El enfoque de este artículo será la utilización de JOIN. Comenzaremos hablando un poco sobre cómo se van a realizar los JOIN y por qué necesita JOIN datos. Luego, veremos los tipos de JOIN que tenemos disponibles y cómo usarlos.
ÚNETE A LO BÁSICO
Los JOIN en TSQL generalmente se realizarán en la línea FROM.
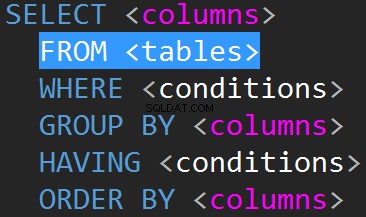
Antes de llegar a cualquier otra cosa, la gran pregunta real es:"¿Por qué tenemos que hacer JOIN y cómo vamos a realizar realmente nuestros JOIN?"
Resulta que cada base de datos con la que trabajamos tendrá sus datos divididos en varias tablas. Hay muchas razones diferentes para esto:
- Mantener la integridad de los datos
- Ahorro de espacio almacenado
- Editar datos más rápido
- Hacer consultas más flexibles
Por lo tanto, cada base de datos con la que vaya a trabajar necesitará que los datos se unan para que realmente tengan sentido.
Por ejemplo, tiene tablas separadas para pedidos y para clientes. La pregunta que se convierte en:"¿Cómo conectamos realmente todos los datos?" Eso es exactamente lo que van a hacer los JOIN.
CÓMO FUNCIONAN LAS UNIONES
Imagine el caso, cuando tenemos dos mesas separadas y esas mesas se unirán creando una costura.
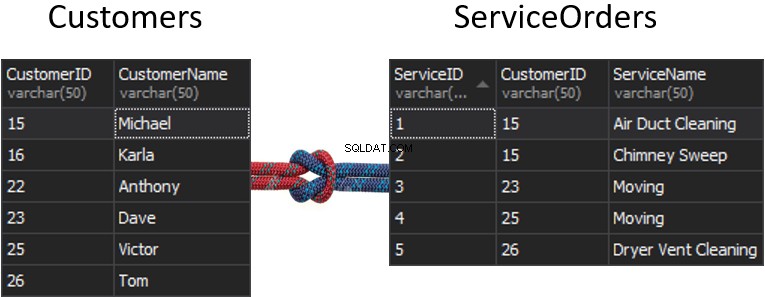
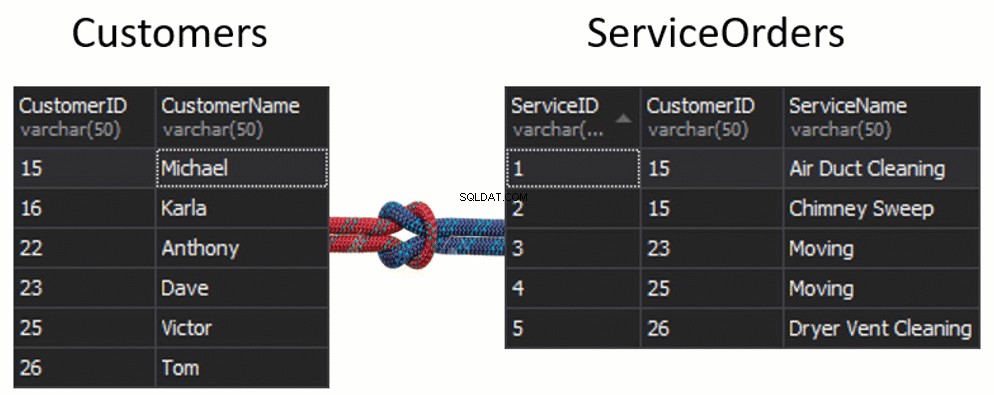
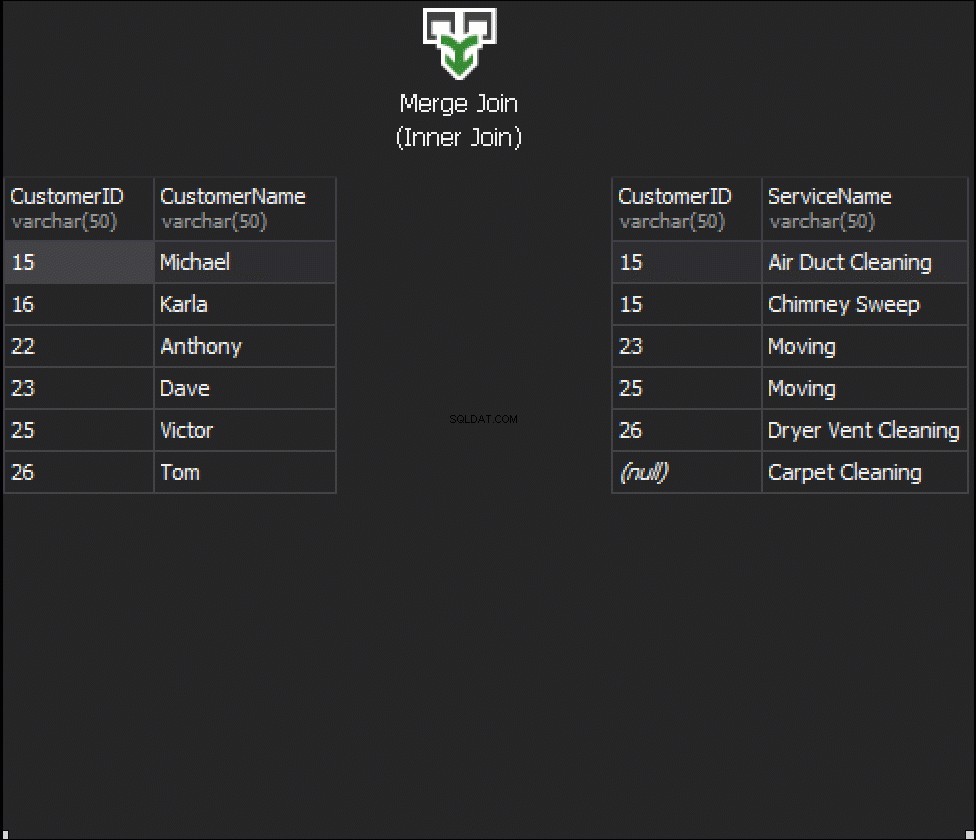
¿Qué va a pasar con la costura, si obtenemos una columna de cada tabla que se usará para hacer coincidir, y eso determinará qué filas se devolverán o no? Por ejemplo, tenemos Clientes a la izquierda y Pedidos de servicio a la derecha. Si queremos obtener todos los clientes y sus pedidos, debemos UNIR estas dos tablas. Para esto, debemos elegir una columna que actuará como una costura y, obviamente, por supuesto, la columna que usaremos es CustomerID.
Por cierto, el CustomerID se conoce como Clave principal para la tabla de la izquierda, que identifica de forma única cada fila dentro de la tabla Clientes.
En la tabla ServiceOrders, también tenemos la columna CustomerID, que se conoce como Foreign Key . Una clave externa es simplemente una columna que está diseñada para apuntar a otra tabla. En nuestro caso, apunta de nuevo a la tabla Clientes. Por lo tanto, así es como vamos a reunir todos esos datos proporcionando esa unión.
En estas tablas, tenemos las siguientes coincidencias:2 órdenes de 15 y 1 orden de 23, 25 y 26. 16 y 22 quedan fuera.
Una cosa importante a tener en cuenta aquí es que podemos UNIRNOS a varias mesas . De hecho, es bastante común UNIR varias tablas para obtener cualquier tipo de información. Si echa un vistazo a la base de datos más común, es posible que tenga que UNIR cuatro, cinco, seis y más tablas solo para obtener la información que está buscando. Tener un diagrama de base de datos será útil.
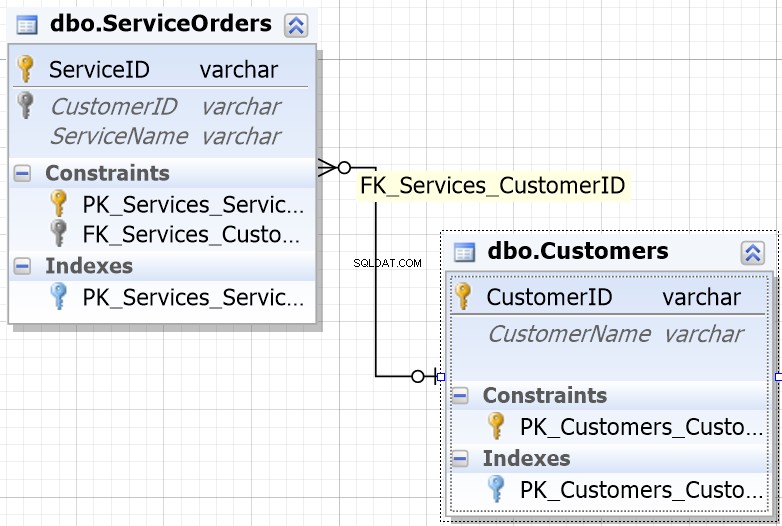
Para ayudarlo en la mayoría de los entornos de bases de datos, notará que las columnas diseñadas para unirse tienen el mismo nombre.
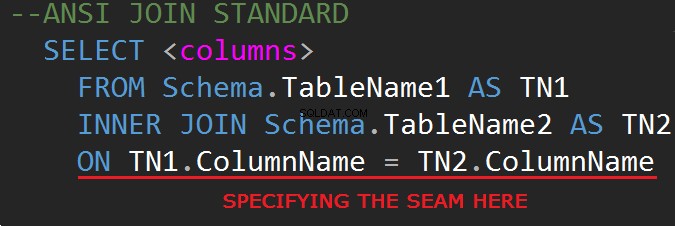
ÚNETE A LA SINTAXIS
La tercera revisión del lenguaje de consulta de bases de datos SQL (SQL-92) regula la sintaxis de JOIN:
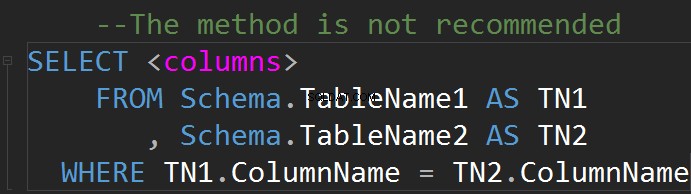
Es posible hacer JOINs en la línea WHERE:
Una relación suele tener una interpretación gráfica sencilla en forma de tabla.
Mejores prácticas y convenciones
- Nombres de tablas de alias.
- Usar nombres de dos partes para las columnas
- Coloque cada JOIN en una línea separada
- Coloque las tablas en un orden lógico
TIPOS DE UNIÓN
SQL Server proporciona los siguientes tipos de JOIN:
- UNIÓN INTERNA
- UNIÓN EXTERNA
- AUTO ÚNETE
- UNIÓN CRUZADA
Para obtener más información sobre el tema, no dude en consultar este artículo sobre los tipos de uniones en SQL Server y aprender lo fácil que es escribir este tipo de consultas con la ayuda de SQL Complete.
UNIÓN INTERNA
El primer tipo de JOIN que podemos querer ejecutar es INNER JOIN. Por lo general, los autores se refieren a este tipo de JOIN de SQL Server como JOIN normal o simple. Simplemente omiten el prefijo INTERIOR. Este tipo de JOIN combina dos tablas y solo devuelve filas de ambos lados que coinciden .
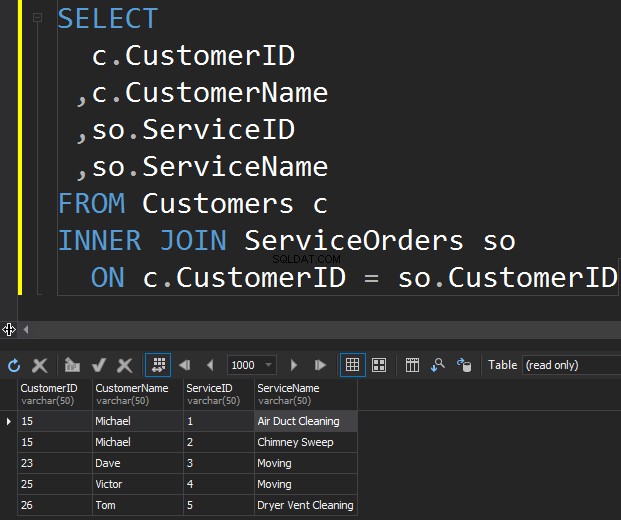
No vemos a Klara y Anthony aquí porque su CustomerID no coincide en ambas tablas. También quiero resaltar el hecho de que la operación JOIN devuelve un cliente cada vez que coincide con el pedido . Hay dos pedidos para Michael y un pedido para Dave, Victor y Tom cada uno.
Resumen:
- INNER JOIN devuelve filas solo cuando hay al menos una fila en ambas tablas que coincide con la condición JOIN.
- INNER JOIN elimina las filas que no coinciden con una fila de la otra tabla
UNIÓN EXTERNA
Los JOIN externos son diferentes porque devuelven filas de tablas o vistas incluso si no coinciden. Este tipo de JOIN es útil si necesita recuperar a todos los clientes que nunca han realizado un pedido. O, por ejemplo, si está buscando un producto que nunca se ha pedido.
La forma en que hacemos nuestros OUTER JOIN es indicando IZQUIERDA o DERECHA o COMPLETA.
No hay diferencias entre las siguientes cláusulas:
- UNIÓN EXTERNA IZQUIERDA =UNIÓN IZQUIERDA
- UNIÓN EXTERNA DERECHA =UNIÓN DERECHA
- UNIÓN EXTERNA COMPLETA =UNIÓN COMPLETA
Sin embargo, recomendaría escribir la cláusula completa porque hace que el código sea más legible.
Uso de la UNIÓN EXTERNA IZQUIERDA
No hay diferencia entre IZQUIERDA o DERECHA, excepto el hecho de que simplemente señalamos la tabla de la que queremos obtener las filas adicionales. En el siguiente ejemplo, enumeramos los clientes y sus pedidos. Utilizamos la IZQUIERDA para obtener todos los clientes que nunca han realizado pedidos. Le pedimos a SQL Server que nos proporcione filas adicionales de la tabla de la izquierda.
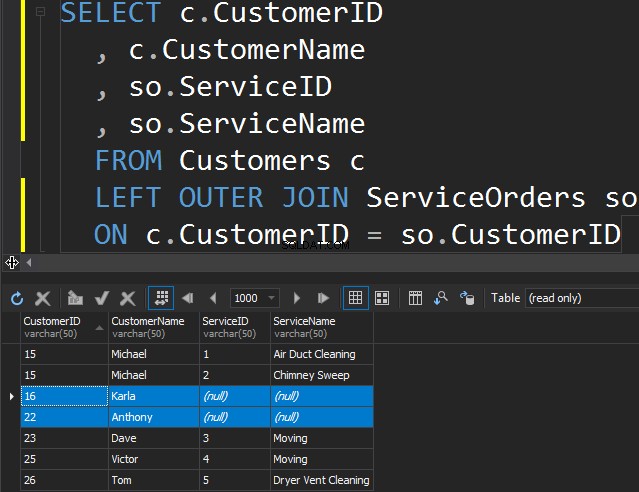
Tenga en cuenta que Karla y Anthony no han realizado ningún pedido y, como resultado, obtenemos valores NULL para ServiceName y ServiceID. SQL Server no sabe qué colocar allí y coloca valores NULL.
Uso de la UNIÓN EXTERNA DERECHA
Para obtener el servicio menos popular de la tabla ServiceOrders, debemos usar la dirección CORRECTA.
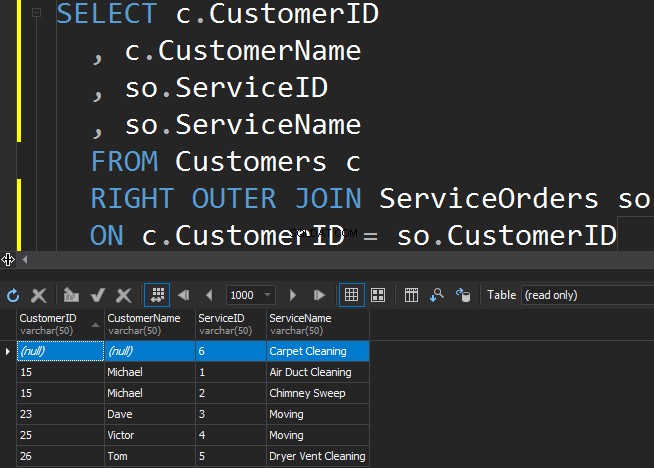
Vemos que en este caso, SQL Server devolvió filas adicionales de la tabla derecha y nunca se ordenó el servicio de limpieza de alfombras.
Uso de la UNIÓN EXTERNA COMPLETA
Este tipo de JOIN le permite obtener la información que no coincide al incluir filas que no coinciden de ambas tablas.
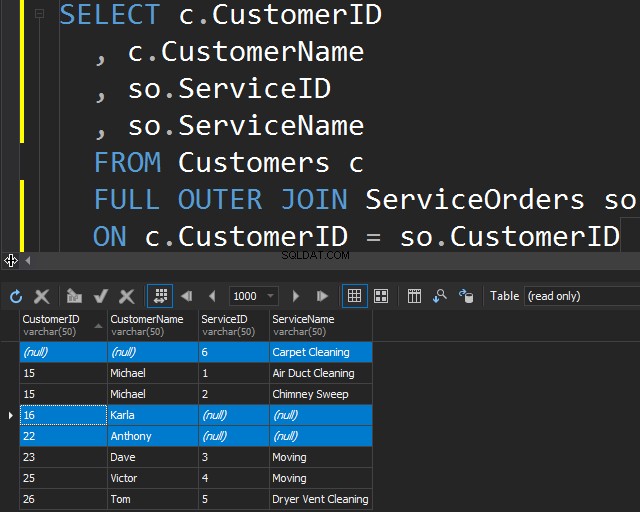
Esto también puede ser útil si necesita hacer una limpieza de datos.
Resumen:
UNIÓN EXTERNA COMPLETA
- Devuelve filas de ambas tablas incluso si no coinciden con la instrucción JOIN
IZQUIERDA o DERECHA
- No hay diferencia excepto en el orden de las tablas en la cláusula FROM
- Puntos de dirección en una tabla para recuperar filas que no coinciden
AUTO UNIÓN
El siguiente tipo de JOIN que tenemos es AUTO JOIN. Este es probablemente el segundo tipo menos común de JOIN que ejecutará. UN SELF JOIN es cuando estás uniendo una mesa sobre sí misma. En términos generales, esto es una señal de un mal diseño. Para usar la misma tabla dos veces en una sola consulta, la tabla debe tener un alias. El alias ayuda al procesador de consultas a identificar si las columnas deben presentar datos del lado derecho o izquierdo. Además, debe eliminar las filas que marchan solas. Esto normalmente se hace con una unión no equitativa.
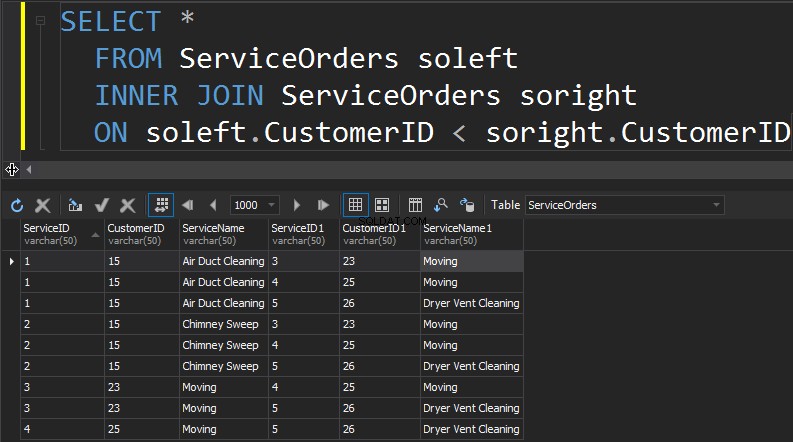
Resumen:
- ÚNETE una tabla a sí misma
- Generalmente, un signo de diseño y normalización deficientes
- Las tablas deben tener alias
- Necesita filtrar las filas que coinciden
UNIONES CRUZADAS
Este tipo de JOIN no tiene ON declaración. Cada fila de cada tabla va a coincidir. Esto también se conoce como producto cartesiano (en caso de que CROSS JOIN no tenga una cláusula WHERE). Difícilmente usará este tipo JOIN en escenarios del mundo real, sin embargo, es una buena forma de generar datos de prueba.
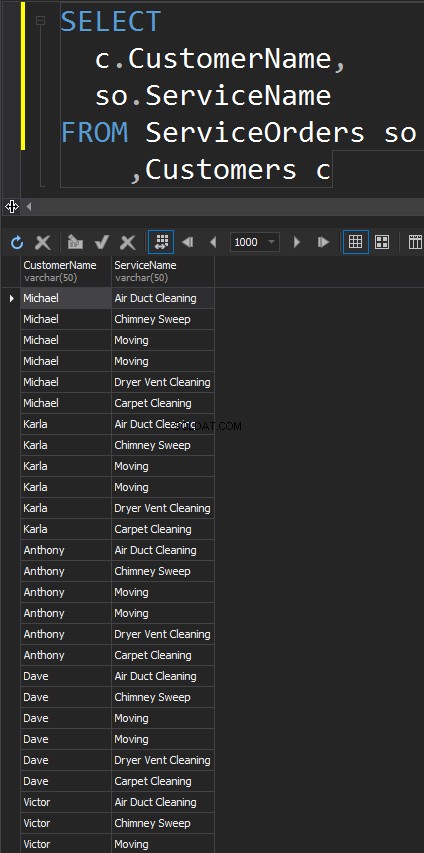
El resultado es un conjunto de datos, donde el número de filas en la tabla de la izquierda se multiplica por el número de filas en la tabla de la derecha. Eventualmente, vemos que cada cliente coincide con cada servicio.
Obtenemos el mismo resultado cuando usamos la cláusula CROSS JOIN explícitamente.
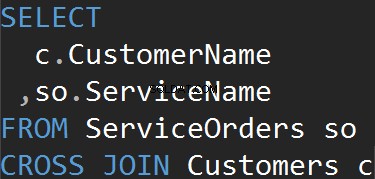
Resumen:
- Todas las filas coinciden de cada tabla
- Sin declaración ON
- Se puede usar para generar datos de prueba
ALGORITMOS DE UNIÓN
En la primera parte del artículo, hemos discutido lógico Los operadores JOIN que usa SQL Server durante el análisis y enlace de consultas. Ellos son:
- UNIÓN INTERNA
- UNIÓN EXTERNA
- UNIÓN CRUZADA
Los operadores lógicos son conceptuales y se diferencian de los físicos Uniones. Hablando de otra manera, los JOIN lógicos no se unen realmente columnas de la tabla en particular. Un único JOIN lógico puede corresponder a muchos JOIN físicos. SQL Server reemplaza los JOIN lógicos por JOIN físicos durante la optimización. SQL Server tiene los siguientes operadores físicos JOIN:
- BUCLE ANIDADO
- COMBINAR
- HASH
Un usuario no escribe ni usa estos tipos de JOINS. Son parte del motor de SQL Server y SQL Server los usa internamente para implementar JOIN lógicos. Cuando explora el plan de ejecución, puede notar que SQL Server reemplaza los operadores lógicos JOIN con uno de los tres operadores físicos.
Unión de bucle anidado
Empecemos por el operador más simple, que es Nested Loop. El algoritmo compara cada fila de una tabla (tabla externa) con cada fila de la otra tabla (tabla interna) en busca de filas que cumplan con el predicado JOIN.
El siguiente pseudocódigo describe el algoritmo de bucle de unión anidado interno:

El siguiente pseudocódigo describe el algoritmo de bucle de combinación anidado externo:
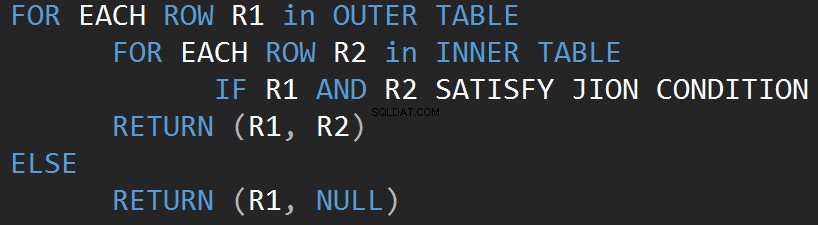
El tamaño de la entrada afecta directamente el costo del algoritmo. La entrada crece el costo crece también. Este tipo de algoritmo JOIN es eficiente en el caso de una entrada pequeña. SQL Server estima un predicado JOIN para cada fila en ambas entradas.
Considere la siguiente consulta como ejemplo, que obtiene clientes y sus pedidos.
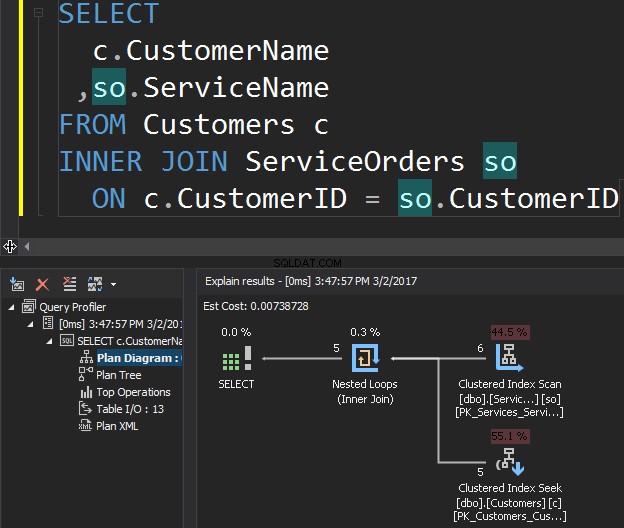
El operador de escaneo de índice agrupado es la entrada externa y la búsqueda de índice agrupado es la entrada interna . El operador Nested Loop en realidad encuentra coincidencias. El operador busca cada registro en la entrada externa y encuentra filas coincidentes en la entrada interna. SQL Server ejecuta la operación de escaneo de índice agrupado (entrada externa) solo una vez para obtener todos los registros relevantes. La búsqueda de índice agrupado se ejecuta para cada registro desde la entrada externa. Para confirmar esto, desplace el cursor hasta el icono del operador y examine la información sobre herramientas.
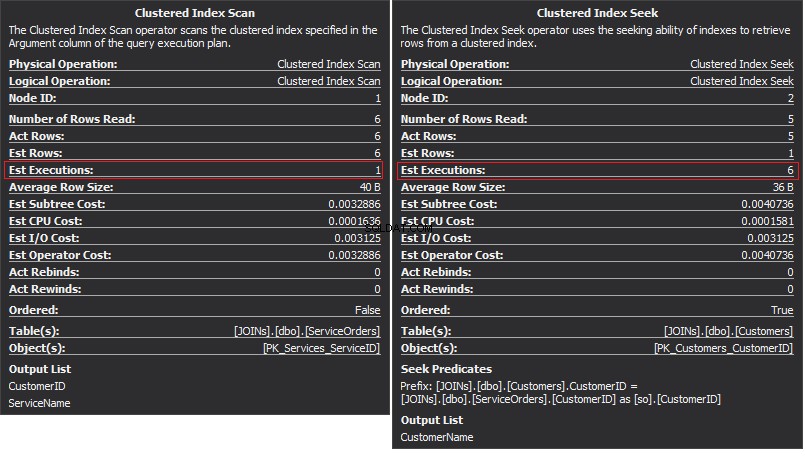
Hablemos de la complejidad. Supongamos que N es el número de fila para la salida externa. M es el número de fila total en SalesOrders mesa. Por lo tanto, la complejidad de la consulta es O(NLogM) donde LogM es la complejidad de cada búsqueda en la entrada interna. El optimizador seleccionará este operador cada vez que la entrada externa sea pequeña y la entrada interna contenga un índice en la columna que actúa como la costura. Por lo tanto, los índices y las estadísticas son esenciales para este tipo JOIN, de lo contrario, SQL Server puede pensar accidentalmente que no hay tantas filas en una de las entradas. Es mejor realizar un escaneo de tabla en lugar de realizar Index Seek 100K veces. Especialmente cuando el tamaño de la entrada interna es más de 100K.
Resumen:
Bucles anidados
- Complejidad:O(NlogM)
- Se aplica generalmente cuando una mesa es pequeña
- La tabla más grande contiene un índice que permite buscarla usando la clave de combinación
Fusionar Unión
Algunos desarrolladores no entienden completamente los JOIN de Hash y Merge y con frecuencia los asocian con consultas de bajo rendimiento.
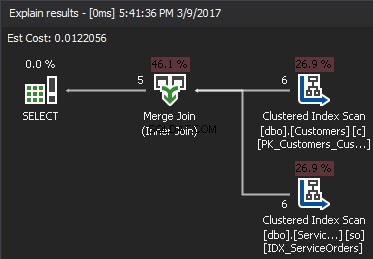
A diferencia de Nested Loop que acepta cualquier predicado JOIN, Merge Join requiere al menos una equijoin. Además, ambas entradas deben ordenarse en las teclas JOIN.
El pseudocódigo para el algoritmo MERGE JOIN:
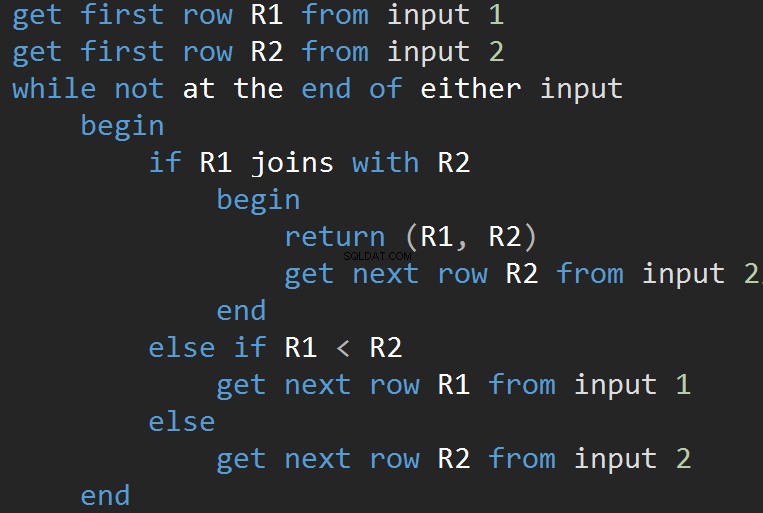
El algoritmo compara dos entradas ordenadas. Una fila a la vez. En caso de que haya una igualdad entre dos filas, el algoritmo genera unir filas y continuar. Si no, el algoritmo descarta la menor de las dos entradas y continúa. A diferencia de Nested Loop, el costo aquí es proporcional a la suma del número de filas de entrada. En términos de complejidad:O(N+M). Por lo tanto, este tipo de JOIN suele ser mejor para grandes entradas.
La siguiente animación demuestra cómo el algoritmo MERGE JOIN realmente une las filas de la tabla.
Resumen
- Complejidad:O(N+M)
- Ambas entradas deben ordenarse en la clave de combinación
- Se utiliza un operador de igualdad
- Excelente para mesas grandes
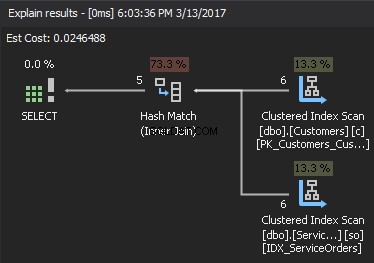
Unión hash
Hash Join es ideal para tablas grandes sin índice utilizable. En el primer paso:fase de construcción el algoritmo crea un índice hash en memoria en la entrada del lado izquierdo. El segundo paso se denomina fase de sondeo. . El algoritmo pasa por la entrada del lado derecho y encuentra coincidencias usando el índice creado durante la fase de construcción. A decir verdad, no es una buena señal que el optimizador elija este tipo de algoritmo JOIN.
Hay dos conceptos importantes que subyacen a este tipo de JOIN:función hash y tabla hash.
Una función hash es cualquier función que se puede usar para mapear datos de tamaño variable a datos de tamaño fijo.
Una tabla hash es una estructura de datos utilizada para implementar una matriz asociativa, una estructura que puede asignar claves a valores. Una tabla hash utiliza una función hash para calcular un índice en una matriz de cubos o ranuras, a partir de la cual se puede encontrar el valor deseado.
Según las estadísticas disponibles, SQL Server elige la entrada más pequeña como entrada de compilación y la usa para crear una tabla hash en la memoria. Si no hay suficiente memoria, SQL Server usa espacio de disco físico en TempDB. Una vez que se crea la tabla hash, SQL Server obtiene los datos de la entrada de la sonda (tabla más grande) y los compara con la tabla hash mediante una función de coincidencia hash. Como resultado, devuelve filas coincidentes.
Si observamos el plan de ejecución, el elemento superior derecho es la entrada de compilación , y el elemento inferior derecho es la entrada de sondeo . En caso de que ambos insumos sean extremadamente grandes, el costo es demasiado alto.
Para estimar la complejidad, asuma lo siguiente:
hc
hm
N – mesa más pequeña
M – mesa más grande
La complejidad será:O(N*hc
El optimizador usa estadísticas para determinar la cardinalidad del valor. Luego crea dinámicamente una función hash que divide los datos en muchos cubos con tamaños iguales. A menudo es difícil estimar la complejidad del proceso de creación de tablas hash, así como la complejidad de cada coincidencia de hash debido a la naturaleza dinámica. El plan de ejecución puede incluso mostrar estimaciones incorrectas porque el optimizador realiza todas estas operaciones dinámicas durante el tiempo de ejecución. En algunos casos, el plan de ejecución puede mostrar que Nested Loop es más costoso que Hash Join, pero de hecho, Hash Join se ejecuta más lentamente debido a una estimación de costo incorrecta.
Resumen
- Complejidad:O(N*hc +M*hm +J)
- Tipo de unión de último recurso
- Utiliza una tabla hash y una función de coincidencia hash dinámica para hacer coincidir las filas
Productos útiles:
SQL Complete:escribe, embellece, refactoriza tu código fácilmente y aumenta tu productividad.