La replicación de bases de datos es la tecnología para distribuir datos desde el servidor principal a los servidores secundarios. La replicación funciona según el concepto maestro-esclavo, donde la base de datos maestra distribuye datos a uno o varios servidores esclavos. La replicación se puede configurar entre varias instancias de SQL Server en el mismo servidor, O se puede configurar entre varios servidores de bases de datos dentro del mismo centro de datos o separados geográficamente.
Hay dos ventajas principales de usar la replicación de SQL Server:
- Al usar la replicación, podemos obtener datos casi en tiempo real que se pueden usar para generar informes. Por ejemplo, cuando desee separar la carga OLTP intensiva de escritura en un servidor y la carga intensiva de lectura en otro servidor, puede configurar la replicación para mantener los datos sincronizados en ambos servidores.
- El segundo beneficio es que puede programar la replicación para que se ejecute en un momento específico. Por ejemplo, si desea que el servidor de informes contenga datos del día completo, puede programar la instantánea de replicación en consecuencia. No necesitamos escribir lógica adicional para manejar los datos actuales.
La replicación ofrece mucha flexibilidad. Usando la replicación, podemos filtrar las filas y también podemos replicar el subconjunto de datos de cualquier tabla. Podemos cambiar los datos replicados o replicar solo actualizar e insertar e ignorar las eliminaciones. También podemos replicar los datos de otro sistema de base de datos como Oracle.
Componentes de la replicación
Hay siete componentes principales de SQL Server Replication. La siguiente es la lista:
- Editor.
- Distribuidor.
- Suscriptor.
- Artículos.
- Publicación.
- Subscripción automática.
- Extraer suscripción.
Los siguientes son los detalles:
Artículos
Un artículo es un objeto de base de datos, como una tabla SQL o un procedimiento almacenado. Como mencioné anteriormente, al usar la replicación, podemos filtrar datos o podemos replicar la columna de la tabla seleccionada, por lo tanto, las columnas o filas de la tabla se consideran artículos.
Publicación
Los artículos no se pueden replicar hasta que se conviertan en parte de la publicación. La publicación es el grupo de los objetos Artículos/Base de datos. También representa el conjunto de datos que SQL Server replicará.
Editor
Publisher contiene una base de datos maestra que tiene los datos que deben publicarse. Determina qué datos se deben distribuir entre todos los suscriptores.
Distribuidor
El distribuidor es el puente entre el editor y el suscriptor. El distribuidor recopila todos los datos publicados y los retiene hasta que los envía a todos los suscriptores. Es un puente entre el editor y el suscriptor. Es compatible con múltiples editores y el concepto de suscriptor. No es obligatorio configurar el distribuidor en una instancia de SQL separada o en un servidor separado. Si no lo configuramos, el editor puede actuar como distribuidor. Las organizaciones que tienen replicación a gran escala pueden configurar el distribuidor en un sistema separado.
Suscriptores
El suscriptor es el final de la fuente o el destino al que se transmitirán los datos o la publicación replicada. En la replicación, hay un editor, puede tener varios suscriptores.
Suscripción automática
En una suscripción push, el editor actualiza los datos al suscriptor. En una suscripción Push, el suscriptor es pasivo. La editorial envía artículos o publicaciones a todos sus suscriptores. Según los requisitos de la organización, al crear el asistente de replicación, en la pantalla, puede seleccionar la suscripción que se utilizará. La replicación de transacciones y la replicación punto a punto utiliza la suscripción Push para mantener la disponibilidad de datos en tiempo real.
Extraer suscripción
En una suscripción Pull, todos los suscriptores solicitan los datos nuevos o actualizados de su editor. En una suscripción pull, podemos controlar qué datos o cambios de datos se necesitan para los suscriptores. Es útil cuando no necesitamos los datos modificados inmediatamente.
Tipos de replicación
SQL Server admite tres tipos de replicación:
- Replicación transaccional.
- Replicación de instantáneas.
- Combinar replicación.
Replicación transaccional
La replicación transaccional, cualquier cambio de esquema, los cambios de datos que se produzcan en la base de datos del editor se replicarán en la base de datos del suscriptor. Cada vez que se realizan operaciones de actualización, eliminación o inserción en la base de datos del editor, se realiza un seguimiento de los cambios y estos cambios se envían a las bases de datos del suscriptor. La replicación transaccional envía solo una cantidad limitada de datos a través de una red. Además, los cambios son casi en tiempo real, por lo que se pueden usar para configurar el sitio de DR o para escalar las operaciones de generación de informes. La replicación transaccional es ideal para las siguientes situaciones:
- Cuando desee configurar un sistema en el que los cambios realizados en el editor se apliquen a los suscriptores de inmediato.
- El editor tiene alto bajo INSERTAR, ACTUALIZAR y ELIMINAR.
- Cuando desee configurar un significado de replicación heterogéneo, editor o suscriptores para bases de datos que no sean de SQL Server, como Oracle.
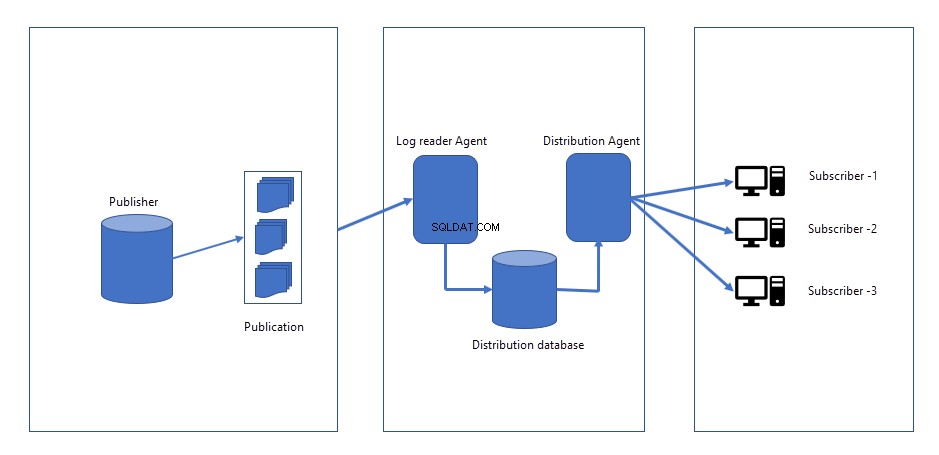
Cuando se realizan cambios en la base de datos del editor, los cambios se registran en un archivo de registro en la base de datos del editor. Sitio de distribuidor/editor, se crearán dos puestos de trabajo.
- Agente de instantáneas :El trabajo del agente de instantáneas genera la instantánea del esquema, los datos de los objetos que queremos replicar o publicar. Los archivos de la instantánea se pueden guardar en el servidor de Publisher o en la ubicación de la red. Cuando iniciamos la replicación por primera vez, crea una instantánea y la aplica a todos los suscriptores. El agente de instantáneas permanece inactivo hasta que se activa manualmente o se programa para ejecutarse en un momento específico.
- Agente de lectura de registros :El trabajo del agente de lectura de registros se ejecuta continuamente. Lee los cambios (INSERTAR, ACTUALIZAR y ELIMINAR) del registro de transacciones de la base de datos del editor y los envía a un agente de distribución.
- Agente de distribución :una vez que se recuperan los cambios del agente de lectura de registros, el agente de distribución envía todos los cambios a los suscriptores.
Cuando configuramos la replicación transaccional, realiza las siguientes actividades
- Se inicia tomando la Primera instantánea de los datos de publicación y los objetos de la base de datos y la instantánea aplicada a los suscriptores.
- El agente lector de registros supervisa continuamente el T-Log del editor y, si se producen cambios, los envía al distribuidor o directamente a los suscriptores.
La siguiente imagen representa cómo funciona la replicación transaccional:
- La replicación de transacciones se puede usar como un servidor SQL en espera, o se puede usar para equilibrar la carga o separar el sistema de informes y el sistema OLTP.
- El servidor del editor replica los datos en el servidor del suscriptor con baja latencia.
- Usando la replicación transaccional, se puede implementar la replicación a nivel de objeto.
- La replicación transaccional se puede aplicar cuando tiene menos datos para proteger y debe tener un plan de recuperación de datos rápido.
Desventajas:
- Una vez que se establece la replicación, los cambios de esquema en el publicador no se aplican en el servidor del suscriptor. Debemos realizar esos cambios manualmente generando una nueva instantánea y aplicándola a los suscriptores.
- Si cambiamos los servidores, debemos reconfigurar la replicación.
- Si se utiliza la replicación transaccional como una configuración de recuperación ante desastres, tenemos que realizar la conmutación por error manualmente.
Replicación de instantáneas
La replicación de instantáneas genera una imagen/instantánea completa de la publicación en un horario definido y envía los archivos de instantáneas a los suscriptores. Cuando se produce la replicación de instantáneas, los datos de destino se reemplazarán con una nueva instantánea. La replicación de instantáneas es la mejor opción cuando los datos son menos volátiles. Por ejemplo, las tablas maestras como City, Zipcode, Pincode son las mejores candidatas para la replicación de instantáneas.
Al configurar la replicación de instantáneas, se definen los siguientes componentes importantes:
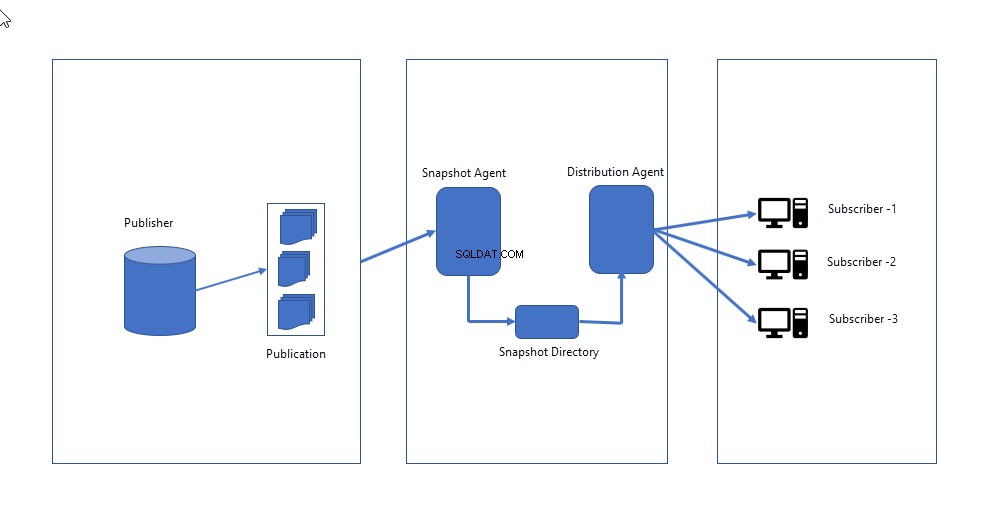
- Agente de instantáneas :Crea una imagen completa de esquema y datos definidos en publicación y la envía al distribuidor. El agente de instantáneas permanece inactivo hasta que se activa manualmente O se programa para ejecutarse en un momento específico.
- Agente distribuidor :envía los archivos de instantáneas a los suscriptores y aplica el esquema y los datos reemplazando el existente.
La replicación de instantáneas realiza las siguientes actividades:
- En la programación definida, el agente de instantáneas coloca un bloqueo compartido en el esquema y los datos que se publicarán.
- Instantánea completa de los datos publicados copiados al final del distribuidor. El agente de instantáneas crea tres archivos
- Archivo en el esquema de base de datos creado de los datos publicados.
- Archivo BCP para exportar datos dentro de tablas SQL
- Archivos de índice para exportar datos de índice.
- Una vez que se crean los archivos, el agente de instantáneas libera los bloqueos compartidos en los datos y datos publicados.
- Los agentes distribuidores inician y reemplazan el esquema y los datos del suscriptor mediante archivos creados por el agente de instantáneas.
La siguiente imagen ilustra cómo funciona la replicación de instantáneas.
Ventajas
- La replicación de instantáneas es muy sencilla de configurar. Si los datos no se cambian con frecuencia, la replicación de instantáneas es una opción muy adecuada.
- Puedes controlar cuándo enviar datos. Por ejemplo, una tabla maestra que tiene un gran volumen de datos, pero cambia con menos frecuencia de la que puede replicar los datos cuando el tráfico es bajo.
Desventajas
- La instantánea generada por el agente de instantáneas contiene datos publicados modificados y sin cambios, por lo que la instantánea transmitida a través de la red puede producir latencia e impactar en otras operaciones.
- A medida que aumentan los datos, aumenta el tamaño de la instantánea y lleva más tiempo crear y distribuir la instantánea a los suscriptores.
Combinar replicación
La replicación de mezcla se puede usar cuando necesitamos administrar cambios en varios servidores y estos cambios deben consolidarse.
Cuando configuramos la replicación de mezcla, se crearán los siguientes componentes:
- Agente de instantáneas :el agente de instantáneas genera la primera instantánea de los datos de publicación y los objetos de la base de datos. Una vez que se crea la instantánea, se distribuirá a todos los suscriptores.
- Agente de fusión :El agente de fusión es responsable de resolver los conflictos entre el editor y los suscriptores. Cualquier conflicto se resuelve a través del agente de fusión que utiliza la resolución de conflictos. Dependiendo de cómo haya configurado la resolución de conflictos, los conflictos los resuelve el agente de combinación.
Cuando configuramos la replicación de mezcla, realiza las siguientes actividades:
- Se inicia tomando una instantánea de los datos de publicación y los objetos de la base de datos y la instantánea aplicada a los suscriptores.
- Al configurar la replicación de combinación, crea disparadores en el editor y el suscriptor. Los disparadores son responsables de realizar un seguimiento de los cambios posteriores y las modificaciones de la tabla en el editor y los suscriptores.
- Cuando el publicador y los suscriptores se conectan a la red, los cambios de las filas de datos y la modificación del esquema se sincronizarán entre sí. Al fusionar los cambios del publicador y los suscriptores, el agente de fusión resuelve los conflictos según las condiciones definidas en el agente de fusión.
La replicación de combinación se usa en entornos de servidor a cliente y es ideal para las situaciones en las que los suscriptores necesitan recuperar datos del publicador, realizar cambios sin conexión y luego sincronizar los cambios con el publicador y otros suscriptores.
Puede haber situaciones prácticas en las que diferentes editores y suscriptores cambien la misma fila. En ese momento, el agente de combinación observará qué resolución de conflictos está definida y realizará los cambios correspondientes.
SQL Server identifica de manera única una columna mediante un identificador único global para cada fila en una tabla publicada. Si la tabla ya tiene una columna de identificador único, entonces SQL Server usa automáticamente esa columna. De lo contrario, agregará una columna de rowguid en la tabla y creará un índice basado en la columna.
Los activadores se crearán en las tablas publicadas tanto en los editores como en los suscriptores. Se utilizan para realizar un seguimiento de los cambios en función de los cambios de fila o columna.
La siguiente imagen ilustra cómo funciona la replicación de combinación:
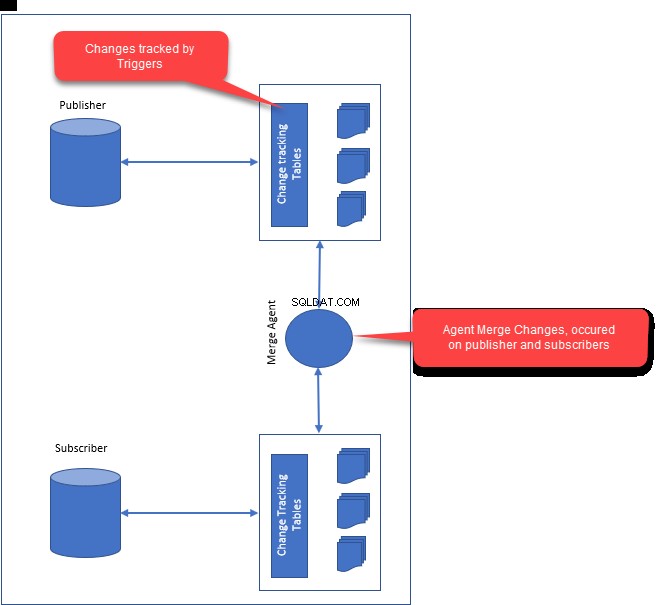
- Esta es la única forma de gestionar la consolidación de cambios en varios datos del servidor.
Desventajas:
- Se necesita mucho tiempo para replicar y sincronizar ambos extremos.
- Hay poca coherencia ya que se deben sincronizar muchas partes.
- Puede haber conflictos al fusionar la replicación si las mismas filas se ven afectadas en más de un suscriptor y editor. Se puede solucionar mediante la resolución de conflictos, pero hace que la configuración de la replicación sea más complicada.
Código T-SQL para revisar la configuración de replicación
Configuré la replicación de instantáneas y la replicación transaccional en dos instancias de mi máquina. Mediante la gestión dinámica de SQL (DMV), podemos comprobar la configuración de la replicación. Para revisar la configuración de la replicación podemos usar código T-SQL. El código de script completa lo siguiente:
- Nombre de la base de datos de suscriptores.
- Nombre del editor.
- Tipo de suscripción.
- Base de datos de editores.
- Nombre del agente de replicación.
A continuación se muestra el guión:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
El siguiente es el resultado:

Resumen
En este artículo, he explicado:
- El fundamento y los beneficios de la replicación y sus componentes.
- Replicación transaccional.
- Replicación de instantáneas.
- Combinar replicación.