Introducción
No importa cuánto nos esforcemos en diseñar y desarrollar aplicaciones, siempre se producirán errores. Hay dos categorías generales:los errores de sintaxis o lógicos pueden ser errores de programación o consecuencias de un diseño de base de datos incorrecto. De lo contrario, podría recibir un error debido a una entrada de usuario incorrecta.
T-SQL (el lenguaje de programación de SQL Server) permite manejar ambos tipos de errores. Puede depurar la aplicación y decidir qué debe hacer para evitar errores en el futuro.
La mayoría de las aplicaciones requieren que registre los errores, implemente informes de errores fáciles de usar y, cuando sea posible, maneje los errores y continúe con la ejecución de la aplicación.
Los usuarios manejan los errores a nivel de declaración. Significa que cuando ejecuta un lote de comandos SQL y el problema ocurre en la última declaración, todo lo que precede a ese problema se confirmará en la base de datos como transacciones implícitas. Puede que esto no sea lo que deseas.
Las bases de datos relacionales están optimizadas para la ejecución de sentencias por lotes. Por lo tanto, debe ejecutar un lote de declaraciones como una unidad y fallar todas las declaraciones si falla una declaración. Puede lograr esto mediante el uso de transacciones. Este artículo se centrará tanto en el manejo de errores como en las transacciones, ya que estos temas están estrechamente relacionados.
Manejo de errores de SQL
Para simular excepciones, necesitamos producirlas de manera repetible. Comencemos con el ejemplo más simple:división por cero:
SELECT 1/0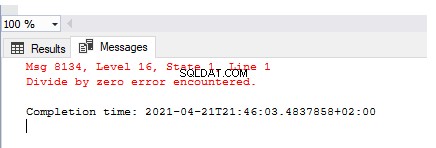
El resultado describe el error arrojado:Dividir por cero error encontrado . Pero este error no se manejó, registró ni personalizó para producir un mensaje fácil de usar.
El manejo de excepciones comienza colocando las declaraciones que desea ejecutar en el bloque BEGIN TRY…END TRY.
SQL Server maneja (captura) los errores en el bloque BEGIN CATCH…END CATCH, donde puede ingresar una lógica personalizada para el registro o procesamiento de errores.
La sentencia BEGIN CATCH tiene que seguir inmediatamente después de la sentencia END TRY. Luego, la ejecución pasa del bloque TRY al bloque CATCH en el primer error.
Aquí puede decidir cómo manejar los errores, ya sea que desee registrar los datos sobre las excepciones generadas o crear un mensaje fácil de usar.
SQL Server tiene funciones integradas que pueden ayudarlo a extraer detalles del error:
- ERROR_NUMBER():Devuelve el número de errores de SQL.
- ERROR_SEVERITY():Devuelve el nivel de gravedad que indica el tipo de problema encontrado y su nivel. Los niveles 11 a 16 pueden ser manejados por el usuario.
- ERROR_STATE():Devuelve el número de estado de error y brinda más detalles sobre la excepción lanzada. Utilice el número de error para buscar en la base de conocimientos de Microsoft detalles específicos del error.
- ERROR_PROCEDURE():Devuelve el nombre del procedimiento o disparador en el que se generó el error, o NULL si el error no ocurrió en el procedimiento o disparador.
- ERROR_LINE():Devuelve el número de línea en el que ocurrió el error. Podría ser el número de línea de procedimientos o disparadores o el número de línea en el lote.
- ERROR_MESSAGE():Devuelve el texto del mensaje de error.
El siguiente ejemplo muestra cómo manejar los errores. El primer ejemplo contiene la División por cero error, mientras que la segunda afirmación es correcta.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Si la segunda declaración se ejecuta sin manejo de errores (SELECCIONE 'Texto correcto'), tendrá éxito.
Dado que implementamos el manejo de errores personalizado en el bloque TRY-CATCH, la ejecución del programa se pasa al bloque CATCH después del error en la primera instrucción y la segunda instrucción nunca se ejecutó.
De esta manera, puedes modificar el texto que se le da al usuario y controlar mejor lo que sucede si se produce un error. Por ejemplo, registramos los errores en una tabla de registro para su posterior análisis.
Uso de transacciones
La lógica empresarial puede determinar que la inserción de la primera declaración falla cuando falla la segunda declaración, o que es posible que deba repetir los cambios de la primera declaración en la falla de la segunda declaración. El uso de transacciones le permite ejecutar un lote de declaraciones como una unidad que falla o tiene éxito.
El siguiente ejemplo demuestra el uso de transacciones.
Primero, creamos una tabla para probar los datos almacenados. Luego usamos dos transacciones dentro del bloque TRY-CATCH para simular lo que sucede si una parte de la transacción falla.
Usaremos la sentencia CATCH con la sentencia XACT_STATE(). La función XACT_STATE() se utiliza para verificar si la transacción aún existe. En caso de que la transacción se revierta automáticamente, ROLLBACK TRANSACTION produciría una nueva excepción.
Obtenga un botín en el siguiente código:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
La imagen muestra los valores en la tabla TEST_TRAN y mensajes de error:
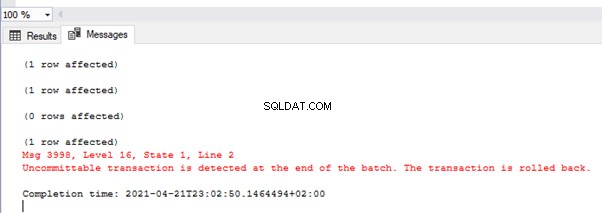
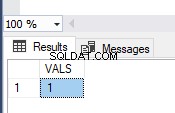
Como puede ver, solo se comprometió el primer valor. En la segunda transacción, tuvimos un error de conversión de tipo en la segunda fila. Por lo tanto, todo el lote retrocedió.
De esta manera, puede controlar qué datos ingresan a la base de datos y cómo se procesan los lotes.
Generando un mensaje de error personalizado en SQL
A veces, queremos crear mensajes de error personalizados. Por lo general, están destinados a escenarios en los que sabemos que podría ocurrir un problema. Podemos producir nuestros propios mensajes personalizados diciendo que ha ocurrido algo malo sin mostrar detalles técnicos. Para eso, estamos usando la palabra clave THROW.
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
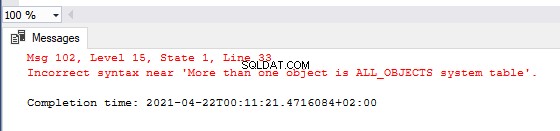
O bien, nos gustaría tener un catálogo de mensajes de error personalizados para la categorización y la coherencia de la supervisión y el informe de errores. SQL Server nos permite predefinir el código del mensaje de error, la gravedad y el estado.
Se utiliza un procedimiento almacenado llamado "sys.sp_addmessage" para agregar mensajes de error personalizados. Podemos usarlo para llamar al mensaje de error en varios lugares.
Podemos llamar a RAISERROR y enviar el número de mensaje como un parámetro en lugar de codificar los mismos detalles del error en varios lugares del código.
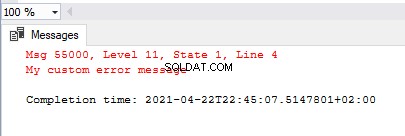
Al ejecutar el código seleccionado desde abajo, agregamos el error personalizado en SQL Server, lo generamos y luego usamos sys.sp_dropmessage para eliminar el mensaje de error definido por el usuario especificado:
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
Además, podemos ver todos los mensajes en SQL Server ejecutando el formulario de consulta a continuación. Nuestro mensaje de error personalizado es visible como el primer elemento en el conjunto de resultados:
SELECT * FROM master.dbo.sysmessages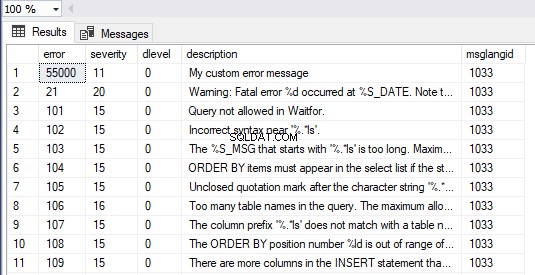
Crear un sistema para registrar errores
Siempre es útil registrar errores para su posterior depuración y procesamiento. También puede poner disparadores en estas tablas registradas e incluso configurar una cuenta de correo electrónico y ser un poco creativo en la forma de notificar a las personas cuando ocurre un error.
Para registrar errores, creamos una tabla llamada DBError_Log , que se puede utilizar para almacenar los datos de detalle del registro:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Para simular el mecanismo de registro, estamos creando el GenError procedimiento almacenado que genera la División por cero error y registra el error en DBError_Log tabla:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
El DBError_Log La tabla contiene toda la información que necesitamos para depurar el error. Además, proporciona información adicional sobre el procedimiento que provocó el error. Aunque esto puede parecer un ejemplo trivial, puede ampliar esta tabla con campos adicionales o usarla para llenarla con excepciones personalizadas.
Conclusión
Si queremos mantener y depurar aplicaciones, al menos queremos informar que algo salió mal y también registrarlo bajo el capó. Cuando tenemos una aplicación de nivel de producción utilizada por millones de usuarios, el manejo de errores consistente y reportable es la clave para depurar problemas en tiempo de ejecución.
Si bien pudimos registrar el error original en el registro de errores de la base de datos, los usuarios deberían ver un mensaje más amigable. Por lo tanto, sería una buena idea implementar mensajes de error personalizados que se envían a las aplicaciones de llamada.
Sea cual sea el diseño que implemente, debe registrar y manejar las excepciones del usuario y del sistema. Esta tarea no es difícil con SQL Server, pero debe planificarla desde el principio.
Agregar las operaciones de manejo de errores en bases de datos que ya se están ejecutando en producción puede implicar una refactorización de código grave y problemas de rendimiento difíciles de encontrar.