La base de datos es una parte crítica y vital de cualquier negocio u organización. Las tendencias crecientes predicen que el 82% de las empresas esperan que la cantidad de bases de datos aumente en los próximos 12 meses. Un gran desafío para cada DBA es descubrir cómo abordar el crecimiento masivo de datos, y este será un objetivo muy importante. ¿Cómo puede aumentar el rendimiento de la base de datos, reducir los costos y eliminar el tiempo de inactividad para brindar a sus usuarios la mejor experiencia posible? ¿La compresión de datos es una opción? Comencemos y veamos cómo algunas de las funciones existentes pueden ser útiles para manejar tales situaciones.
En este artículo, vamos a aprender cómo la solución de compresión de datos puede ayudarnos a optimizar la solución de gestión de datos. En esta guía, cubriremos los siguientes temas:
- Una descripción general de la compresión
- Beneficios de la compresión
- Un resumen sobre las técnicas de compresión de datos
- Discusión de varios tipos de compresión de datos
- Datos sobre la compresión de datos
- Consideraciones de implementación
- y más...
Compresión
La compresión es una técnica y, por lo tanto, una operación sensible a los recursos, pero con compensaciones de hardware. Uno debe pensar en implementar la compresión de datos para obtener los siguientes beneficios:
- Gestión eficaz del espacio
- Técnica eficiente de reducción de costes
- Facilidad en la gestión de copias de seguridad de la base de datos
- Utilización eficaz del ancho de banda N/W
- Recuperación o restauración segura y más rápida
- Mejor rendimiento:reduce la huella de memoria del sistema
La compresión de datos se aplica a:
- Montones
- Índices agrupados
- Índices no agrupados
- Particiones
- Vistas indexadas
Ideal para las siguientes aplicaciones:
- Tablas de registro
- Tablas de auditoría
- Tablas de hechos
- Informes
Introducción
La compresión de datos es una tecnología que existe desde SQL Server 2008. La idea de la compresión de datos es que puede elegir selectivamente tablas, índices o particiones dentro de una base de datos. La E/S continúa siendo un cuello de botella en el movimiento de información entre la entrada y la salida de la base de datos. La compresión de datos aprovecha este tipo y ayuda a aumentar la eficiencia de una base de datos. Como sabemos que las velocidades de la red son mucho más lentas que la velocidad de procesamiento, es posible encontrar ganancias de eficiencia al usar la potencia de procesamiento para comprimir datos en una base de datos, de modo que viajen más rápido. Y luego use la potencia de procesamiento nuevamente para descomprimir los datos en el otro extremo. En general, la compresión de datos reduce el espacio ocupado por los datos. La técnica de compresión de datos está disponible para todas las bases de datos y es compatible con todas las ediciones de SQL Server 2016 SP1. Antes de esto, solo estaba disponible en las ediciones SQL Server Enterprise o Developer, no en Standard o Express.
Soporte de funciones

Tipos de compresión de datos
Hay dos tipos de compresión de datos disponibles en SQL Server, nivel de fila y nivel de página.
La compresión de nivel de fila funciona en segundo plano y convierte cualquier tipo de datos de longitud fija en tipos de longitud variable. La suposición aquí es que a menudo los datos se almacenan en un tipo de longitud fija, como char 100, y en realidad no llenan los 100 caracteres completos para cada registro. Se pueden lograr pequeñas ganancias eliminando este espacio extra de la mesa. Por supuesto, si sus tablas de datos no usan texto de longitud fija y campos numéricos, o si lo hacen y realmente almacena la cantidad total permitida de caracteres y dígitos, entonces las ganancias de compresión bajo el esquema de nivel de fila serán mínimas. en el mejor de los casos.
El concepto de compresión se extiende a todos los tipos de datos de longitud fija, incluidos char, int y float. SQL Server permite ahorrar espacio al almacenar los datos como si fuera un tipo de tamaño variable; los datos aparecerán y se comportarán como una longitud fija.
Por ejemplo, si almacenó el valor de 100 en un int columna, SQL Server no necesita usar los 32 bits, sino que simplemente usa 8 bits (1 byte).
La compresión a nivel de página lleva las cosas a otro nivel. En primer lugar, aplica automáticamente la compresión de nivel de fila en campos de datos de longitud fija, por lo que automáticamente obtiene esas ganancias de forma predeterminada. Luego, además de eso, aplica algo llamado compresión de prefijo y otra técnica llamada compresión de diccionario.
Compresión de fila
La compresión de filas es un nivel interno de compresión que almacena las cadenas de caracteres fijas utilizando un formato de longitud variable al no almacenar los caracteres en blanco. Los siguientes pasos se realizan en la compresión a nivel de fila.
- Todos los tipos de datos numéricos como int , flotar , decimal, y dinero se convierten en tipos de datos de longitud variable. Por ejemplo, 125 almacenado en la columna y el tipo de datos de la columna es un número entero. Entonces sabemos que se utilizan 4 bytes para almacenar el valor entero. Pero 125 se puede almacenar en 1 byte porque 1 byte puede almacenar valores de 0 a 255. Entonces, 125 se puede almacenar como un pequeño int , de modo que se pueden guardar 3 bytes.
- Carácter y Nchar los tipos de datos se almacenan como tipos de datos de longitud variable. Por ejemplo, "SQL" se almacena en un char (20) tipo columna. Pero después de la compresión, solo se utilizarán 3 bytes. Después de la compresión de datos, no se almacena ningún carácter en blanco con este tipo de datos.
- Se reducen los metadatos del registro.
- Los valores NULL y 0 están optimizados y no se consume espacio.
Compresión de página
La compresión de página es un nivel avanzado de compresión de datos. De forma predeterminada, una compresión de página también implementa la compresión de nivel de fila. La compresión de página se clasifica en dos tipos
- Compresión de prefijos y
- Compresión de diccionario.
Compresión de prefijo
En la compresión de prefijos para cada página, para cada columna de la página, se recupera un valor común de todas las filas y se almacena debajo del encabezado de cada columna. Ahora, en cada fila, se almacena una referencia a ese valor en lugar de un valor común.
Compresión de diccionario
La compresión de diccionario es similar a la compresión de prefijo, pero los valores comunes se recuperan de todas las columnas y se almacenan en la segunda fila después del encabezado. La compresión del diccionario busca coincidencias de valores exactos en todas las columnas y filas de cada página.
Podemos realizar una compresión a nivel de fila y página para los siguientes objetos de la base de datos.
- Una tabla almacenada en un montón.
- Una tabla completa almacenada como un índice agrupado.
- Vista indexada.
- Índice no agrupado.
- Índices y tablas particionados.
Demostración
Los WideWorldImporters La base de datos se utiliza durante toda la demostración. Además, un DW en tiempo real la base de datos se considera para la operación de compresión.
Veamos los pasos en detalle:
1. Para ver la configuración de compresión de los objetos en la base de datos, ejecute el siguiente T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
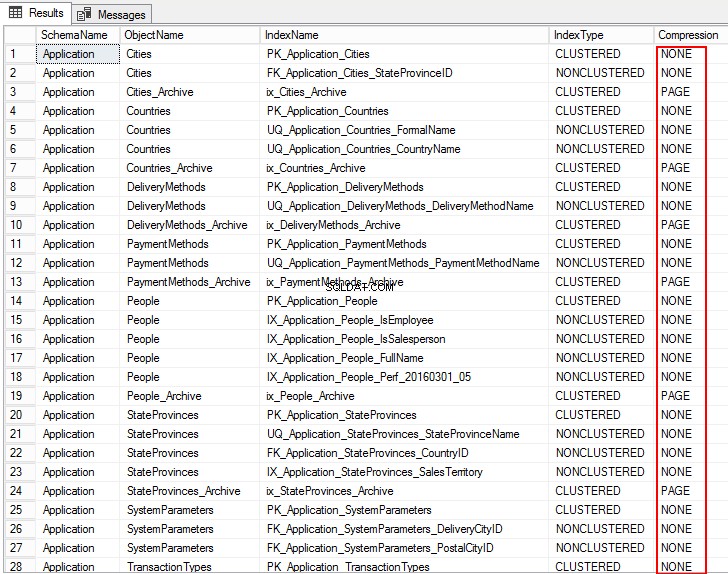
El siguiente resultado muestra el tipo de compresión como PÁGINA, FILA y para varias tablas es NINGUNO. Esto significa que no está configurado para la compresión.
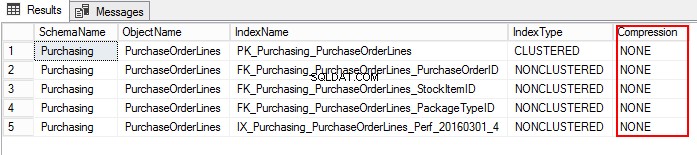
2. Para estimar la compresión, ejecute el siguiente procedimiento almacenado del sistema sp_estimate_data_compression_savings . En este caso, el procedimiento almacenado se ejecuta en las tablas de Líneas de pedidos de compra.
3. Averigüemos la configuración de compresión de PurchaseOrderLines ejecutando el siguiente T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

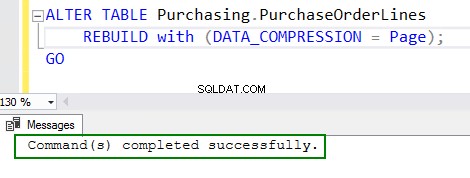
4. Habilite la compresión ejecutando el comando ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
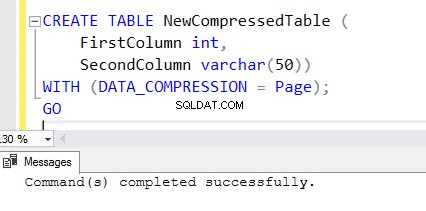
5. Para crear una nueva tabla con la función de compresión habilitada, agregue la cláusula WITH al final de la instrucción CREATE TABLE. Puede ver la declaración CREATE TABLE a continuación utilizada para crear NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Datos sobre la compresión de datos
Repasemos parte de la información real sobre la compresión
- La compresión no se puede aplicar a las tablas del sistema
- No se puede habilitar la compresión de una tabla cuando el tamaño de la fila supera los 8060 bytes.
- Los datos comprimidos se almacenan en caché en el grupo de búfer; significa tiempos de respuesta más rápidos
- Habilitar la compresión puede hacer que cambien los planes de consulta porque los datos se almacenan utilizando un número diferente de páginas y de filas por página.
- Los índices no agrupados no heredan la propiedad de compresión
- Cuando se crea un índice agrupado en un montón, el índice agrupado hereda el estado de compresión del montón a menos que se especifique un estado de compresión alternativo.
- Las compresiones a nivel de FILA y PÁGINA se pueden habilitar y deshabilitar, sin conexión o en línea.
- Si se cambia la configuración del montón, se reconstruirán todos los índices no agrupados.
- Los requisitos de espacio en disco para habilitar o deshabilitar la compresión de filas o páginas son los mismos que para crear o reconstruir un índice.
- Cuando las particiones se dividen mediante la instrucción ALTER PARTITION, ambas particiones heredan el atributo de compresión de datos de la partición original.
- Cuando se fusionan dos particiones, la partición resultante hereda el atributo de compresión de datos de la partición de destino.
- Para cambiar una partición, la propiedad de compresión de datos de la partición debe coincidir con la propiedad de compresión de la tabla.
- Las tablas y los índices de almacén de columnas siempre se almacenan con la compresión de almacén de columnas.
- La compresión de datos es incompatible con las columnas dispersas, por lo que la tabla no se puede comprimir.
Escenario en tiempo real
Veamos la técnica de compresión de datos y comprendamos los parámetros clave de la compresión de datos.
Para verificar el espacio utilizado por cada tabla, ejecute el siguiente T-SQL. El resultado de la consulta nos brinda información detallada sobre el uso de cada tabla. Este sería el factor decisivo para la implementación de la compresión de datos.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
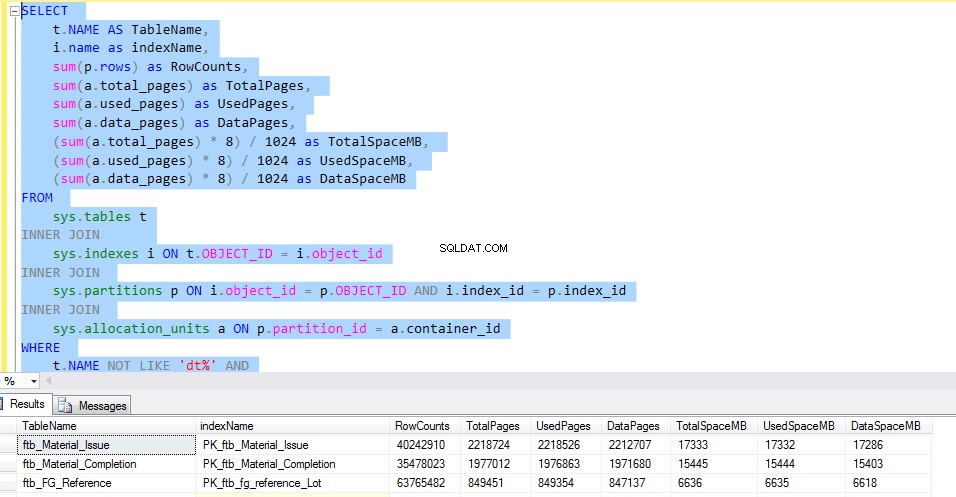
Consideremos el ftb_material_Issue tabla de hechos La tabla de hechos tiene tipos de datos BIGINT numéricos.
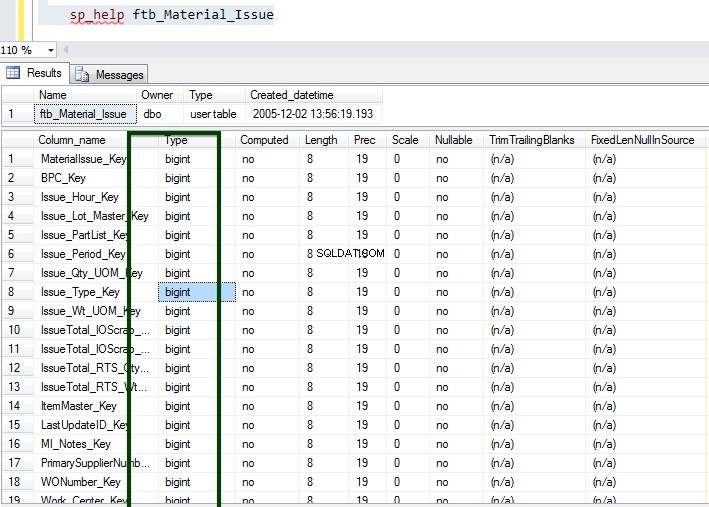
Ahora, ejecute el procedimiento almacenado sp_spaceused para comprender los detalles de la tabla. Puede obtener más información sobre el comando sp_spaceused aquí.
Habilite la compresión a nivel de tabla ejecutando el siguiente T-SQL. El siguiente T-SQL se ejecutó en el servidor y tomó 34 minutos y 14 segundos comprimir la página a nivel de tabla.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
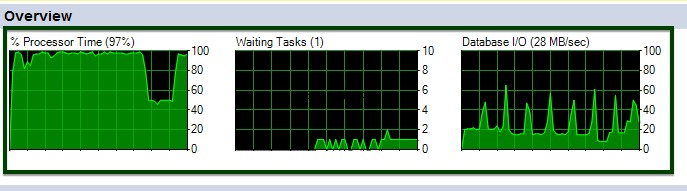
Puede ver las fluctuaciones de CPU y E/S durante la ejecución del comando de tabla ALTER.
Ahora, hagamos la comparación de compresión de datos Antes v/s Después. El tamaño de la tabla, de unos 45 GB, se reduce a unos 15 GB.
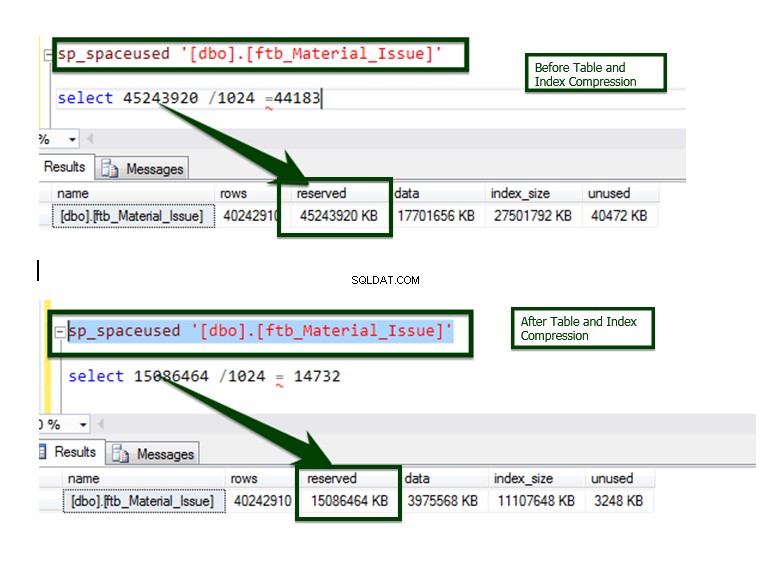
El proceso se implementa en la mayoría de los objetos mediante un script automatizado y este es el resultado final de la comparación.
Comparación de datos entre Antes y Después de la operación de compresión del índice.

Resumen
La compresión de datos es una técnica muy efectiva para reducir el tamaño de los datos; los datos reducidos requieren menos procesos de E/S. Agregar compresión a la base de datos aumenta la carga de los requisitos de la CPU. Deberá asegurarse de tener la capacidad de procesamiento disponible para adaptarse a estos cambios de manera eficiente. Por lo tanto, es mejor investigar un poco primero y ver los tipos de ganancias que se pueden esperar antes de aplicar las modificaciones para habilitar la compresión de datos. Es muy beneficioso en la configuración de la base de datos en la nube donde el costo está involucrado.
Realice las compresiones en etapas (no las haga todas a la vez) y comprima durante los períodos de tiempo de baja actividad. La compresión de datos y la compresión de respaldo coexisten muy bien y pueden generar ahorros de espacio de almacenamiento adicional, así que adelante y disfrute.
La compresión no solo reduce el tamaño de los archivos físicos, sino que también reduce la E/S del disco, lo que puede mejorar en gran medida el rendimiento de muchas aplicaciones de bases de datos, junto con las copias de seguridad de bases de datos.
Decidir implementar la compresión es más fácil si conocemos la infraestructura subyacente y los requisitos comerciales. Definitivamente podemos usar el procedimiento del sistema disponible para comprender y estimar los ahorros de compresión. Este procedimiento almacenado no proporciona ningún detalle que le indique cómo afectará positiva o negativamente la compresión a su sistema. Es evidente que hay ventajas y desventajas para cualquier tipo de compresión. Si tiene los mismos patrones de grandes cantidades de datos, entonces la compresión es la clave para ahorrar espacio. Con el aumento de la potencia de la CPU y cada sistema vinculado a estructuras de múltiples núcleos, la compresión puede adaptarse a muchos sistemas. Recomendaría probar sus sistemas. Realice pruebas para garantizar que el rendimiento no se vea afectado negativamente. Si un índice tiene muchas actualizaciones y eliminaciones, el costo de la CPU para comprimir y descomprimir los datos puede superar los ahorros de E/S y RAM de la compresión de datos. No todas las bases de datos o tablas serán automáticamente buenas candidatas para aplicar compresión, por lo que es mejor investigar un poco primero para ver los tipos de ganancias que se pueden esperar antes de aplicar las modificaciones para habilitar la compresión de datos en sus bases de datos. Debe probar la compresión para ver si funciona bien en su entorno, ya que es posible que no funcione bien en bases de datos con muchas inserciones.
Referencias
Ediciones y funciones admitidas de SQL Server 2016
Compresión de datos
Implementación de compresión de filas
Implementación de compresión de página