Presentado por primera vez en SQL Server 2017 Enterprise Edition, una unión adaptable permite una transición en tiempo de ejecución de una combinación hash en modo por lotes a una combinación indexada de bucles anidados correlacionados en modo fila (aplicar) en tiempo de ejecución. Para abreviar, me referiré a una "unión indexada de bucles anidados correlacionados" como aplicar a lo largo del resto de este artículo. Si necesita un repaso sobre la diferencia entre bucles anidados y aplicar, consulte mi artículo anterior.
La transición de una combinación adaptable de una combinación hash a la aplicación en tiempo de ejecución depende de un valor denominado Filas de umbral adaptable. en Unión adaptable operador del plan de ejecución. Este artículo muestra cómo funciona una unión adaptable, incluye detalles del cálculo del umbral y cubre las implicaciones de algunas de las elecciones de diseño realizadas.
Introducción
Una cosa que quiero que tenga en cuenta a lo largo de este artículo es una unión adaptable siempre comienza a ejecutarse como una combinación hash en modo por lotes. Esto es cierto incluso si el plan de ejecución indica que la combinación adaptable espera ejecutarse como una aplicación de modo de fila.
Como cualquier combinación hash, una combinación adaptable lee todas las filas disponibles en su entrada de compilación y copia los datos necesarios en una tabla hash. El tipo de modo por lotes de hash join almacena estas filas en un formato optimizado y las divide mediante una o más funciones hash. Una vez que se ha consumido la entrada de compilación, la tabla hash se llena por completo y se particiona, lista para que la unión hash comience a buscar coincidencias en las filas del lado de la sonda.
Este es el punto en el que una unión adaptable toma la decisión de continuar con la unión hash en modo por lotes o aplicar la transición a un modo de fila. Si el número de filas en la tabla hash es menor que el umbral valor, la combinación cambia a una aplicación; de lo contrario, la combinación continúa como una combinación hash al comenzar a leer las filas de la entrada de la sonda.
Si se produce una transición a una combinación de aplicación, el plan de ejecución no vuelve a leer las filas utilizadas para completar la tabla hash para impulsar la operación de aplicación. En su lugar, un componente interno conocido como lector de búfer adaptativo expande las filas ya almacenadas en la tabla hash y las hace disponibles bajo demanda para la entrada externa del operador de aplicación. Hay un costo asociado con el lector de búfer adaptativo, pero es mucho más bajo que el costo de rebobinar completamente la entrada de compilación.
Elegir una unión adaptable
La optimización de consultas implica una o más etapas de exploración lógica e implementación física de alternativas. En cada etapa, cuando el optimizador explora las opciones físicas para una lógica join, podría considerar tanto la combinación hash en modo por lotes como el modo en fila para aplicar alternativas.
Si una de esas opciones de unión física forma parte de la solución más económica encontrada durante la etapa actual, y el otro tipo de combinación puede ofrecer las mismas propiedades lógicas requeridas:el optimizador marca el grupo de combinación lógica como potencialmente adecuado para una unión adaptativa. De lo contrario, la consideración de una combinación adaptable termina aquí (y no se activa ningún evento extendido de combinación adaptable).
El funcionamiento normal del optimizador significa que la solución más barata encontrada solo incluirá una de las opciones de unión física, ya sea hash o apply, cualquiera que tenga el costo estimado más bajo. Lo siguiente que hace el optimizador es construir y costear una nueva implementación del tipo de unión que no era elegido como el más barato.
Dado que la fase de optimización actual ya ha finalizado con una solución más barata encontrada, se realiza una ronda especial de exploración e implementación de un solo grupo para la unión adaptable. Finalmente, el optimizador calcula el umbral adaptativo .
Si alguno de los trabajos anteriores no tiene éxito, el evento extendido adaptive_join_skipped se activa con un motivo.
Si el procesamiento de unión adaptable es exitoso, un Concat El operador se agrega al plan interno por encima del hash y aplica alternativas con el lector de búfer adaptativo y cualquier adaptador de modo por lotes/fila requerido. Recuerde, solo una de las alternativas de combinación se ejecutará en tiempo de ejecución, según la cantidad de filas que se encuentren realmente en comparación con el umbral adaptable.
El Concat Las alternativas de operador y hash/apply individuales normalmente no se muestran en el plan de ejecución final. En su lugar, se nos presenta una sola Unión adaptable operador. Esta es solo una decisión de presentación:el Concat y las uniones todavía están presentes en el código ejecutado por el motor de ejecución de SQL Server. Puede encontrar más detalles sobre esto en las secciones Apéndice y Lecturas relacionadas de este artículo.
El Umbral Adaptativo
Por lo general, una aplicación es más barata que una combinación hash para un número menor de filas de conducción. La combinación hash tiene un costo de inicio adicional para construir su tabla hash, pero un costo por fila más bajo cuando comienza a buscar coincidencias.
En general, hay un punto en el que el costo estimado de una combinación de aplicación y hash será igual. Esta idea fue muy bien ilustrada por Joe Sack en su artículo, Introducción de uniones adaptables en modo por lotes:
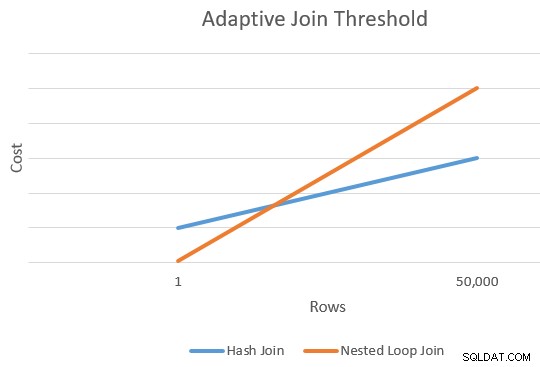
Cálculo del umbral
En este punto, el optimizador tiene una estimación única para la cantidad de filas que ingresan a la entrada de compilación de la unión hash y aplica alternativas. También tiene el costo estimado de los operadores de hash y aplica en su conjunto.
Esto nos da un solo punto en el extremo derecho de las líneas naranja y azul en el diagrama de arriba. El optimizador necesita otro punto de referencia para cada tipo de unión para que pueda "dibujar las líneas" y encontrar la intersección (no dibuja líneas literalmente, pero se entiende la idea).
Para encontrar un segundo punto para las líneas, el optimizador solicita a las dos uniones que produzcan una nueva estimación de costos basada en una cardinalidad de entrada diferente (e hipotética). Si la primera estimación de cardinalidad fue de más de 100 filas, pide a las uniones que estimen nuevos costos para una fila. Si la cardinalidad original era menor o igual a 100 filas, el segundo punto se basa en una cardinalidad de entrada de 10 000 filas (por lo que hay un rango lo suficientemente decente para extrapolar).
En cualquier caso, el resultado son dos costes y recuentos de filas diferentes para cada tipo de unión, lo que permite "dibujar" las líneas.
La fórmula de la intersección
Encontrar la intersección de dos líneas con base en dos puntos para cada línea es un problema con varias soluciones conocidas. SQL Server usa uno basado en determinantes como se describe en Wikipedia:
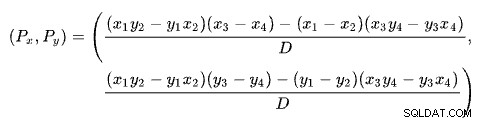
donde:
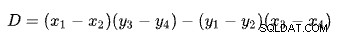
La primera línea está definida por los puntos (x1 , y1 ) y (x2 , y2 ). La segunda línea está dada por los puntos (x3 , y3 ) y (x4 , y4 ). La intersección está en (Px , Py ).
Nuestro esquema tiene el número de filas en el eje x y el costo estimado en el eje y. Estamos interesados en el número de filas donde se cruzan las líneas. Esto viene dado por la fórmula para Px . Si quisiéramos saber el costo estimado en la intersección, sería Py .
Para Px filas, los costos estimados de las soluciones apply y hash join serían iguales. Este es el umbral de adaptación que necesitamos.
Un ejemplo resuelto
Aquí hay un ejemplo que usa la base de datos de muestra AdventureWorks2017 y el siguiente truco de indexación de Itzik Ben-Gan para obtener una consideración incondicional de la ejecución en modo por lotes:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123; El plan de ejecución muestra una unión adaptable con un umbral de 1502,07 filas:
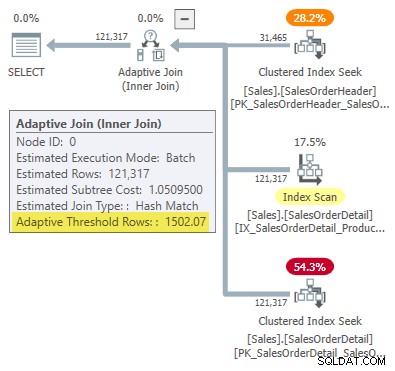
El número estimado de filas que impulsan la combinación adaptable es 31 465 .
Costos de unión
En este caso simplificado, podemos encontrar costos estimados de subárboles para el hash y aplicar alternativas de combinación usando sugerencias:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
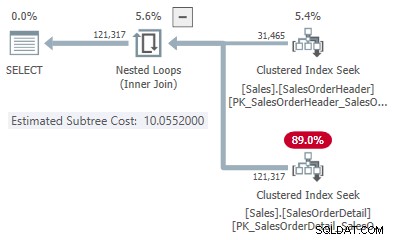
Esto nos da un punto en la línea para cada tipo de unión:
- 31 465 filas
- Costo de hash 1.05083
- Aplicar costo 10.0552
El segundo punto de la recta
Dado que el número estimado de filas es superior a 100, los segundos puntos de referencia provienen de estimaciones internas especiales basadas en una fila de entrada de combinación. Desafortunadamente, no hay una manera fácil de obtener los números de costo exactos para este cálculo interno (hablaré más sobre esto en breve).
Por ahora, solo le mostraré las cifras de costos (usando la precisión interna completa en lugar de las seis cifras significativas que se presentan en los planes de ejecución):
- Una fila (cálculo interno)
- Costo de hash 0,999027422729
- Aplicar costo 0.547927305023
- 31 465 filas
- Costo de hash 1.05082787359
- Aplicar costo 10.0552890166
Como era de esperar, la unión de aplicación es más económica que el hash para una cardinalidad de entrada pequeña, pero mucho más costosa para la cardinalidad esperada de 31 465 filas.
El cálculo de la intersección
Al conectar estos números de cardinalidad y costo en la fórmula de intersección de líneas, se obtiene lo siguiente:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Redondeado a seis cifras significativas, este resultado coincide con 1502,07 filas que se muestran en el plan de ejecución de unión adaptable:
¿Defecto o diseño?
Recuerde, SQL Server necesita cuatro puntos para "dibujar" el recuento de filas frente a las líneas de costo para encontrar el umbral de combinación adaptable. En el presente caso, esto significa encontrar estimaciones de costos para las cardinalidades de una fila y de 31 465 filas para las implementaciones de combinación de hash y de aplicación.
El optimizador llama a una rutina llamada sqllang!CuNewJoinEstimate para calcular estos cuatro costos para una unión adaptable. Lamentablemente, no hay marcas de rastreo ni eventos extendidos para proporcionar una descripción general útil de esta actividad. Las marcas de rastreo normales utilizadas para investigar el comportamiento del optimizador y mostrar los costos no funcionan aquí (consulte el Apéndice si está interesado en obtener más detalles).
La única forma de obtener las estimaciones de costos de una fila es adjuntar un depurador y establecer un punto de interrupción después de la cuarta llamada a CuNewJoinEstimate en el código de sqllang!CardSolveForSwitch . Usé WinDbg para obtener esta pila de llamadas en SQL Server 2019 CU12:

En este punto del código, los costos de puntos flotantes de doble precisión se almacenan en cuatro ubicaciones de memoria a las que apuntan las direcciones en rsp+b0 , rsp+d0 , rsp+30 y rsp+28 (donde rsp es un registro de CPU y las compensaciones están en hexadecimal):

Los números de costo del subárbol de operadores que se muestran coinciden con los utilizados en la fórmula de cálculo del umbral de combinación adaptativa.
Acerca de esas estimaciones de costos de una fila
Es posible que haya notado que los costos estimados del subárbol para las uniones de una fila parecen bastante altos para la cantidad de trabajo que implica unir una fila:
- Una fila
- Costo de hash 0,999027422729
- Aplicar costo 0.547927305023
Si intenta producir planes de ejecución de entrada de una fila para la unión hash y aplica ejemplos, verá mucho costos de subárbol estimados más bajos en la unión que los que se muestran arriba. Del mismo modo, ejecutar la consulta original con un objetivo de fila de uno (o el número de filas de salida de unión esperadas para una entrada de una fila) también generará un costo estimado way inferior al que se muestra.
El motivo es CuNewJoinEstimate la rutina estima la una fila caso de una manera que creo que la mayoría de la gente no encontraría intuitiva.
El costo final se compone de tres componentes principales:
- El costo del subárbol de entrada de compilación
- El costo local de la unión
- El costo del subárbol de entrada de la sonda
Los elementos 2 y 3 dependen del tipo de unión. Para una combinación hash, representan el costo de leer todas las filas de la entrada de la sonda, emparejarlas (o no) con una fila en la tabla hash y pasar los resultados al siguiente operador. Para una aplicación, los costos cubren una búsqueda en la entrada inferior de la combinación, el costo interno de la combinación en sí y la devolución de las filas coincidentes al operador principal.
Nada de esto es inusual o sorprendente.
La sorpresa del costo
La sorpresa viene del lado de la construcción de la unión (elemento 1 de la lista). Uno podría esperar que el optimizador hiciera un cálculo elaborado para escalar el costo del subárbol ya calculado para 31 465 filas a una fila promedio, o algo así.
De hecho, tanto las estimaciones de combinación de hash como las de aplicación de una fila simplemente usan el costo completo del subárbol para el original estimación de cardinalidad de 31.465 filas. En nuestro ejemplo en ejecución, este "subárbol" es 0.54456 costo de la búsqueda de índice agrupado en modo por lotes en la tabla de encabezado:
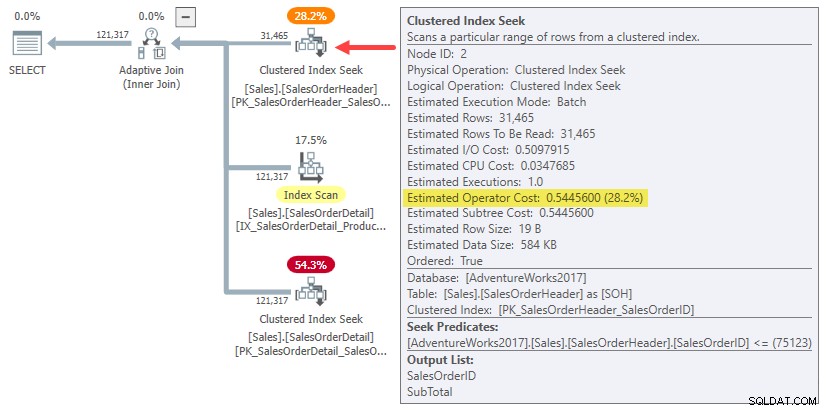
Para ser claros:los costos estimados del lado de la construcción para las alternativas de unión de una fila usan un costo de entrada calculado para 31,465 filas. Eso debería parecerte un poco extraño.
Como recordatorio, los costes de una fila calculados por CuNewJoinEstimate fueron los siguientes:
- Una fila
- Costo de hash 0,999027422729
- Aplicar costo 0.547927305023
Puede ver que el coste total de aplicación (~0,54793) está dominado por 0,54456 costo del subárbol del lado de la construcción, con una pequeña cantidad adicional para la búsqueda del lado interno único, procesando la pequeña cantidad de filas resultantes dentro de la combinación y pasándolas al operador principal.
El costo estimado de la unión hash de una fila es más alto porque el lado de la sonda del plan consiste en un escaneo de índice completo, donde todas las filas resultantes deben pasar por la unión. El costo total de la combinación hash de una fila es un poco más bajo que el costo original de 1.05095 para el ejemplo de 31 465 filas porque ahora solo hay una fila en la tabla hash.
Implicaciones
Uno esperaría que una estimación de combinación de una fila se basara, en parte, en el costo de entregar una fila a la entrada de combinación impulsora. Como hemos visto, este no es el caso de una unión adaptable:tanto las alternativas de aplicación como las de hash están cargadas con el costo total estimado para 31,465 filas. El resto de la unión tiene un costo similar al que cabría esperar para una entrada de compilación de una fila.
Este arreglo intuitivamente extraño es la razón por la cual es difícil (quizás imposible) mostrar un plan de ejecución que refleje los costos calculados. Necesitaríamos construir un plan que entregue 31,465 filas a la entrada de combinación superior pero costando la combinación en sí y su entrada interna como si solo hubiera una fila presente. Una pregunta difícil.
El efecto de todo esto es elevar el punto más a la izquierda en nuestro diagrama de líneas que se cruzan hacia arriba en el eje y. Esto afecta la pendiente de la línea y por lo tanto el punto de intersección.
Otro efecto práctico es que el umbral de combinación adaptable calculado ahora depende de la estimación de cardinalidad original en la entrada de compilación de hash, como señaló Joe Obbish en su publicación de blog de 2017. Por ejemplo, si cambiamos el WHERE cláusula en la consulta de prueba a SOH.SalesOrderID <= 55000 , el umbral adaptativo reduce de 1502.07 a 1259.8 sin cambiar el hash del plan de consulta. Mismo plan, umbral diferente.
Esto surge porque, como hemos visto, la estimación del costo interno de una fila depende del costo de entrada de construcción para la estimación de cardinalidad original. Esto significa que diferentes estimaciones iniciales del lado de la construcción darán un "impulso" diferente en el eje y a la estimación de una fila. A su vez, la línea tendrá una pendiente diferente y un punto de intersección diferente.
La intuición sugeriría que la estimación de una fila para la misma unión siempre debería dar el mismo valor, independientemente de la otra estimación de cardinalidad en la línea (dada exactamente la misma unión con las mismas propiedades y tamaños de fila, tiene una relación casi lineal entre conducir filas y costo). Este no es el caso de una unión adaptable.
¿Por diseño?
Puedo decirle con cierta confianza qué hace SQL Server al calcular el umbral de unión adaptable. No tengo ninguna idea especial sobre por qué lo hace de esta manera.
Aún así, hay algunas razones para pensar que este arreglo es deliberado y se produjo después de la debida consideración y retroalimentación de las pruebas. El resto de esta sección cubre algunos de mis pensamientos sobre este aspecto.
Una unión adaptable no es una elección directa entre una aplicación normal y una unión hash en modo por lotes. Una unión adaptable siempre comienza llenando completamente la tabla hash. Solo una vez que se completa este trabajo, se toma la decisión de cambiar a una implementación de aplicación o no.
En este momento, ya hemos incurrido en costos potencialmente significativos al completar y particionar la unión hash en la memoria. Esto puede no importar mucho para el caso de una fila, pero se vuelve progresivamente más importante a medida que aumenta la cardinalidad. El "impulso" inesperado puede ser una forma de incorporar estas realidades en el cálculo manteniendo un costo de cálculo razonable.
El modelo de costos de SQL Server ha estado durante mucho tiempo un poco sesgado contra la unión de bucles anidados, posiblemente con alguna justificación. Incluso el caso ideal de aplicación indexada puede ser lento en la práctica si los datos necesarios aún no están en la memoria y el subsistema de E/S no es flash, especialmente con un patrón de acceso algo aleatorio. Las cantidades limitadas de memoria y las E/S lentas no serán del todo desconocidas para los usuarios de motores de base de datos basados en la nube de gama baja, por ejemplo.
Es posible que las pruebas prácticas en dichos entornos revelaran que una unión adaptable con costos intuitivos fue demasiado rápida para la transición a una aplicación. A veces, la teoría solo es buena en teoría.
Aún así, la situación actual no es la ideal; almacenar en caché un plan basado en una estimación de cardinalidad inusualmente baja producirá una unión adaptable mucho más renuente a cambiar a una aplicación de lo que habría sido con una estimación inicial más grande. Esta es una variedad del problema de la sensibilidad de los parámetros, pero será una nueva consideración de este tipo para muchos de nosotros.
Ahora, también es posible usar el costo del subárbol de entrada de construcción completo para el punto más a la izquierda de las líneas de costo que se cruzan es simplemente un error o un descuido no corregido. Mi sensación es que la implementación actual es probablemente un compromiso práctico deliberado, pero necesitaría a alguien con acceso a los documentos de diseño y al código fuente para estar seguro.
Resumen
Una combinación adaptable permite que SQL Server haga la transición de una combinación hash en modo por lotes a una aplicación después de que la tabla hash se haya rellenado por completo. Toma esta decisión comparando el número de filas en la tabla hash con un umbral adaptativo precalculado.
El umbral se calcula prediciendo dónde se aplican y los costos de combinación hash son iguales. Para encontrar este punto, SQL Server produce una segunda estimación de costo de unión interna para una cardinalidad de entrada de compilación diferente, normalmente, una fila.
Sorprendentemente, el costo estimado para la estimación de una fila incluye el costo completo del subárbol del lado de la construcción para la estimación de cardinalidad original (no escalada a una fila). Esto significa que el valor del umbral depende de la estimación de cardinalidad original en la entrada de compilación.
En consecuencia, una combinación adaptable puede tener un valor de umbral inesperadamente bajo, lo que significa que es mucho menos probable que la combinación adaptable se aleje de una combinación hash. No está claro si este comportamiento es por diseño.
Lecturas relacionadas
- Presentamos las uniones adaptables en modo por lotes de Joe Sack
- Comprensión de las uniones adaptables en la documentación del producto
- Conceptos internos de unión adaptable por Dima Pilugin
- ¿Cómo funcionan las uniones adaptables en modo por lotes? en Administradores de bases de datos Stack Exchange por Erik Darling
- Una regresión de unión adaptable por Joe Obbish
- Si desea uniones adaptables, necesita índices más amplios y ¿cuánto más grande es mejor? por Erik Darling
- Rastreo de parámetros:uniones adaptables por Brent Ozar
- Preguntas y respuestas sobre el procesamiento inteligente de consultas por Joe Sack
Apéndice
Esta sección cubre un par de aspectos de combinación adaptativa que fueron difíciles de incluir en el texto principal de forma natural.
El Plan de Adaptación Ampliado
Puede intentar mirar una representación visual del plan interno utilizando el indicador de seguimiento no documentado 9415, como lo proporciona Dima Pilugin en su excelente artículo sobre componentes internos de combinación adaptativa vinculado anteriormente. Con esta marca activa, el plan de combinación adaptable para nuestro ejemplo en ejecución se convierte en el siguiente:
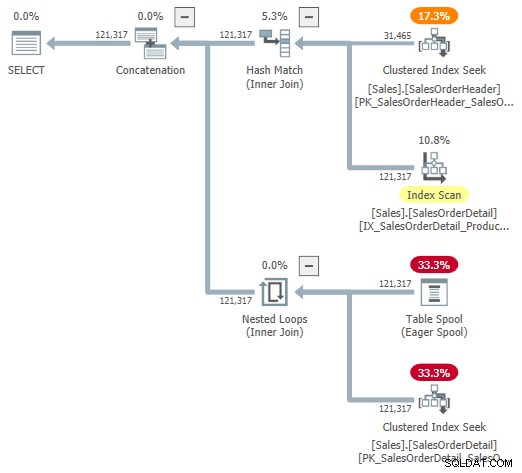
Esta es una representación útil para ayudar a comprender, pero no es del todo precisa, completa o consistente. Por ejemplo, Table Spool no existe; es una representación predeterminada para el lector de búfer adaptativo. leyendo filas directamente de la tabla hash del modo por lotes.
Las propiedades del operador y las estimaciones de cardinalidad también están un poco por todas partes. La salida del lector de búfer adaptativo ("spool") debe ser de 31 465 filas, no de 121 317. El costo del subárbol de la aplicación está incorrectamente limitado por el costo del operador principal. Esto es normal para el plan de presentación, pero no tiene sentido en un contexto de unión adaptable.
También hay otras inconsistencias, demasiadas para enumerarlas de manera útil, pero eso puede ocurrir con marcas de rastreo no documentadas. El plan ampliado que se muestra arriba no está diseñado para que lo usen los usuarios finales, por lo que tal vez no sea del todo sorprendente. El mensaje aquí es no confiar demasiado en los números y las propiedades que se muestran en este formulario no documentado.
También debo mencionar de paso que el operador del plan de unión adaptable estándar terminado no está completamente libre de sus propios problemas de coherencia. Estos se derivan casi exclusivamente de los detalles ocultos.
Por ejemplo, las propiedades de combinación adaptable que se muestran provienen de una combinación de Concat subyacente. , Unión hash y Aplicar operadores. Puede ver una combinación adaptable que informa la ejecución del modo por lotes para la combinación de bucles anidados (lo cual es imposible), y el tiempo transcurrido que se muestra en realidad se copia del Concat oculto. , no la combinación particular que se ejecutó en tiempo de ejecución.
Los sospechosos habituales
Nosotros podemos Obtenga información útil de los tipos de marcas de rastreo no documentadas que normalmente se usan para ver la salida del optimizador. Por ejemplo:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Salida (muy editada para mejorar la legibilidad):
*** Árbol de salida:***PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Cost=1.05095
- PhyOp_Concat (lote) Tarjeta=121317 Costo=1.05325
- PhyOp_HashJoinx_jtInner (lote) Tarjeta=121317 Costo=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Costo=0.54456
- PhyOp_Filter(lote) Tarjeta=121317 Costo=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Costo=0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Costo=10.0798
- PhyOp_Apply Card=121317 Costo=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Tarjeta=31465 Costo=0.544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Costo=0.54456 [** 3 **]
- PhyOp_Filter Card=3.85562 Costo=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 Costo=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Tarjeta=31465 Costo=0.544623
- PhyOp_Apply Card=121317 Costo=10,0553
Esto brinda una idea de los costos estimados para el caso de cardinalidad total con hash y aplica alternativas sin escribir consultas separadas y usar sugerencias. Como se menciona en el texto principal, estas marcas de rastreo no son efectivas dentro de CuNewJoinEstimate , por lo que no podemos ver directamente los cálculos repetidos para el caso de 31 465 filas ni ninguno de los detalles de las estimaciones de una fila de esta manera.
Unión combinada y combinación hash en modo fila
Las uniones adaptables solo ofrecen una transición de la unión hash del modo por lotes al modo de fila. Para conocer los motivos por los que no se admite la unión hash en modo fila, consulte las preguntas y respuestas sobre el procesamiento inteligente de consultas en la sección Lecturas relacionadas. En resumen, se cree que las uniones hash en modo fila serían demasiado propensas a las regresiones de rendimiento.
Cambiar a un modo de fila unión por fusión sería otra opción, pero el optimizador no considera esto actualmente. Según tengo entendido, es poco probable que se amplíe en esta dirección en el futuro.
Algunas de las consideraciones son las mismas que para la unión hash en modo fila. Además, los planes de combinación de combinación tienden a ser menos intercambiables con la combinación hash, incluso si nos limitamos a la combinación de combinación indexada (sin clasificación explícita).
También hay una distinción mucho mayor entre hash y apply que entre hash y merge. Tanto hash como merge son adecuados para entradas más grandes, y apply se adapta mejor a una entrada de conducción más pequeña. La combinación de combinación no se paraleliza tan fácilmente como la combinación hash y no se escala tan bien con el aumento de la cantidad de subprocesos.
Dado que la motivación para las uniones adaptables es hacer frente mejor a significativamente tamaños de entrada variables, y solo la unión hash admite el procesamiento en modo por lotes, la elección de hash por lotes versus aplicación de fila es la más natural. Por último, tener tres opciones de combinación adaptativa complicaría significativamente el cálculo del umbral para una ganancia potencialmente pequeña.