) 69 corriendo durante mucho tiempo. Verifiquemos qué comando se ejecutó en esa transacción usando DBCC INPUTBUFFER comando de la consola (un comando de la consola de la base de datos que se usa para identificar el comando o la operación que se está realizando en el ID del proceso del servidor seleccionado).
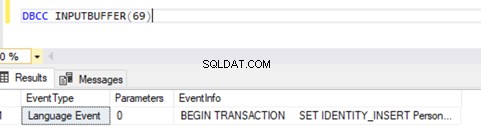
Para facilitar la lectura, estoy copiando EventInfo valor del campo y formateándolo para mostrar el comando que hemos ejecutado anteriormente.
Si no hay transacciones activas de ejecución prolongada en la base de datos seleccionada, obtendremos el siguiente mensaje:
Similar al DBCC OPENTRAN comando de la consola, podemos SELECCIONAR de DMV llamado sys.dm_tran_database_transactions para obtener resultados más detallados (consulte el artículo de MSDN para obtener más información).
Ahora, sabemos cómo identificar la transacción de larga duración. Podemos confirmar la transacción y ver cómo se replica la instrucción INSERT.
Ir a la ventana donde hemos insertado el registro a la Person.ContactType dentro del ámbito de la transacción y ejecute COMMIT TRANSACTION como se muestra a continuación:
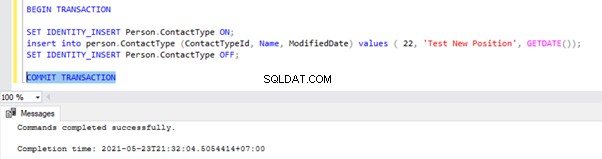
La ejecución de COMMIT TRANSACTION confirmó el registro en la base de datos de Publisher. Por lo tanto, debería estar visible en la base de datos de distribución y en la base de datos de suscriptores:
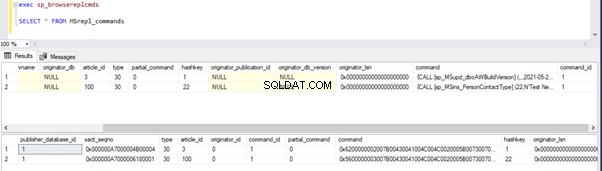
Si lo ha notado, los registros más antiguos de la base de datos de distribución fueron limpiados por el trabajo de limpieza del agente de distribución. El nuevo registro para INSERT en Person.ContactType la tabla estaba visible en MSRepl_cmds mesa.
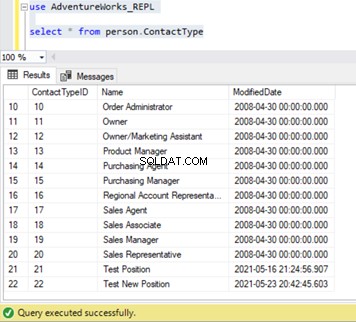
De nuestras pruebas, hemos aprendido lo siguiente:
- El trabajo del Agente de registro de registros de la replicación transaccional de SQL Server buscará registros confirmados solo desde la base de datos de registros transaccionales del publicador e INSERTAR en la base de datos del suscriptor.
- El orden de los datos modificados en la base de datos del publicador que se envía al suscriptor se basará en el estado de compromiso y el tiempo en la base de datos del publicador, aunque los datos replicados tendrán el mismo tiempo que en la base de datos del publicador.
- La identificación de transacciones activas de ejecución prolongada puede ayudar a resolver el crecimiento del archivo de registro transaccional del editor, distribuidor, suscriptor o cualquier base de datos.
Operaciones masivas SQL INSERT/UPDATE/DELETE en artículos
Con una gran cantidad de datos que residen en la base de datos de Publisher, a menudo terminamos con requisitos para INSERTAR, ACTUALIZAR o ELIMINAR registros enormes en las tablas replicadas.
Si las operaciones INSERTAR, ACTUALIZAR o ELIMINAR se realizan en una sola transacción, definitivamente terminará en la replicación atascada durante mucho tiempo.
Digamos que necesitamos INSERTAR 10 millones de registros en una tabla replicada. Insertar esos registros en una sola toma causará problemas de rendimiento.
INSERT INTO REplicated_table
SELECT * FROM Source_table
En su lugar, podemos INSERTAR registros en lotes de 0,1 o 0,5 millones de registros en un MIENTRAS bucle o bucle CURSOR , y garantizará una replicación más rápida. Es posible que no recibamos problemas importantes para las declaraciones INSERT a menos que la tabla involucrada tenga muchos índices. Sin embargo, esto tendrá un gran impacto en el rendimiento de las declaraciones UPDATE o DELETE.
Supongamos que hemos agregado una nueva columna a la tabla replicada que tiene alrededor de 10 millones de registros. Queremos actualizar esta nueva columna con un valor predeterminado.
Idealmente, el siguiente comando funcionará bien para ACTUALIZAR los 10 millones de registros con el valor predeterminado como Abc :
-- UPDATE 10 Million records on Replicated Table with some DEFAULT values
UPDATE Replicated_table
SET new_column = 'Abc'
Sin embargo, para evitar impactos en la replicación, debemos ejecutar la operación de ACTUALIZACIÓN anterior en lotes de 0,1 o 0,5 millones de registros para evitar problemas de rendimiento.
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
UPDATE TOP(100000) Replicated_Table
SET new_Column = 'Abc'
WHERE new_column is NULL
IF @@ROWCOUNT = 0
BREAK
END
De manera similar, si necesitamos ELIMINAR alrededor de 10 millones de registros de una tabla replicada, podemos hacerlo en lotes:
-- DELETE 10 Million records on Replicated Table with some DEFAULT values
DELETE FROM Replicated_table
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
DELETE TOP(100000) Replicated_Table
IF @@ROWCOUNT = 0
BREAK
END
Manejar BULK INSERT, UPDATE o DELETE de manera eficiente puede ayudar a resolver los problemas de replicación.
Consejo profesional :Para INSERTAR grandes datos en una tabla replicada en la base de datos de Publisher, use el asistente IMPORTAR/EXPORTAR en SSMS, ya que insertará registros en lotes de 10000 o según el tamaño de registro calculado más rápido por SQL Server.
Grandes cambios de datos dentro de una sola transacción
Para mantener la integridad de los datos desde la perspectiva de la aplicación o el desarrollo, muchas aplicaciones tienen transacciones explícitas definidas para operaciones críticas. Sin embargo, si se realizan muchas operaciones (INSERTAR, ACTUALIZAR o ELIMINAR) dentro de un solo ámbito de Transacción, el Agente de lectura del registro primero esperará a que se complete la transacción, como hemos visto anteriormente.
Una vez que la aplicación confirma la transacción, el Log Reader Agent necesita escanear esos enormes cambios de datos realizados en los registros de transacciones de la base de datos de Publisher. Durante ese escaneo, podemos ver las advertencias o mensajes informativos en el Agente de lectura de registro como
El Log Reader Agent está escaneando el registro de transacciones en busca de comandos para replicar. Se escanearon aproximadamente xxxxxx registros de registro en el paso n.° xxxx, de los cuales se marcaron para replicación, tiempo transcurrido xxxxxxxxx (ms)
Antes de identificar la solución para este escenario, debemos entender cómo el agente de lectura de registros escanea los registros de los registros transaccionales e inserta registros en la base de datos de distribución MSrepl_transactions y MSrepl_cmds mesas.
SQL Server tiene internamente un número de secuencia de registro (LSN) dentro de los registros de transacciones. El Log Reader Agent utiliza los valores LSN para escanear los cambios marcados para la replicación de SQL Server en orden.
Log Reader Agent ejecuta sp_replcmds procedimiento almacenado extendido para obtener los comandos marcados para replicación de la base de datos de registros transaccionales de Publisher.
Sp_replcmds acepta un parámetro de entrada llamado @maxtrans para obtener el número máximo de transacciones. El valor predeterminado sería 1, lo que significa que escaneará cualquier cantidad de transacciones disponibles de los registros para enviarlas a la base de datos de distribución. Si hay 10 operaciones INSERT realizadas a través de una sola transacción y confirmadas en la base de datos de Publisher, un solo lote puede contener 1 transacción con 10 comandos.
Si se identifican muchas transacciones con menos comandos, el Agente de lectura del registro combinará varias transacciones o el XACT número de secuencia a un único lote de replicación. Pero se almacena como un XACT diferente Secuencia número en las MSRepl_transactions mesa. Los comandos individuales que pertenecen a esa transacción se capturarán en MSRepl_commands mesa.
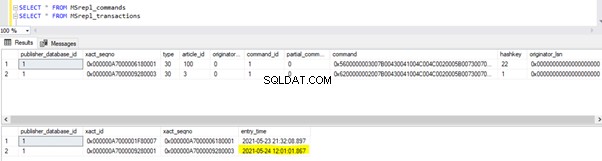
Para verificar las cosas que hemos discutido anteriormente, estoy actualizando la ModifiedDate columna de dbo.AWBuildVersion table hasta la fecha de hoy y vea qué sucede:
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Antes de ejecutar la ACTUALIZACIÓN, verificamos los registros presentes en los MSrepl_commands y MSrepl_transactions tablas:
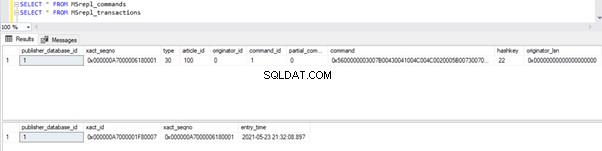
Ahora, ejecute el script UPDATE anterior y verifique los registros presentes en esas 2 tablas:
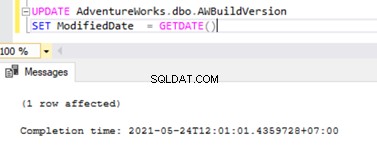
Se insertó un nuevo registro con la hora de ACTUALIZACIÓN en MSrepl_transactions tabla con el entry_time cercano . Verificando el comando en este xact_seqno mostrará la lista de comandos agrupados lógicamente usando sp_browsereplcmds procedimiento.

En el Monitor de replicación, podemos ver una única declaración de ACTUALIZACIÓN capturada en 1 transacción(es) con 1 comando(s) del publicador al distribuidor.
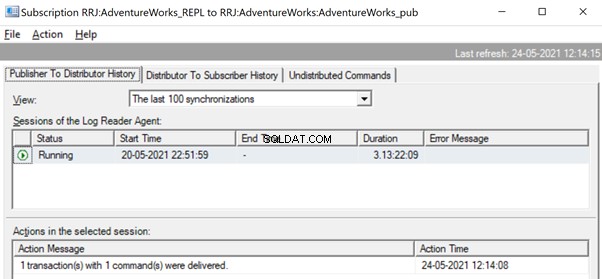
Y podemos ver el mismo comando entregado del Distribuidor al Suscriptor en una fracción de segundo de diferencia. Indica que la replicación está ocurriendo correctamente.
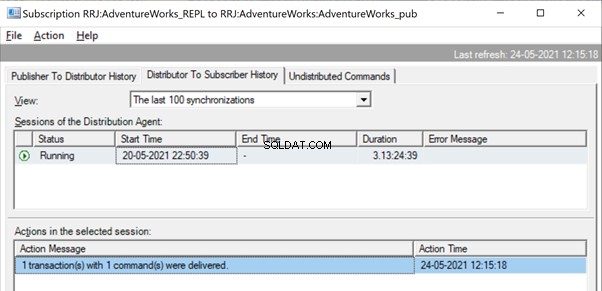
Ahora, si hay una gran cantidad de transacciones combinadas en un solo xact_seqno , podemos ver mensajes como Se entregaron 10 transacciones con 5000 comandos .
Verifiquemos esto ejecutando UPDATE en 2 tablas diferentes al mismo tiempo:
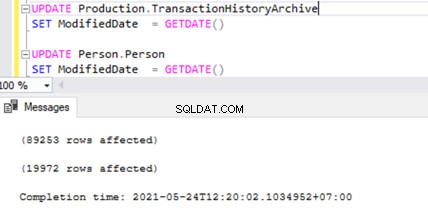
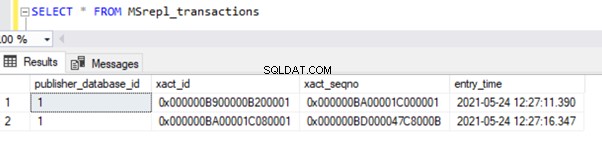
Podemos ver dos registros de transacciones en MSrepl_transactions tabla que coincida con las dos operaciones de ACTUALIZACIÓN y luego el no. de registros en esa tabla que coincidan con el no. de registros actualizados.
El resultado de las MSrepl_transactions tabla:
El resultado de MSrepl_commands tabla:
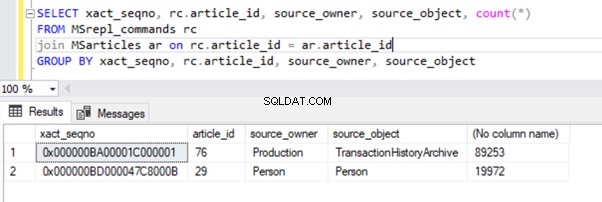
Sin embargo, hemos notado que estas 2 transacciones están agrupadas lógicamente por el Log Reader Agent y combinadas en un solo lote como 2 transacciones con 109225 comandos.
Pero antes de eso, es posible que veamos mensajes como Entregando transacciones replicadas, recuento exacto:1, recuento de comandos 46601 .
Esto sucederá hasta que el Agente de lectura de registros escanee el conjunto completo de cambios e identifique que 2 transacciones de ACTUALIZACIÓN se leyeron por completo de los Registros de transacciones.
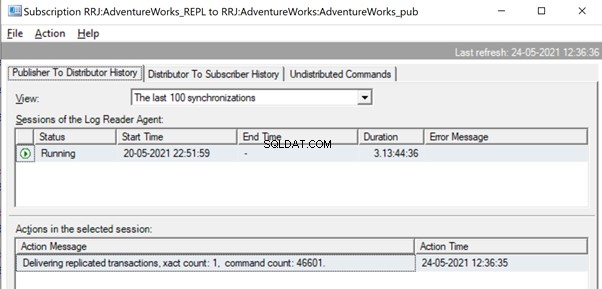
Una vez que los comandos se leen por completo de los registros de transacciones, vemos que el agente de Log Reader entregó 2 transacciones con 109225 comandos:
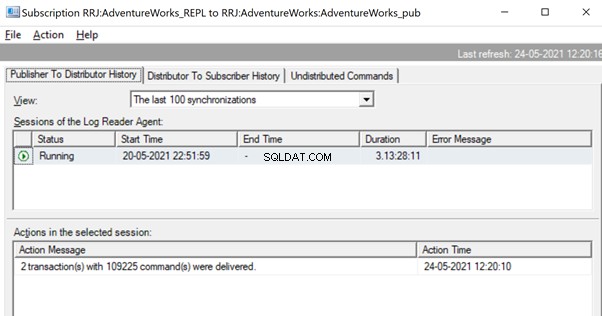
Dado que el agente de distribución está esperando que se replique una transacción enorme, es posible que veamos un mensaje como Entregando transacciones replicadas lo que indica que se ha replicado una gran transacción y debemos esperar a que se replique por completo.
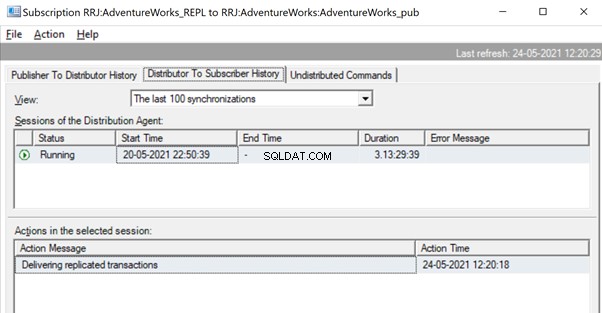
Una vez replicado, también podemos ver el siguiente mensaje en el Agente de distribución:
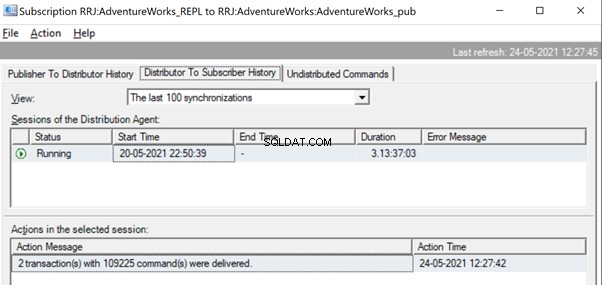
Varias formas son útiles para resolver estos problemas.
Forma 1:CREAR un nuevo procedimiento almacenado de SQL
Debe crear un nuevo procedimiento almacenado y encapsular la lógica de la aplicación en él bajo el alcance de la Transacción.
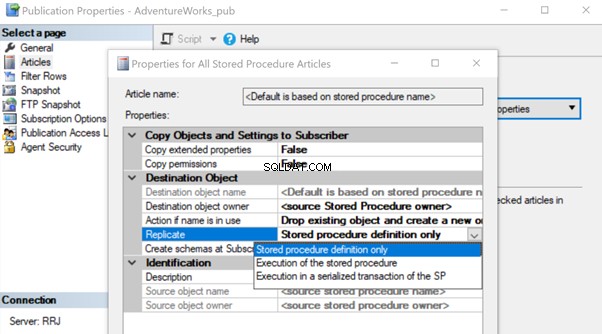
Una vez creado, agregue ese artículo de Procedimiento almacenado a Replicación y cambie la propiedad del artículo Replicar a Ejecución del procedimiento almacenado opción.
Ayudará a ejecutar el artículo Procedimiento almacenado en el suscriptor en lugar de replicar todos los cambios de datos individuales que estaban ocurriendo.
Revisemos cómo la Ejecución del Procedimiento Almacenado La opción para replicar reduce la carga en la replicación. Para hacerlo, podemos crear un procedimiento almacenado de prueba como se muestra a continuación:
CREATE procedure test_proc
AS
BEGIN
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Production.TransactionHistoryArchive
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Person.Person
SET ModifiedDate = GETDATE()
END
El procedimiento anterior ACTUALIZARÁ un solo registro en AWBuildVersion tabla y 10 registros cada uno en Production.TransactionHistoryArchive y Persona.Persona tablas con un total de hasta 21 cambios de registro.
Después de crear este nuevo procedimiento tanto en el publicador como en el suscriptor, agréguelo a la replicación. Para eso, haga clic derecho en Publicación y elija el artículo de procedimiento para Replicación con la definición de procedimiento almacenado por defecto solamente opción.
Una vez hecho esto, podemos verificar los registros disponibles en MSrepl_transactions y MSrepl_commands mesas.
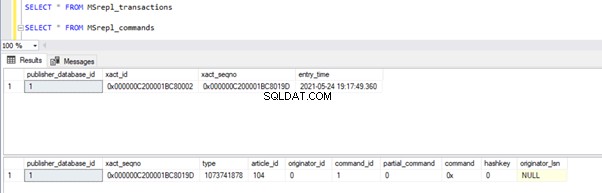
Ahora, ejecutemos el procedimiento en la base de datos de Publisher para ver cuántos registros se rastrean.
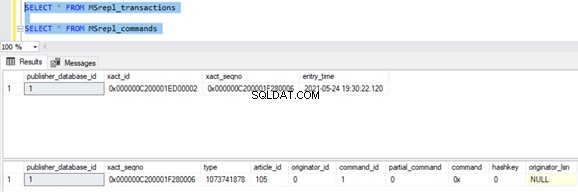
Podemos ver lo siguiente en las tablas de distribución MSrepl_transactions y MSrepl_commands :
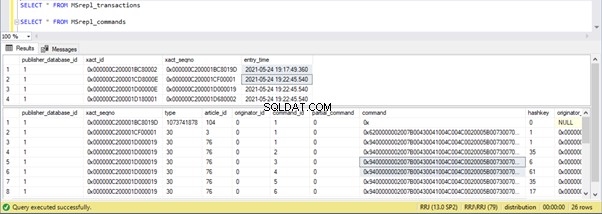
Tres xact_seqno se crearon para tres operaciones UPDATE en MSrepl_transactions y se insertaron 21 comandos en MSrepl_commands mesa.
Abra el Monitor de replicación y vea si se envían como 3 lotes de replicación diferentes o un solo lote con 3 transacciones juntas.
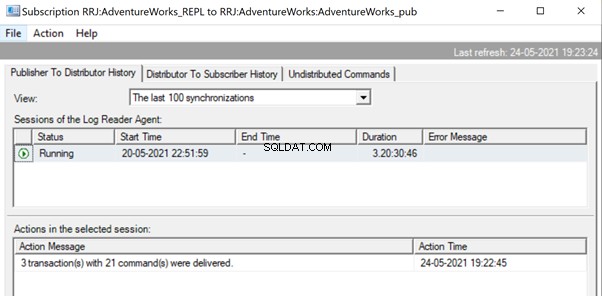
Podemos ver que tres xact_seqno se consolidó como un solo lote de replicación. Por lo tanto, podemos ver que 3 transacciones con 21 comandos se entregaron con éxito.
Eliminemos el procedimiento de la replicación y lo agreguemos nuevamente con la segunda Ejecución del procedimiento almacenado opción. Ahora, ejecute el procedimiento y vea cómo se replican los registros.
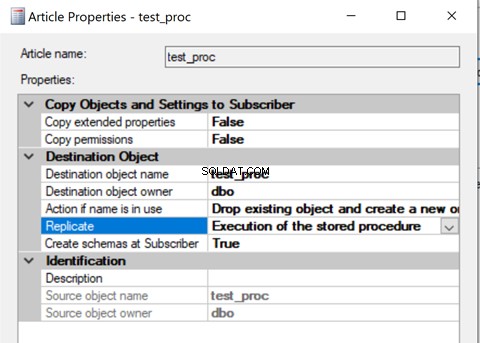
La verificación de registros de las tablas de distribución muestra los siguientes detalles:
Ahora, ejecute el procedimiento en la base de datos de Publisher y vea cuántos registros se registran en las tablas de distribución. La ejecución de un procedimiento actualizó 21 registros (1 registro, 10 registros y 10 registros) como antes.
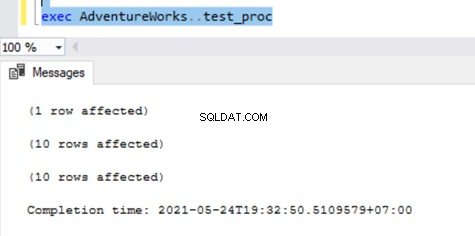
La verificación de las tablas de distribución muestra los siguientes datos:
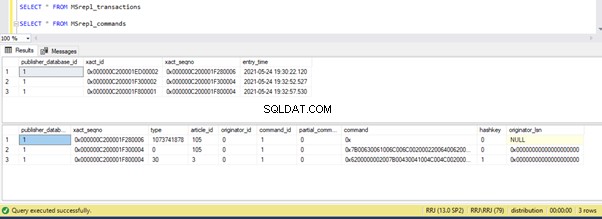
Echemos un vistazo rápido a sp_browsereplcmds para ver el comando real recibido:

El comando es “{llamar a “dbo”..”test_proc” }” que se ejecutará en la base de datos del Suscriptor.
En el Monitor de replicación, podemos ver que solo 1 transacción(es) con 1 comando(s) se entregó a través de la replicación:
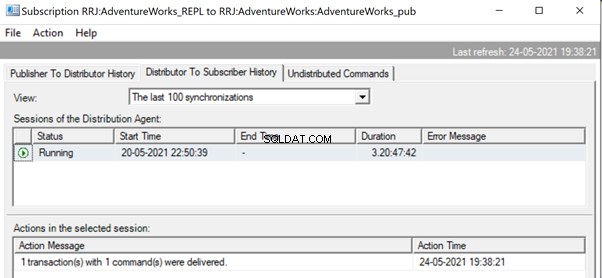
En nuestro caso de prueba, hemos utilizado un procedimiento con solo 21 cambios de datos. Sin embargo, si hacemos eso para un procedimiento complicado que involucra millones de cambios, entonces el enfoque del procedimiento almacenado con la ejecución del procedimiento almacenado será eficiente para reducir la carga de replicación.
Necesitamos validar este enfoque verificando si el procedimiento tiene la lógica para actualizar solo el mismo conjunto de registros en las bases de datos de Publisher y Subscriber. De lo contrario, esto creará problemas de inconsistencia de datos entre el publicador y el suscriptor.
Forma 2:Configuración de MaxCmdsInTran, ReadBatchSize y ReadBatchThreshold Log Reader Agent Parámetros
MaxCmdsInTran – indica el número máximo de Comandos que se pueden agrupar lógicamente dentro de una Transacción mientras se leen datos de la base de datos de Registros Transaccionales de Publisher y se escriben en la base de datos de Distribución.
En nuestras pruebas anteriores, notamos que alrededor de 109225 comandos se acumularon en una sola secuencia exacta de replicación, lo que resultó en una ligera lentitud o latencia. Si configuramos el MaxCmdsInTran parámetro a 10000, la única secuencia exacta el número se dividirá en 11 Secuencias exactas que resultan en entrega más rápida de comandos del publicador al distribuidor . Aunque esta opción ayuda a reducir la contención de la base de datos de distribución y replicar los datos más rápido desde el publicador a la base de datos del suscriptor, tenga cuidado al usar esta opción. Podría terminar entregando los datos a la base de datos del suscriptor y accediendo a ellos desde las tablas de la base de datos del suscriptor antes del final del alcance de la transacción original.
Leer tamaño de lote – Es posible que este parámetro no sea útil para un solo escenario de transacciones grandes. Sin embargo, ayuda cuando hay muchas transacciones más pequeñas en la base de datos de Publisher.
Si la cantidad de comandos por transacción es menor, el Agente de registro del LOG combinará varios cambios en un solo ámbito de transacción de comando de replicación. El tamaño del lote de lectura indica cuántas transacciones se pueden leer en el registro de transacciones antes de enviar los cambios a la base de datos de distribución. Los valores pueden estar entre 500 y 10000.
Umbral de lote de lectura – indica el número de comandos que se leerán del registro transaccional de la base de datos del publicador antes de enviarse al suscriptor con un valor predeterminado de 0 para escanear el archivo de registro completo. Sin embargo, podemos reducir este valor para enviar datos más rápido limitándolo a 10000 o 100000 comandos como ese.
Forma 3:configurar los mejores valores para el parámetro SubscriptionStreams
Flujos de suscripción – indica el número de conexiones que un agente de distribución puede ejecutar en paralelo para obtener datos de la base de datos de distribución y propagarlos a la base de datos de suscriptores. El valor predeterminado es 1, lo que sugiere solo una transmisión o conexión desde la distribución a la base de datos de suscriptores. Los valores pueden estar entre 1 y 64. Si se agregan más flujos de suscripción, podría terminar en congestión de CXPACKET (en otras palabras, paralelismo). Por lo tanto, debe tener cuidado al configurar esta opción en Producción.
Para resumir, intente evitar INSERTAR, ACTUALIZAR o ELIMINAR grandes en una sola transacción. Si es imposible eliminar estas operaciones, la mejor opción sería probar las formas anteriores y elegir la que mejor se adapte a sus condiciones específicas.
Bloqueos en la base de datos de distribución
La base de datos de distribución es el corazón de la replicación transaccional de SQL Server y, si no se mantiene adecuadamente, habrá muchos problemas de rendimiento.
Para resumir todas las prácticas recomendadas para la configuración de la base de datos de distribución, debemos asegurarnos de que las siguientes configuraciones se realicen correctamente:
- Los archivos de datos de las bases de datos de distribución deben colocarse en unidades de alto IOPS. Si la base de datos de Publisher tendrá muchos cambios de datos, debemos asegurarnos de que la base de datos de distribución se coloque en una unidad con un alto IOPS. Continuamente recibirá datos del agente Log Reader y enviará datos a la base de datos del suscriptor a través del agente de distribución. Todos los datos replicados se eliminarán de la base de datos de distribución cada 10 minutos a través del trabajo de limpieza de distribución.
- Configure el tamaño del archivo inicial y las propiedades de crecimiento automático de la base de datos de distribución con los valores recomendados según los niveles de actividad de la base de datos de Publisher. De lo contrario, provocará la fragmentación de datos y archivos de registro, lo que provocará problemas de rendimiento.
- Incluir bases de datos de distribución en los trabajos regulares de mantenimiento de índices configurados en los servidores donde se encuentra la base de datos de distribución.
- Incluya bases de datos de distribución en la programación de trabajos de copia de seguridad completa para solucionar cualquier problema específico.
- Asegúrese de que la Limpieza de distribución:distribución el trabajo se ejecuta cada 10 minutos según el programa predeterminado. De lo contrario, el tamaño de la base de datos de distribución sigue aumentando y genera problemas de rendimiento.
Como hemos notado hasta ahora, en la base de datos de distribución, las tablas clave involucradas son MSrepl_transactions y MSrepl_commands . Los registros son insertados allí por el trabajo del Agente de registro del registro, seleccionados por el trabajo del agente de distribución, aplicados en la base de datos del suscriptor y luego eliminados o limpiados por el trabajo del agente de limpieza de distribución.
Si la base de datos de distribución no está configurada correctamente, podemos encontrar bloqueos de sesión en estas 2 tablas, lo que provocará problemas de rendimiento de replicación de SQL Server.
Podemos ejecutar la siguiente consulta en cualquier base de datos para ver las sesiones de bloqueo disponibles en la instancia actual de SQL Server:
SELECT *
FROM sys.sysprocesses
where blocked > 0
order by waittime desc
Si la consulta anterior devuelve algún resultado, podemos identificar comandos en esas sesiones bloqueadas ejecutando DBCC INPUTBUFFER(spid) comando de la consola y tomar las medidas correspondientes.
Cuestiones relacionadas con la corrupción
Una base de datos de SQL Server usa su algoritmo o lógica para almacenar datos en tablas y mantenerlos en extensiones o páginas. La corrupción de la base de datos es un proceso mediante el cual el estado físico de los archivos/extensiones/páginas relacionados con la base de datos cambia de un estado normal a inestable o de no recuperación, lo que dificulta o imposibilita la recuperación de datos.
Todas las bases de datos de SQL Server son propensas a sufrir daños en la base de datos. Las causas pueden ser:
- Fallas de hardware como problemas de disco, almacenamiento o controlador;
- Fallas del sistema operativo del servidor, como problemas de aplicación de parches;
- Fallas en el suministro eléctrico que provocan un apagado abrupto de los servidores o un apagado inadecuado de la base de datos.
Si podemos recuperar o reparar bases de datos sin pérdida de datos, la replicación de SQL Server no se verá afectada. Sin embargo, si se pierden datos durante la recuperación o reparación de bases de datos corruptas, comenzaremos a recibir muchos problemas de integridad de datos que hemos discutido en nuestro artículo anterior.
Las corrupciones pueden ocurrir en varios componentes, como:
- Datos del editor/daños en el archivo de registro
- Corrupción de datos de suscriptor/archivo de registro
- Datos de la base de datos de distribución/Corrupción del archivo de registro
- Datos de la base de datos Msdb/Corrupción del archivo de registro
Si recibimos muchos problemas de integridad de datos después de solucionar los problemas de corrupción, se recomienda eliminar la replicación por completo, corregir todos los problemas de corrupción en la base de datos del editor, suscriptor o distribuidor y luego volver a configurar la replicación para solucionarlo. Otherwise, data integrity issues will persist and lead to data inconsistency across the Publisher and Subscriber. The time required to fix the Data integrity issues in case of Corrupted databases will be much more compared to configuring Replication from scratch. Hence identify the level of Corruption encountered and take optimal decisions to resolve the Replication issues faster.
Wondering why msdb database corruption can harm Replication? Since msdb database hold all details related to SQL Server Agent Jobs including Replication Agent jobs, any corruption on msdb database will harm Replication. To recover quickly from msdb database corruptions, it is recommended to restore msdb database from the last Full Backup of msdb database. This also signifies the importance of taking Full Backups of all system databases including msdb database.
Conclusión
Thanks for successfully going through the final power-packed article about the Performance issues in the SQL Server Transactional Replication. If you have gone through all articles carefully, you should be able to troubleshoot almost any Transactional Replication-based issues and fix them out efficiently.
If you need any further guidance or have any Transactional Replication-related issues in your environment, you can reach out to me for consultation. And if I missed anything essential in this article, you are welcome to point to that in the Comments section.